本文主要是介绍Optimising a 3D convolutional neural network for head and neck computed tomography segmentation with,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Optimising a 3D convolutional neural network for head and neck computed
tomography segmentation with limited training data
发表期刊:Physics and Imaging in Radiation Oncology
发表时间:2022年
Abstract
Background and purpose: 卷积神经网络 (CNN) 越来越多地用于放射治疗计划的自动分割,其中危险器官 (OAR) 的准确分割至关重要。训练 CNN 通常需要大量数据。然而,大型、高质量的数据集是稀缺的。本研究的目的是开发一种 CNN,该 CNN 能够使用小型训练数据集(34 个 CT)对计划 CT 扫描进行准确的头颈部 (HN) 3D 自动分割。
Materials and Method: 我们定制的 CNN 架构的元素各不相同,以优化分割性能。我们测试并评估了以下影响:在特定软组织和骨骼解剖窗口处为 CT 扫描输入使用多个对比通道,调整大小与转置卷积,以及基于重叠度量和不同组合的交叉熵的损失函数。使用第 95 个百分位 Hausdorff 距离和平均协议距离 (mDTA) 将模型分割性能与两位医生的黄金标准分割的观察者间偏差进行比较。在流行的公共数据集上进一步验证了性能最佳的配置,以与最先进的 (SOTA) 自动分割方法进行比较。
Results: 当在公共数据集上评估时,我们表现最好的 CNN 配置与当前的 SOTA 方法具有竞争力,脑干 mDTA 为 (0.81 ± 0.31) mm,下颌骨为 (0.20 ± 0.08) mm,左侧腮腺为 (0.77 ± 0.14) mm右侧腮腺为 (0.81 ± 0.28) mm。
** Conclusions:** 通过仔细调整和定制,我们用一个小数据集训练了一个 3D CNN,以产生 HN OAR 的分割,其准确性与临床间偏差相当。我们提出的模型与当前的 SOTA 方法具有竞争力。
Introduction
危险器官 (OAR) 的 3D 分割是放射治疗路径中的关键步骤。然而,临床医生的分割或描绘是缓慢的、昂贵的并且即使在经验丰富的放射肿瘤学家中也容易出现观察者之间和观察者内部的差异[1]。全卷积神经网络 (CNN) 现在是自动医学图像分割的最先进技术 [2]。最近,已经提出并实施了相当多的方法来更快地执行分割并具有更高的一致性[3-7]。尖端放射治疗工作流程使用自动分割模型来建议轮廓,经验丰富的放射技师将根据需要进行确认和编辑 [8]。
CNN 模型的监督训练传统上需要大量高质量的注释数据(通常 > 1000 个示例)[9]。在这个应用程序中,放射技师需要对每张图像进行完整的体积分割,最好是具有相同的专业水平并遵循相同的指导方针。因此,用于自动分割的高质量训练数据集的大小通常是有限的。大型机构和商业系统经常使用包含 100 张图像的数据集 [10,11]。然而,很少有研究人员能够访问如此庞大的数据集。对于 2D 任务,当可用的训练数据有限时,通常使用大型预训练骨干模型(如 ResNet)的迁移学习来提高性能。类似的骨干模型还不容易以 3D 形式访问。
本研究旨在开发一个定制的 3D CNN 模型,该模型能够使用小型公开数据集 (34 CT) 进行准确的头颈部 (HN) OAR 自动分割以进行训练。 CNN 模型的设计空间非常广泛,除了可用的训练数据量外,CNN 架构和训练协议的选择也会严重影响模型性能。我们选择了三个关键设计元素来优化定制 CNN 的开发。
Materials and methods
CNN model architecture
我们的基础分割 CNN 基于 3D UNet 设计 [12]。这包括重复零填充 3x3x3 卷积和池化层的编码路径,然后是类似卷积和上采样的解码路径(图 1)。添加了残差的跳跃连接以平滑训练过程。这些残差连接是用 1x1x1 卷积层实现的,以匹配卷积块 [13] 两侧的通道数。在网络解码部分的每一层都引入了多级深度监督,以加速收敛。深度监督连接包含瓶颈 1x1x1 卷积,减少了模型参数的数量并支持在单个图形处理单元 (GPU) 上进行训练。
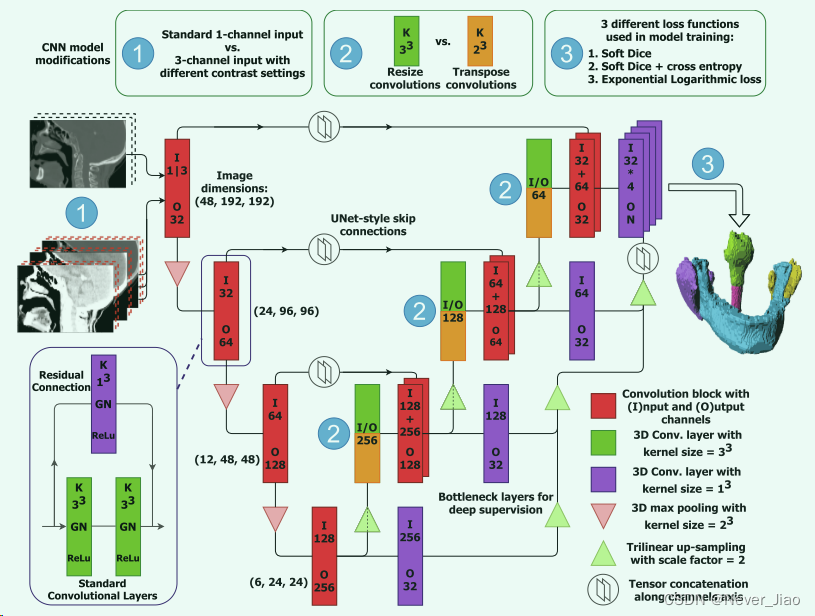
Fig.1 本研究中使用的 CNN 架构。使用的基本模型是具有深度监督的 3D Res-UNet。在此图中,我们突出显示了构成所呈现实验的三个修改。我们比较了对模型输入 (1) 使用多个对比度设置、在解码器部分 (2) 中调整大小或转置卷积以及三个不同的损失函数 (3)。当使用转置卷积(橙色)时,我们没有执行三线性上采样。
Multiple input channels with specific contrast settings
通常,图像在用作 CNN 的输入之前会进行预处理。常规预处理包括标准化图像以使 μ = 0 和 σ = 1 或将图像映射到范围 [0,1]。
使用计算机断层扫描 (CT) 扫描的一个优点是,体素强度被校准为 Hounsfield 单位 (HU),这是一种在空气 (-1024 HU) 和水 (0 HU) 下具有固定参考值的组织密度标度。临床医生在可视化 CT 图像时使用窗口或灰度映射来增强不同组织的对比度并突出特定结构,例如,窄窗口用于具有相似衰减的软组织,而宽窗口用于可视化骨骼。图像亮度随窗口水平 (L) 调整,对比度随窗口宽度 (W) 调整。
L 和 W 定义了一个斜坡函数,用于映射给定图像中的所有强度,如图 2 所示。我们提出的方法使用三个输入通道,并使用不同的对比度设置进行归一化。放射科医生使用所选的 W 和 L 对比度设置来专门查看软组织、骨骼解剖结构和脑组织 [14]。三个明显对比的 CT 体积沿“通道”轴连接并同时通过 CNN 馈送。这种方法类似于在 2D 自然图像中分离 RGB 通道。
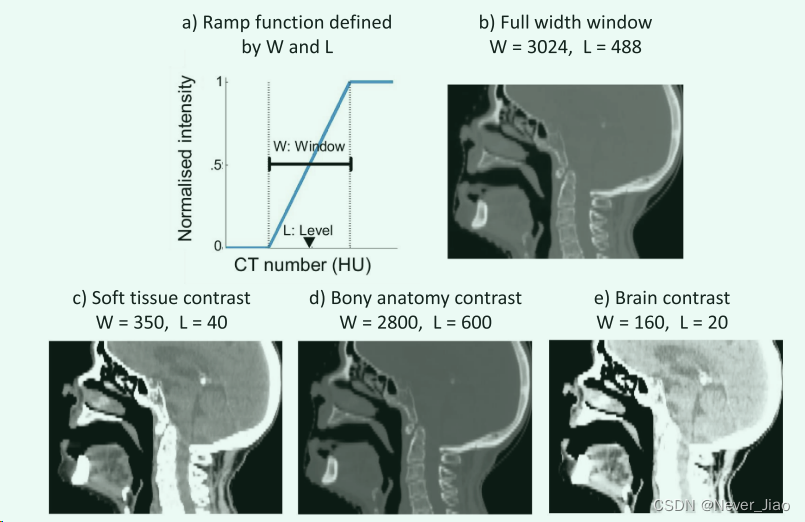
Fig.2 a) 用于映射 CT 图像强度的窗口斜坡函数。 b) 全宽窗口基线方法的对比度设置。 c-e) 为我们的多输入通道方法选择的窗口宽度和水平对比度设置。
我们将我们提出的方法与使用单个输入通道的比较基线进行了比较,其中 CT 图像使用全宽窗口进行归一化。实际上,这涉及设置 L = 488 和 W = 3024,将图像的整个强度范围标准化为范围 [0, 1]
Resize convolutions
转置卷积经常用于模拟逆卷积操作,通过扩大输入来增加图像的空间维度 [15]。然而,转置卷积可以在 CNN 生成的图像中产生棋盘伪像 [16]。调整大小卷积(上采样后跟标准卷积层)已被提议作为一种替代方法来修复此类伪影。我们在分割 CNN 的解码器部分使用传统转置和调整卷积来比较模型配置。在这项工作中,3D 调整大小卷积是在零填充 3x3x3 卷积层之前使用三线性上采样实现的。
当使用多个输入通道(4、896、693→4、897、621 个参数)时,CNN 模型大小的增加可以忽略不计。调整大小卷积使用 3x3x3 内核,与使用 2x2x2 内核(4、896、693→6、530、997 参数)的转置卷积相比,它增加了更多参数。使用三个输入通道和调整卷积大小的模型配置包含 6、531、925 个参数(这些参数量是怎么计算的?)。
Loss function
我们用三个损失函数进行了实验:一个简单的重叠度量;重叠度量和交叉熵的线性组合;以及添加了非线性的类似组合。
在分割任务中,重叠损失度量因其易于实现和快速收敛而受到欢迎。我们评估的第一个指标是基于Dice相似系数 (DSC) 的多类加权Soft Dice (wSD) 损失函数。 wSD 损失由下式给出
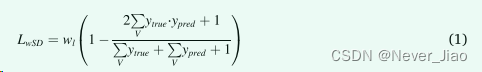
其中 V 是 CT 体积,l 是 OAR 标签。在 3D 体积中,背景和标记的体素之间通常存在显着的类别不平衡,可以达到几个数量级,尤其是对于小型 OAR。通常添加 OAR 特定的权重 wl 以解决类别不平衡问题。在这项研究中,每个 OAR 的权重是用反向标签频率计算的:

其中,α=1/3。
交叉熵 (XE) 是一种流行的损失函数,它使用对数概率评估目标和预测的相似性。实施的第二个度量由 wSD 和加权 XE (wSD + XE) 的线性组合组成。
黄等人提出了一种“指数对数损失”函数(ExpLogLoss),用于分割具有高不平衡对象大小的对象。该损失函数最初是为分割 3D 大脑 MR 图像而设计的,由对数 SD 和加权 XE 之和构成。我们使用 [17] 中概述的建议设置评估了使用 ExpLogLoss 函数的影响。 ExpLogLoss 函数计算为
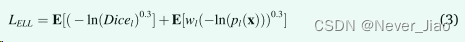
其中 Dicel 是 OAR l 的 Dice 相似系数,-ln(pl(x)) 是负对数似然损失,wl 的 α = 0.5。
Implementation details
我们所有的模型都是在 PyTorch 1.6.0 中实现的。所有网络训练均在 16 GB NVidia Tesla V100 GPU 上进行。个人模型训练耗时约 5 小时。每个 3D CT 图像的分割推断时间 <1 秒。
广泛的数据增强被用来提高模型的鲁棒性。在使用小型训练数据集时,这对于防止过度拟合至关重要。在整个训练过程中,原始 CT 图像和黄金标准分割掩膜被随机的增强序列转换。 3D 增强操作包括:横向镜像(概率,p = 0.5);每个方向最大偏移 ±4 体素(p = 1,平面内 ±4 毫米和轴向 ±10 毫米); ±10° 之间的旋转以模拟颈椎屈曲、伸展和旋转 (p = 0.75);和 90-110% 之间的体积缩放 (p = 0.5)。所有的增强都是使用 numpy 和 scipy 库实现的。
使用 Adam 优化器时,初始学习率为 10-2,每次验证损失达到 100 个 epoch 时,学习率就会降低 10 倍。允许模型训练多达 1000 个 epoch,如果验证损失在 250 个 epoch 内没有得到改善,则实施提前停止。由于 3D CNN 和输入 CT 体积的大小,批量大小被限制为一个。然而,梯度累积(什么是梯度累积?)被用来延迟模型参数更新,这模拟了 4 个批量大小。
Data and experimental setups
对于模型开发,我们使用了包含 34 张 CT 图像的公开可用的开放数据集 (https://github.com/deepmind/tcia-ct-scan-dataset) [11]。 34 张 HN CT 中的每张都具有 1x1x2.5 毫米的体素分辨率,有两位医生的 OAR 轮廓。一组描述被视为黄金标准并用于培训。 CNN 模型被训练用于下颌骨、脑干、腮腺和脊髓颈段的 3D 分割。我们进行了实验来评估三个损失函数的每个配置,多通道对比度输入对比单通道对比度输入和调整大小与转置卷积。在分割之前,使用内部软件 [18] 将 CT 自动裁剪为具有200x200x56 体素尺寸的解剖学一致的子体积。
对每个模型配置进行了 5 折交叉验证 [19]。在每一折中,使用 24 个训练图像和 3 个验证图像从头开始训练一个 CNN 模型。在这样的交叉验证中,训练数据用于调整模型参数,而验证数据通知学习率的调整以及何时终止训练过程。保留了 7 组测试图像并用于评估交叉验证的最终分割性能。
Segmentation performance metrics
使用第 95 个百分位 Hausdorff 距离 (HD95) 和平均协议距离 (mDTA) 将模型分割性能与两位医生之间的测量偏差进行比较。对每个 OAR 执行第二临床医生和 CNN HD95 样本的 Wilcoxon 符号秩检验,零假设中位数的差异为零。
重叠指标(例如 DSC 和 Jaccard 索引)经常被报告用于语义分割工作。然而,这些指标严重偏向于结构体积,对细节不敏感,因为体积重叠可以隐藏结构边界之间的临床相关差异 [3,20]。在放射治疗中,分割边界的微小偏差可能会产生潜在的严重影响,例如通过对 OAR 进行计划外照射会增加患者出现副作用的风险。
因此,距离度量,如 mDTA 和 HD95 [21],是首选 [22] 并在本文中报告。为了计算这些指标,为参考分割创建距离变换图,并在评估分割边界上的体素上进行采样。我们对称地评估了这些距离,即使用黄金标准的距离图并在预测分割的边界体素上采样,反之亦然。然后将这些距离通过它们的平均值 (mDTA) 和它们的第 95 个百分位最大距离 (HD95) 进行汇总。 mDTA 用于评估整体结果,HD95 是最差匹配区域。
External validation
我们的最佳模型配置在公开的 MICCAI 头颈自动分割挑战 2015 数据集(版本 1.4.1)[23] 上得到了进一步验证。该数据集(MICCAI’15 集)包含 48 名患者,最初分为:培训 25 个,可选附加培训 8 个,场外测试 10 个,现场测试 5 个。我们使用 25 个用于训练的原始集合、5 个用于验证的现场测试图像和 10 个用于测试的非现场测试图像重新训练了我们的最佳配置模型。原始“可选训练”集中的 8 个样本没有描述所有的 OAR,因此不包括在内。不幸的是,这个数据集不包含脊髓轮廓。
我们提出的模型在 MICCAI’15 集上的结果与 Huang 等人[4],张等人 [5],高等人[6],郭等人[7] 和川原等人[27]在同一数据集上发布的最先进 (SOTA) 结果进行了比较。 每种比较方法都发布了相当于 mDTA 的 HD95、平均表面距离 (ASD),或者两者都不发布。然而,所有五项研究都发表了 DSC 结果,因此我们在 MICCAI’15 集上额外计算了我们模型的 DSC 结果以进行比较。
Results
Model development
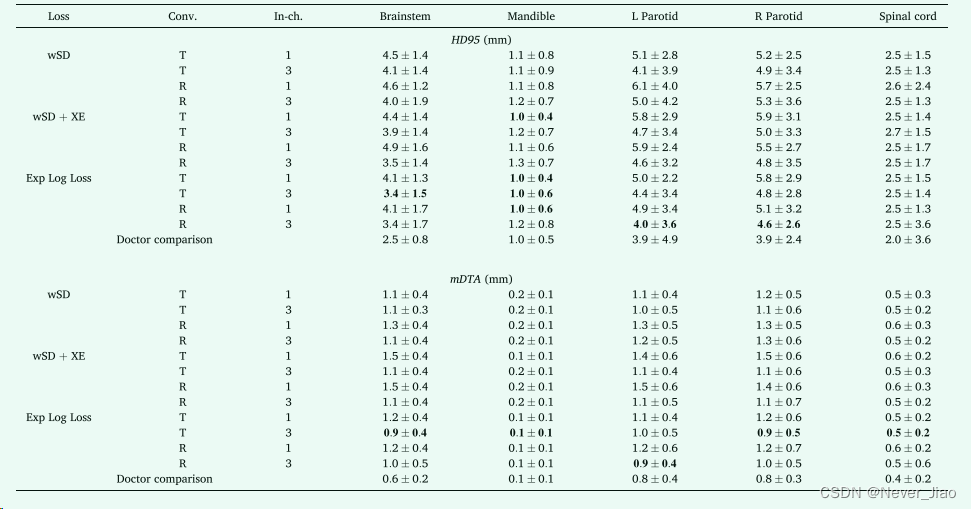
每种模型配置的 HD95 和 mDTA 指标的描述性结果如表 1 所示。
Table1. 每个模型配置的 HD95 和 meanDTA 指标的中值。较低的值表明 CNN 预测的分割与黄金标准之间的一致性更密切。在该表中,T 和 R 分别表示在解码器部分使用转置或调整大小卷积的模型。这些结果由五个测试集折叠中所有患者的每个 OAR 指标的中位数和标准差进行总结。每个 OAR 的最佳性能配置以粗体突出显示,并使用比所示更多的有效数字确定。对于 HD95,大部分脊髓结果反映了 CT 图像切片厚度 (2.50 mm)。这表明大多数模型在脊髓长度上都出现了单个切片的误差。使用 ExpLogLoss 函数训练的模型配置始终产生更好的分割。
为了更仔细地检查使用 ExpLogLoss 函数训练的模型,我们使用图 3 中的箱线图比较了所有此类模型配置的 mDTA 值。性能最佳的模型配置使用多个输入通道、转置卷积并使用 ExpLogLoss 函数进行训练.这种配置产生的腮腺、脊髓和下颌骨分割具有与临床医师间偏差相似的准确度水平。发现脑干的唯一显着差异(p = 0.00008,Wilcoxon 符号秩检验)。然而,脑干的分割性能仍然很好,中位 HD95 为 (3.37 ± 1.50) mm,中位 mDTA 为 (0.95 ± 0.37) mm。
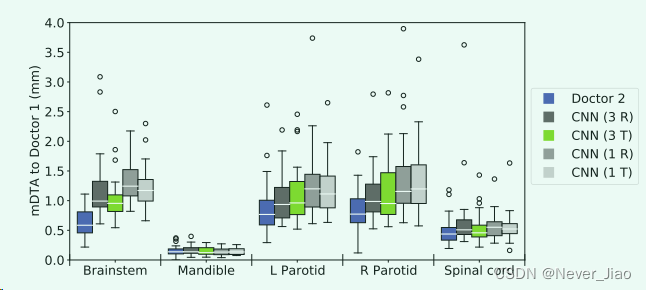
Fig.3 箱线图比较了使用性能最佳的损失函数 ExpLogLoss 训练的四种模型配置的 mDTA,以及医生之间的偏差以供参考(蓝色框)。对于该图,较低的值表示更好的分割。在所有软组织 OAR 中,使用 3 通道输入 (3 R&T) 的配置优于单通道对应配置 (1 R&T)。具有传统转置卷积 (T) 的模型产生的分割效果略好,表现最佳的模型以绿色突出显示。
具有多个输入对比通道的模型配置在软组织器官(脑干、腮腺和脊髓)的分割性能方面始终优于单输入通道对应度。无论输入类型如何,下颌骨的分割性能都是相同的。
当使用 wSD 和 wSD + XE 组合损失函数进行训练时,转置和调整大小卷积的表现非常相似。然而,当使用 ExpLogLoss 函数进行训练时,转置卷积的性能稍微好一些。
External validation
我们表现最好的模型配置(三通道输入、转置卷积和 ExpLogLoss 函数)然后在 MICCAI’15 集上重新训练和评估。在表 2 中,我们总结了我们提出的方法的 HD95、mDTA 和 DSC 度量结果。
Table2. MICCAI’15 数据集上的 HD95、ASD/mDTA 和 DSC 比较结果。粗体字表示性能最佳的模型。破折号表示未报告 OAR 的结果。 *川原等人报告了腮腺的单个 DSC。

在图 4 中,我们说明了由我们提出的方法产生的示例分割。图 4a 和 4b 显示了来自我们原始数据集的患者的 2D 轴向和矢状切片。图 4c 和 4d 是用于外部验证的 MICCAI’15 集中患者的示例。
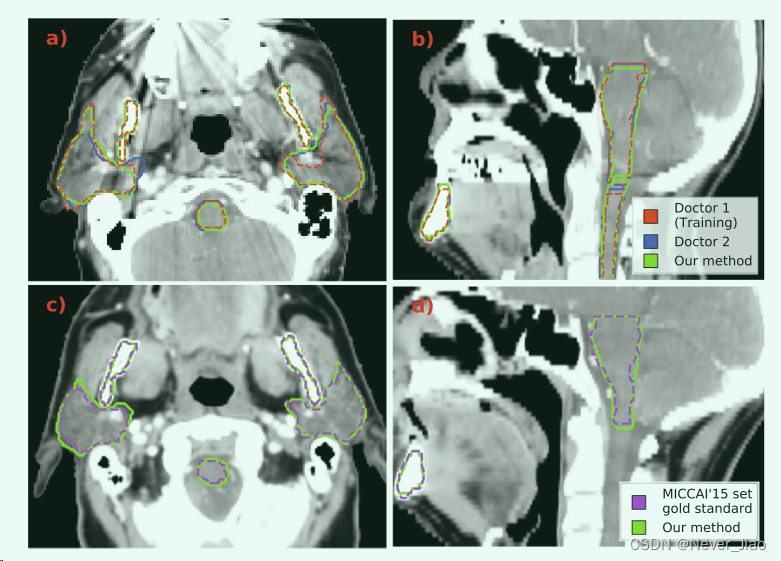
Fig.4 我们的 CNN 模型生成的示例分割(绿色)。在第一行 a) 和 b) 中,我们显示了来自我们用于模型开发的数据集的患者的 2D 轴向和矢状视图。该数据集包含由两位医生生成的分割,显示为红色和蓝色。在底行 c) 和 d) 中,我们展示了来自 MICCAI’15 组的患者的轴向和矢状 2D 切片。该集合的黄金标准分割以紫色显示。
Discussion
现在用于放射治疗计划中的自动分割的 CNN 通常需要大型数据集才能有效训练。我们开发了一个 CNN 模型,当在一个小数据集上进行训练时,该模型能够进行准确的 HN CT 分割。这是通过仔细调整定制的 3D CNN 来实现的。改变我们模型的特定元素可以深入了解影响 CNN 自动分割方法性能的因素,特别是基于 UNet 的架构。
对模型输入使用多种对比度设置是提高软组织 OAR 分割性能的关键策略。我们使用单个全宽窗口将三个预先选择的对比度通道与基线输入进行了比较。我们没有单独或组合详尽地比较每个对比窗口,因为这会大大增加实验的数量。在某些情况下(例如下颌骨),仅使用我们对比的通道之一可能就足够了。然而,识别这些特定情况给自动分割任务增加了相当大的复杂性,并且使用所有三个通道在训练和推理阶段几乎没有增加计算负载。此外,我们没有优化本研究中使用的对比度设置,而是依赖于文献 [14] 中的值。 2018 年,Lee 等人开发了一个窗口设置优化模块,将对比度归一化作为模型的可学习参数[24]。发现类似的模块是否可以在我们的方法中成功部署会很有趣。
损失函数是训练深度学习模型的关键组成部分。我们找到了最初由 Wong 等人[17]开发的 ExpLogLoss 函数。 与更简单的Soft Dice和交叉熵组合函数相比,产生了更高精度的分割模型。卢等人当应用于 T1 加权 MR 图像中的 3D 中风病变分割时,报告了类似损失函数的一致结果 [25]。在未来的工作中,评估最近引入的“Unified Focal”损失函数将是有意义的,该函数在高度不平衡的类分割中表现良好 [26]。
出乎意料的是,2.3 节中描述的转置卷积的棋盘伪影并没有显着降低分割性能。在已发布的方法中,为了避免这个问题,调整卷积大小已经变得相当普遍。然而,我们提出的方法在使用转置卷积时产生了更好的分割。此外,转置卷积模型的训练速度提高了 15%,因为它包含的参数减少了 160 万。
一旦开发阶段完成,我们的最佳模型配置就会在一个公共数据集上进行评估,该数据集已被用作几种 SOTA 方法的基准。 Huang等人[4],张等人 [5],高等人 [6] 和郭等人[7] 发表的结果。 列于表 2 以供比较。从 MIC CAI’15 数据集的这些比较结果中,我们可以看到我们提出的模型与 SOTA 模型具有竞争力。高等人的模型在 HD95 指标中表现非常好,最适合脑干、左右腮腺。我们的方法在下颌骨的 HD95 指标中表现最好。在 ASD/mDTA 指标中,我们的模型在所有脑干 (0.81 ± 0.31mm)、下颌骨 (0.20 ± 0.08mm)、左侧 (0.77 ± 0.14mm) 和右侧腮腺 (0.81 ± 0.28mm) 方面表现最佳。张等人的方法和高等人DSC 分数结果共享荣誉,但是,所有五种方法的表现都非常接近。外部验证还证实,我们的模型比原始模型开发数据集更广泛适用。阿姆贾德等人最近提出了一个自定义的 HN 自动分割 CNN,它具有与我们的 [28] 类似的 Res-UNet3D 架构。然而,这个模型是用 MIC CAI’15 数据集和 24 次额外的 CT 扫描训练的,所以我们不能将它们的结果包括在表 2 中。
我们的方法专门开发用于利用有限的数据,允许在小型数据集上训练自定义模型以分割不同的 OAR 或根据更新的协议。然后可以将特定协议的模型部署在回顾性建模研究或临床试验等应用中,以提高一致性。本研究的一个自然扩展是进一步评估模型性能如何随着训练集大小的变化而变化。 Siciarz 等人最近探索了这个问题,表明随着训练示例数量的减少,分割性能会下降 [29]。然而,Siciarz 等人考虑的训练样本数量最少仍然几乎是本研究中使用的数据集大小的两倍。
在这项研究中,我们表明,通过仔细调整和定制化,可以使用小型数据集训练 3D CNN,以分割下颌骨、腮腺和脊髓,其准确度与临床医师间偏差的幅度相似。我们在一个流行的公共数据集上评估了我们提出的模型,并产生了在多个指标上与当前最先进的方法相媲美的高质量分割结果。
这篇关于Optimising a 3D convolutional neural network for head and neck computed tomography segmentation with的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!