本文主要是介绍自监督+基于骨架的人体动作识别:Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occ,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文作者:Yifei Chen,Kunyu Peng,Alina Roitberg,David Schneider,Jiaming Zhang,Junwei Zheng,Ruiping Liu,Yufan Chen,Kailun Yang,Rainer Stiefelhagen
作者单位:Karlsruhe Institute of Technology; University of Stuttgart; Hunan University; National Engineering Research Center of Robot Visual Perception and Control Technology
论文链接:http://arxiv.org/abs/2309.12029v1
项目链接:https://github.com/cyfml/OPSTL
内容简介:
1)方向:动作识别
2)应用:自主机器人
3)背景:目前,现有的基于骨架的自监督动作识别方法很少考虑涉及目标遮挡的情况,尽管这种情况在实际应用中具有重要意义。
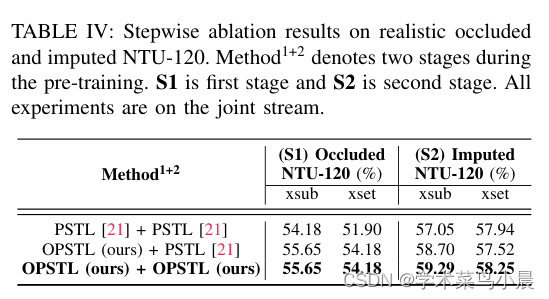
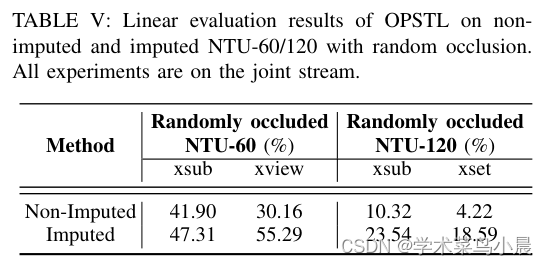
4)方法:本文出了一个简单而有效的方法,首先使用被遮挡的骨架序列进行预训练,然后在序列嵌入上使用k均值聚类(KMeans)将语义上相似的样本分组。接下来,利用K最近邻(KNN)根据最接近的样本邻居填补缺失的骨架数据。通过填补不完整的骨架序列以创建相对完整的输入序列,可为现有基于骨架的自监督模型带来显著的好处。此外,在基于最先进的部分时空学习(PSTL)的基础上,引入了遮挡部分时空学习(OPSTL)框架,该增强使用自适应空间掩蔽(ASM)更好地利用高质量完整的骨架。
5)结果:通过在具有挑战性的遮挡版本NTURGB+D 60和NTURGB+D 120上验证了所提出的填补方法的有效性。源代码将在https://github.com/cyfml/OPSTL 上公开提供。
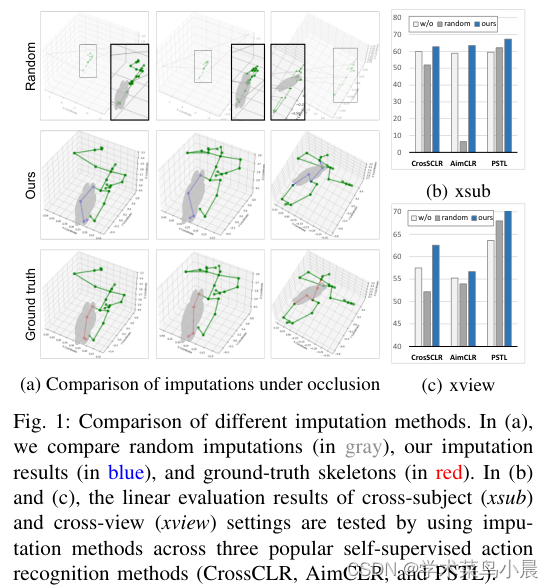
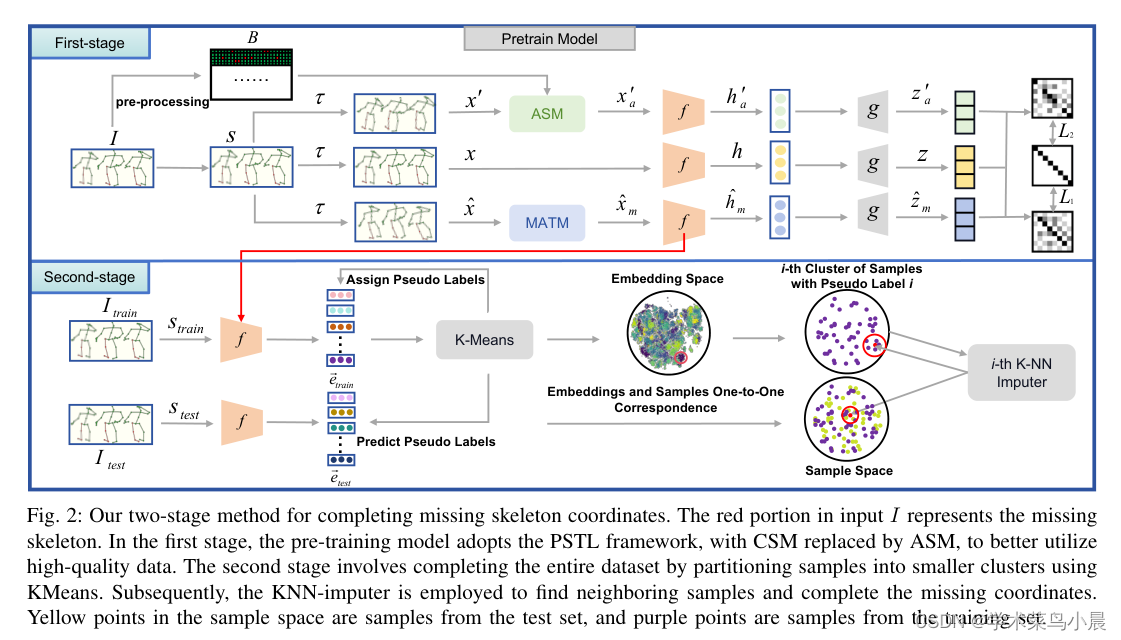
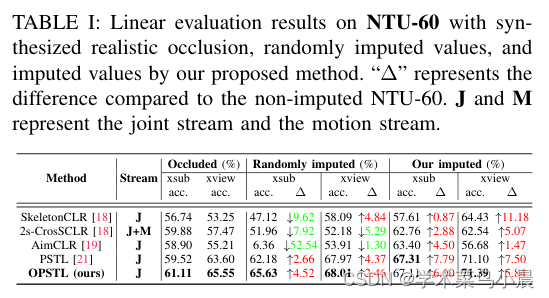

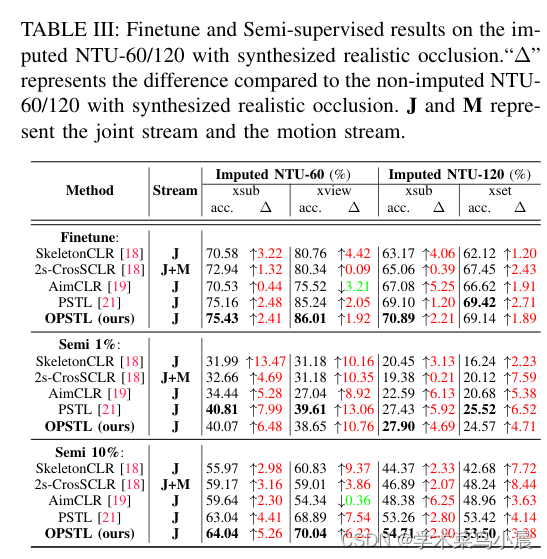
这篇关于自监督+基于骨架的人体动作识别:Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occ的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








