标准差专题

概率学 笔记一 - 概率 - 随机变量 - 期望 - 方差 - 标准差(也不知道会不会有二)
概率不用介绍,它的定义可以用一个公式写出: 事件发生的概率 = 事件可能发生的个数 结果的总数 事件发生的概率=\cfrac{事件可能发生的个数}{结果的总数} 事件发生的概率=结果的总数事件可能发生的个数 比如一副标准的 52 张的扑克牌,每张牌都是唯一的,所以,抽一张牌时,每张牌的概率都是 1/52。但是有人就会说了,A 点明明有四张,怎么会是 1/52 的概率。 这就需要精准的指出

NumPy(五):数组统计【平均值:mean()、最大值:max()、最小值:min()、标准差:std()、方差:var()、中位数:median()】【axis=0:按列运算;axis=0:按列】
统计运算 np.max()np.min()np.median()np.mean()np.std()np.var()np.argmax(axis=) — 最大元素对应的下标np.argmin(axis=) — 最小元素对应的下标 NumPy提供了一个N维数组类型ndarray,它描述了 相同类型 的“items”的集合。(NumPy provides an N-dimensional array

平均值,标准差,方差,协方差,期望,均方误差
1. 写在前面 平均值,标准差,方差,协方差都属于统计数学;期望属于概率数学。 2. 统计数学 2.1 平均值,标准差,方差 统计学里最基本的概念就是样本的均值、方差、标准差。首先,我们给定一个含有n个样本的集合,下面给出这些概念的公式描述: 均值: 方差: 标准差: 均值描述的是样本集合的中间点,它告诉我们的信息是有限的。 方差(variance)是在概率论和统计方差衡量随机变

【数据分析】数据的离中趋势之二 - 方差和标准差、离散系数
四、方差和标准差 方差是数据组中各数据值与其算术平均数离差平方的算术平均数。方差的平方根就是标准差标准差的本质与平均差基本相同,平均差取绝对值的方法消除离差正负号后用算数平均的方法求平均离差。标准差用平方的方法消除离差的正负号后用离差平方求平均数再开根号。标准差的性质: 标准差度量了偏离平均数的大小标准差是一类平均偏差数列大多数项距离平均数少于1个标准差范围内,极少数项距离平均数 2个 或者 3
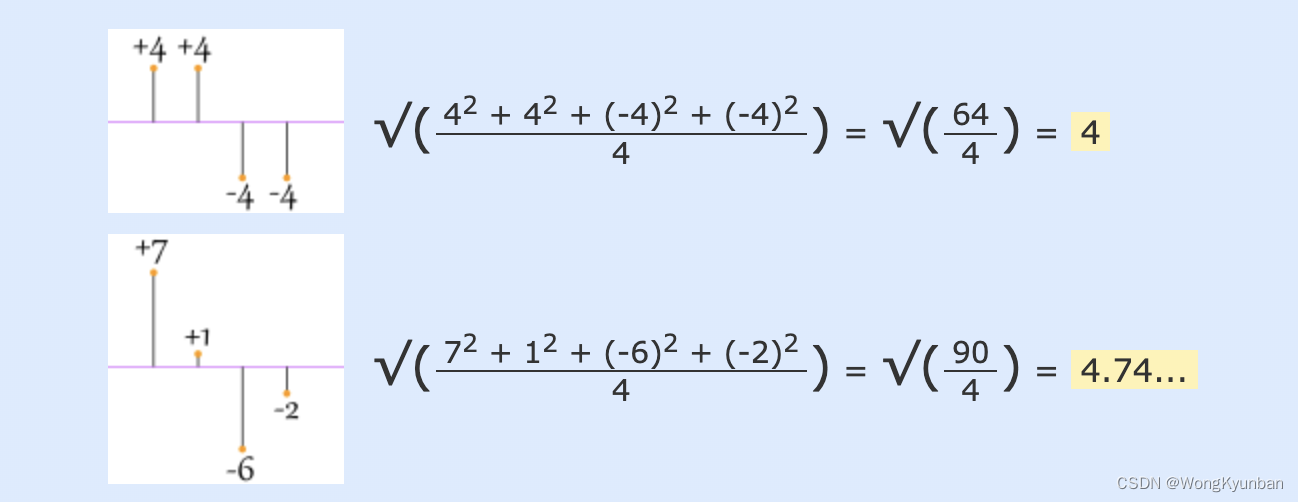

Python, Numpy求 list 数组均值,方差,标准差
代码如下: import numpy as np array = [1,3,5,7,9]# 求均值arr_mean = np.mean(array)# 求方差arr_var = np.var(array)# 求标准差arr_std = np.std(array,ddof=1)
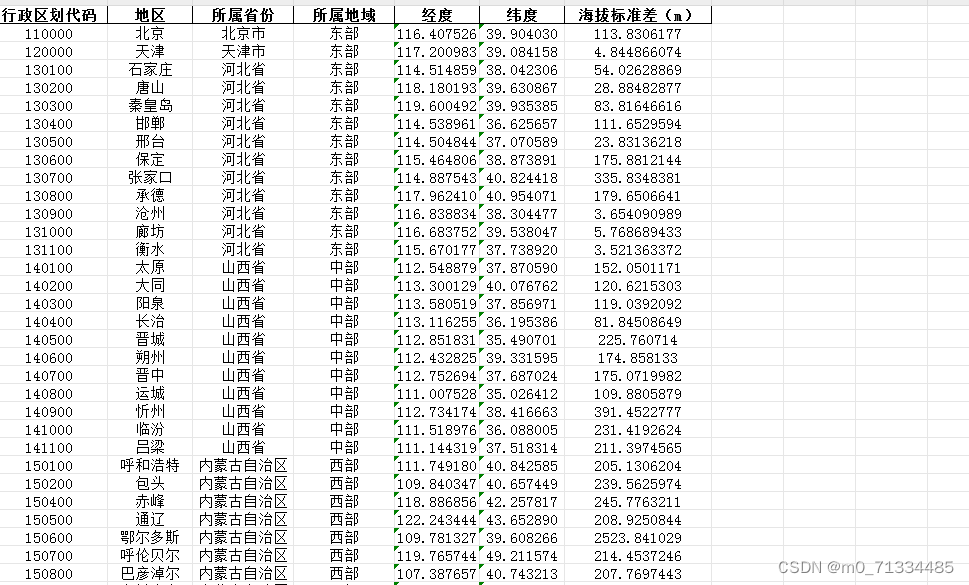
地级市海拔标准差(可用作宽带中国工具变量)
地级市海拔标准差(可用作宽带中国工具变量) 1、来源:地理空间数据云 2、指标:行政区划代码、地区、所属省份、所属地域、经度、纬度、海拔标准差(m) 3、说明:地形起伏度会影响网络基础设施建设,地形起伏度越大,不仅会增加网络基础设施的建设成本,还会影响宽带网络的信号质量;地形起伏度作为自然地理变量,与经济社会因素不相关,不会对城市的经济造成直接影响 4、参考文献: ]刘传明,马青山.网络
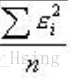
方差、标准差、均方误差和均方根误差
最近在整机器学习的内容,这个概念稍微有点乱,百度一下,里清楚了,做个记录: 一、白话描述 1、方差的二次开方等于标准差 2、均方误差的二次开方等于均方根误差。 3、方差是每个样本减去总样本的平均值去计算的,而均方误差是每个样本减去该样本的真实值来计算的 所以,方差、标准差是数学上的概念,而均方误差是在机器学习中用的比较多的概念,计算loss的时候会用,实际上原理是类似的,但是具体计算上稍
从零开始学统计 03 | 均值,方差,标准差
一、均值 现在,假设已经拿到在实际的肝脏中大约 2400 亿个细胞的X基因表达值。 我们接下来,要计算总体均值与估计总体均值。 现在使用实际的2400亿个细胞计算均值,也就是总体均值(Population Mean) 从总体中抽样 5 个样本,计算估计均值(Estimated Mean): 统计学中,用符号x-bar () 来表示估计均值,也叫样本均值(Sample Mea

【0007day】总体标准差、样本标准差和无偏估计
文章目录 总体标准差和样本标准差无偏估计无偏性与无偏估计量 总体标准差和样本标准差 一些表示上的差别。 总体标准差 样本标准差 两者的区别 样本方差为什么除以n-1? 这主要是由于样本的方差会低估总体的方差(抽样的过程中,按照概率来说,会多选中间的数值从而低估方差),为了使样本标准方差与总体标准方差相接近,这就需要乘以一个大于1的数。)至于为什么是n-1?
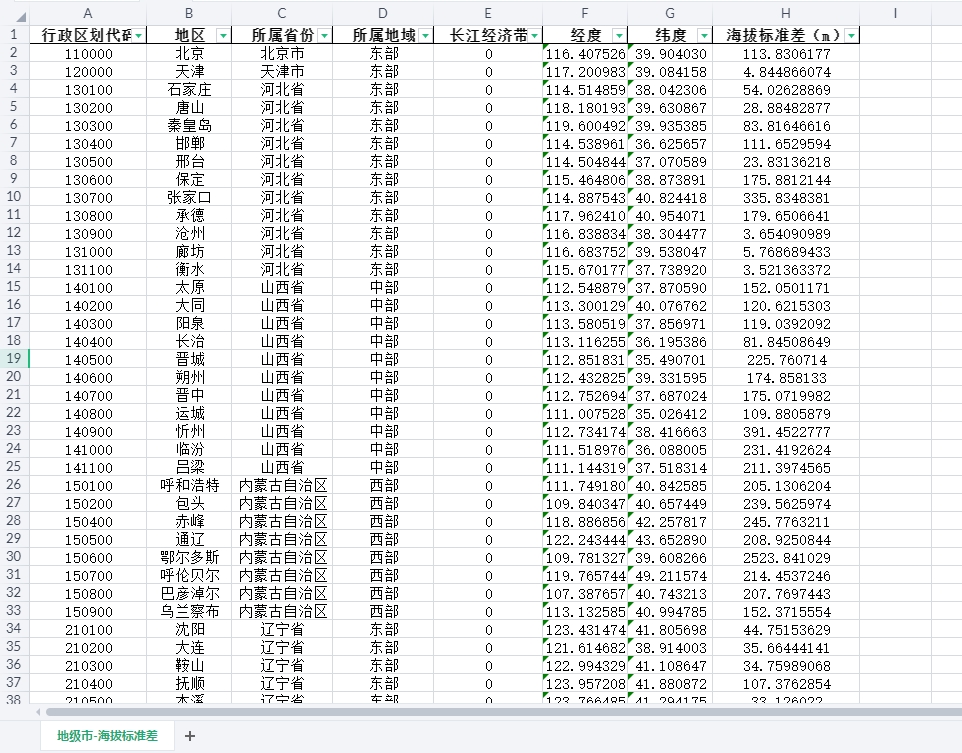
中国各地级市的海拔标准差数据集
01、数据简介 海拔标准差是指对某个地点的海拔进行测量后,所得结果与平均海拔之间的差异。它反映了测量结果的离散程度,即海拔数据的可靠性。如果标准差较小,说明测量结果的可靠性较高;如果标准差较大,则说明测量结果的可靠性较低。 海拔标准差的定义公式为:标准差 = sqrt((1/N)* Σ(海拔数据-平均海拔)^2) 其中,N代表测量数据的数量,海拔数据代表每个测量点的海拔数据,平均海拔代表所有

数据分析的几个数值P值、T值和R值(相关系数)中位数、众数、 方差、 标准差、 协方差、 置信区间
统计学中包含了多个基本概念和数值,以下是关于P值、T值和R值(相关系数)的简要解释,以及其他一些常见的统计学数值: P值(P value): P值是用来判定假设检验结果的一个参数。它表示在原假设为真时,比所得到的样本观察结果更极端的结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设。P值越小,拒绝原假设的理由越充分。 T值(T-

mahout 计算方差标准差
标准差( Standard Deviation),在 概率统计中最常使用作为 统计分布程度(statistical dispersion)上的测量。标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的 平方根。它反映组内个体间的离散程度。测量到分布程度的结果,原则上具有两种 性质: 为非负数值, 与测量 资料具有相同单位。一个总量的标准差或一个 随机变量的标准差,及一个子集合样品数
AI笔记: 数学基础之数字特征-标准差、协方差、相关系数、中心矩、原点矩、峰度、偏度
标准差 标准差(Standard Deviation)是离均值平方的算术平均数的平方根,用符号 σ \sigma σ 表示,其实标准差就是方差的算术平方根标准差和方差都是测量离散趋势的最重要、最常见的指标。标准差和方差的不同点自傲与,标准差和变量的计算单位是相同的,比方差清楚,因此在很多分析的时候使用的是标准差 σ = D ( X )

MySql中的标准差函数 STD, STDDEV_SAMP
百度百科关于标准差的解释: http://baike.baidu.com/link?url=ZD390DwecXfZi0ZM1iq9fXGdxk76ryWH6aErjcS-RGRi5KBCW0fSrw8Y277z20u5 Population standard deviation: 如是总体(即估算总体方差),根号内除以n MySql对应的函数是STD(对应excel函数:S
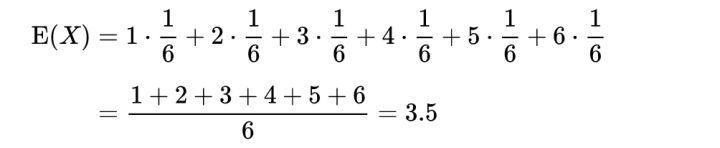
数学期望,方差,标准差,样本方差,协方差,相关系数概念扫盲
数学期望 在概率论和统计学中,数学期望(mean)(或均值,亦简称期望)是试验中每次可能结果的概率乘以其结果的总和,是最基本的数学特征之一。它反映随机变量平均取值的大小。 再举个例子理解一下数学期望: 方差 概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。在许多实际问题中,研究方差即偏

GDAL实现标准差拉伸渲染影像
import osfrom sys import pathfrom osgeo import gdalfrom osgeo import osrimport numpy as npimport matplotlib.pyplot as pltimport matplotlib.colors as mpcimport argparsedef stdStretch(imgFile, co
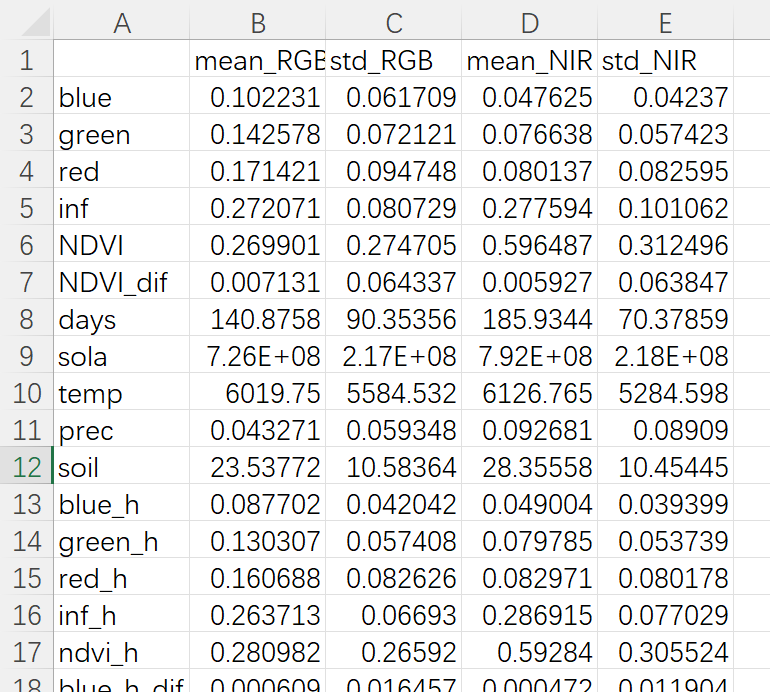
Python计算多个表格中多列数据的平均值与标准差并导出为新的Excel文件
本文介绍基于Python语言,对一个或多个表格文件中多列数据分别计算平均值与标准差,随后将多列数据对应的这2个数据结果导出为新的表格文件的方法。 首先,来看一下本文的需求。现有2个.csv格式的表格文件,其每1列表示1个变量,每1行则表示1个样本;其中1个表格文件如下图所示。 我们现在需要分别对这2个表格文件执行如下操作:计算出其中部分变量(部分列)在所有样本(所有行)中的平均
计算Mat类型的均值和标准差 OpenCV
Mat img; Scalar mean; //均值Scalar stddev; //标准差cv::meanStdDev( img, mean, stddev ); //计算均值和标准差double mean_pxl = mean.val[0]; double stddev_pxl = stddev.val[0];

【数据分析面试】8.计算标准差(python)
题目: 编写一个名为 compute_deviation 的函数,该函数接受一个包含键和整数列表的字典列表,并返回一个字典,其中包含每个列表的标准差。 注意:请勿使用 NumPy 内置函数。 示例: 输入: input = [{'key': 'list1','values': [4,5,2,3,4,5,2,3],},{'key': 'list2','values': [1,1,34,
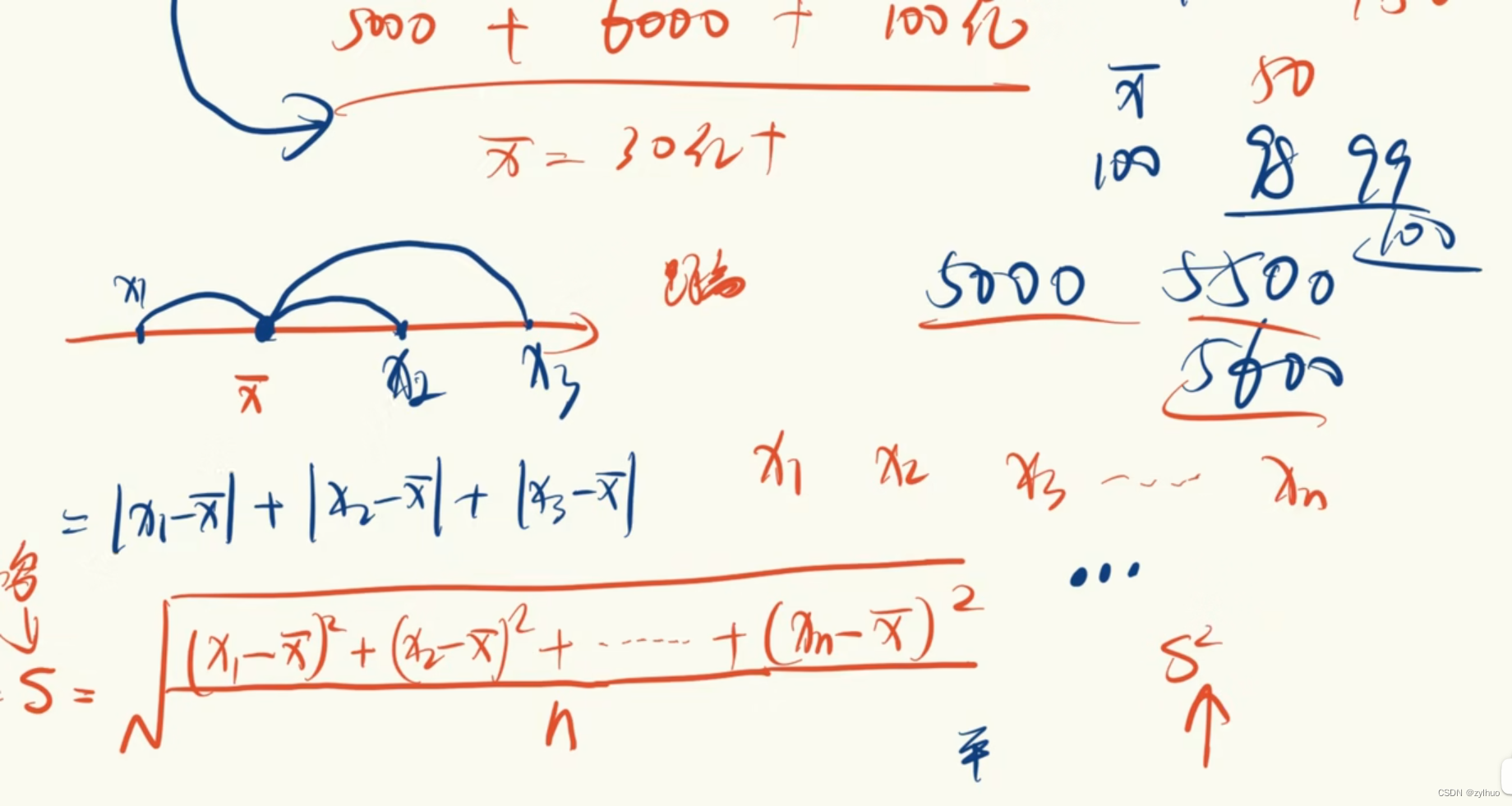
AI-数学-高中-29-样本的数字特征(标准差、方差)
原作者视频:【统计】【一数辞典】3样本的数字特征_哔哩哔哩_bilibili 标准差(s)、方差(S^2)公式:判断数据的稳定性。

n折交叉验证结果中的+-怎么算的? 标准差?有偏估计?无偏估计?
n折交叉验证的结果怎么写 Q:这种实验结果里的±是怎么写出来的呢? A:均值± 标准差 标准差 百度标准差的时候,发现了这两个公式。差别是,后者是无偏估计量。 无偏估计 那么什么是无偏估计呢?下面三个链接很好的解释了: 为什么分母从n变成n-1之后,就从【有偏估计】变成了【无偏估计】? 为什么样本方差(sample variance)的分母是 n-1? 为什么样本方差(sample
基金评价指标1——收益率、回撤、下行标准差、痛苦指数、夏普比率、索蒂诺比率
文章目录 各个模块1. 用生成随机数作为模拟的净值序列2. 收益率相关计算3. 风险指标计算4. 综合评价5. 异常的INF值处理 完整示例程序 基金的评价指标有许多,这一篇博客分享的是最常见的评价指标,包括以下内容: 单日涨跌幅累计收益率年化收益率最大回撤:从历史上最高点到之后的最低点的最大跌幅痛苦指数:创新高才会不痛苦,因此这个指标描述的是从上次创新高到现在的痛苦程度涨跌幅_
Python 列表应用案例:输入10个整数,计算平均值、方差和标准差,找出最大值和最小值
题目:输入10个整数,计算平均值、方差和标准差,找出最大值和最小值。 方差和标准差公式: Var ( X ) = 1 n ∑ ( X i − X ˉ ) 2 \text{Var}(X) = \frac{1}{n} \sum (X_i - \bar{X})^2 Var(X)=n1∑(Xi−Xˉ)2 SD ( X ) = Var ( X ) \text{SD}(X) = \sqrt{\te
给定一组数值,python实现计算均值和标准差(standard deviation)
目录 问题描述: 代码实现: 问题描述: 给定一组实验结果,如何快速计算其平均值和标准差 代码实现: import statistics# 将数据存放在一个列表中data_list = [18.72, 19.64, 19.27]# 计算平均值mean_value = statistics.mean(data_list)mean_value = round(mean