多头专题

DCFormer: 动态组合多头自注意力
多头注意力(MHA)是Transformer的关键组成部分。在MHA中,注意力头是独立工作的,导致注意得分矩阵的低秩瓶颈和注意头冗余等问题。动态组合多头注意(dynamic Composable Multi-Head Attention, DCMHA)是一种参数化和计算效率高的注意力结构,它解决了MHA的不足,并通过动态组合注意头来提高模型的表达能力。DCMHA的核心是一个Comp

多头注意力机制(Multi-Head Attention)
文章目录 多头注意力机制的作用多头注意力机制的工作原理为什么使用多头注意力机制?代码示例 多头注意力机制(Multi-Head Attention)是Transformer架构中的一个核心组件。它在机器翻译、自然语言处理(NLP)等领域取得了显著的成功。多头注意力机制的引入是为了增强模型的能力,使其能够从不同的角度关注输入序列的不同部分,从而捕捉更多层次的信息。 多头注意力机
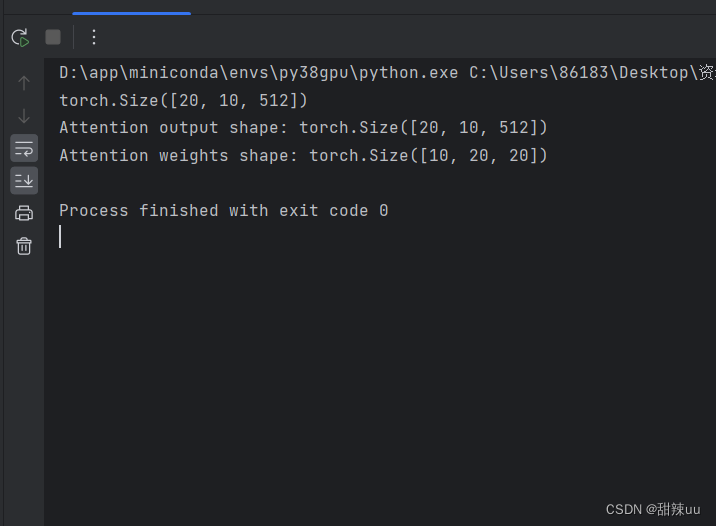
多头Attention MultiheadAttention 怎么用?详细解释
import torchimport torch.nn as nn# 定义多头注意力层embed_dim = 512 # 输入嵌入维度num_heads = 8 # 注意力头的数量multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)# 创建一些示例数据batch_size = 10 # 批次大小seq_le
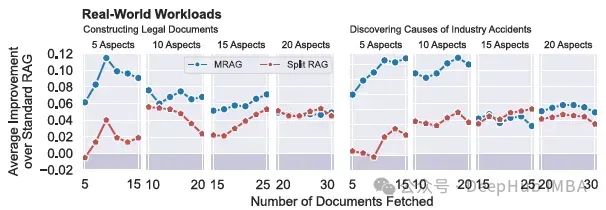
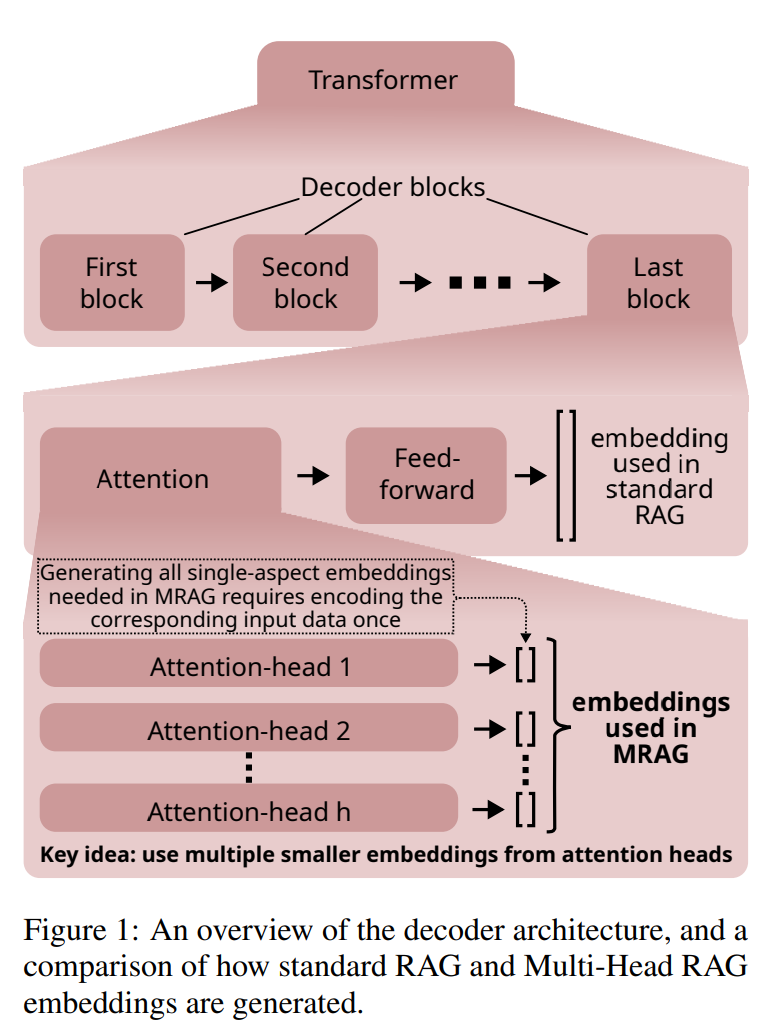
Multi-Head RAG:多头注意力的激活层作为嵌入进行文档检索
现有的RAG解决方案可能因为最相关的文档的嵌入可能在嵌入空间中相距很远,这样会导致检索过程变得复杂并且无效。为了解决这个问题,论文引入了多头RAG (MRAG),这是一种利用Transformer的多头注意层的激活而不是解码器层作为获取多方面文档的新方案。 MRAG 不是利用最后一个前馈解码器层为最后一个令牌生成的单个激活向量,而是利用最后一个注意力层为最后一个令牌生成的H个单独的激活向量,然
【RAG】浅尝基于多头注意力机制思想设计的Multi-Head RAG(多头RAG)
一、动机 现有RAG设计和评估方法,没有方案或评估方法明确针对具有多方面性的问题。下面解释一下多方面性的问题: "多方面性的问题"是指那些需要理解和整合多个不同领域或主题的知识和信息才能得到完整和准确回答的问题。这类问题的特点在于它们涉及的内容跨度广,可能包括但不限于以下几个方面: 多样性的主题:问题可能涉及多个不同的主题或领域,例如,一个关于历史事件的问题可能同时关联到政治、社会、经济和技

【传知代码】时序预测:多头注意力+宽度学习(论文复现)
前言:近年来,随着人工智能技术的飞速发展,尤其是深度学习领域的突破,时序预测领域也迎来了新的变革。传统的预测方法,如线性回归、时间序列分析等,虽然在某些场景下表现良好,但在面对复杂、非线性的时序数据时,往往显得力不从心。此时,一种融合了深度学习最新成果的技术——多头注意力与宽度学习,正逐渐崭露头角,为解决这一难题提供了新的思路。 本文所涉及所有资源均在传知代码平台可获取 目录 概述
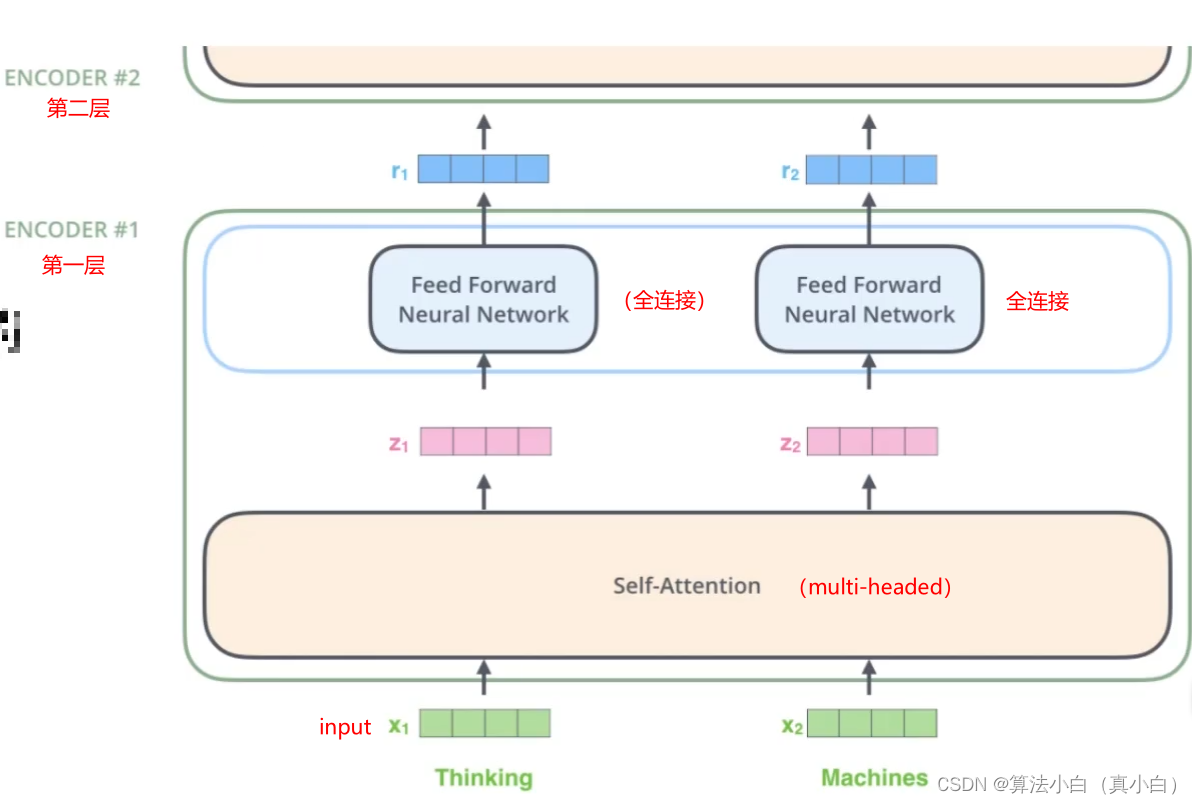
Transformer系列专题(二)——multi-headed多头注意力机制
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、什么是multi-headed(多头注意力机制)二、multi-headed三、multi-headed结果四、堆叠多层总结 前言 在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,例如捕获序列内各种范围
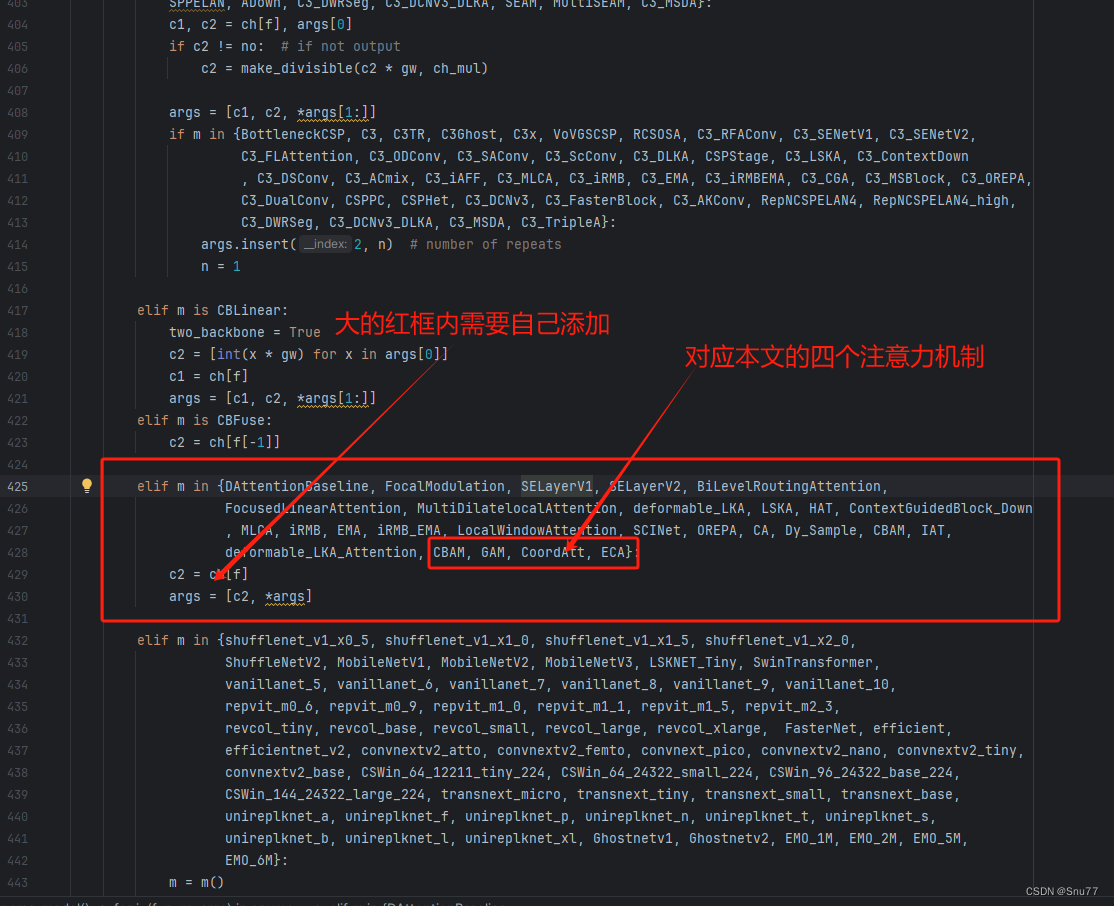
YOLOv9改进策略 | 添加注意力篇 | 一文带你改进GAM、CBAM、CA、ECA等通道注意力机制和多头注意力机制
一、本文介绍 这篇文章给大家带来的改进机制是一个汇总篇,包含一些简单的注意力机制,本来一直不想发这些内容的(网上教程太多了,发出来增加文章数量也没什么意义),但是群内的读者很多都问我这些机制所以单独出一期视频来汇总一些比较简单的注意力机制添加的方法和使用教程,本文的内容不会过度的去解释原理,更多的是从从代码的使用上和实用的角度出发去写这篇教程。 欢迎大家订阅我的专栏一起学习YOLO!
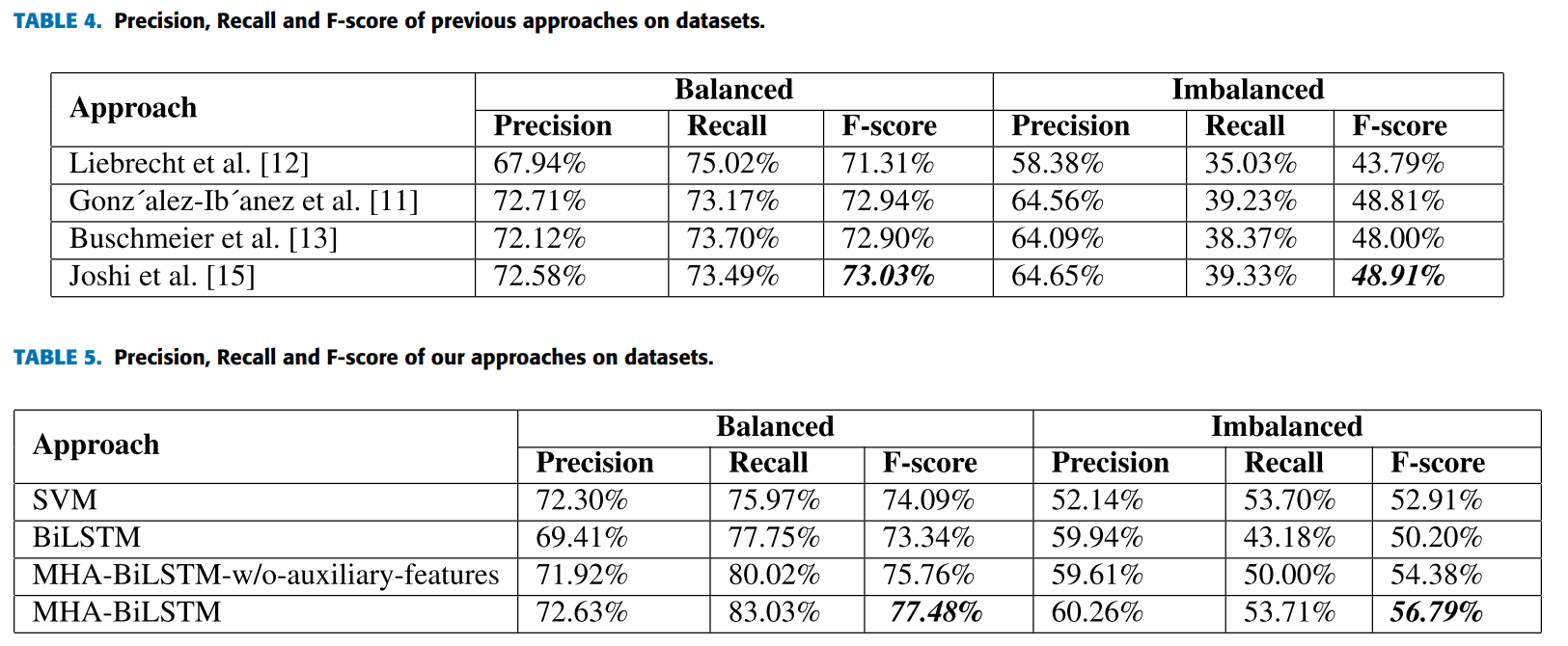
Sarcasm detection论文解析 |使用基于多头注意力的双向 LSTM 进行讽刺检测
论文地址 论文地址:https://ieeexplore.ieee.org/document/8949523 论文首页 笔记框架 使用基于多头注意力的双向 LSTM 进行讽刺检测 📅出版年份:2020 📖出版期刊:IEEE Access 📈影响因子:3.9 🧑文章作者:Kumar Avinash,Narapareddy Vishnu Teja,Aditya Sr

天载优配解读多头是否能够延续
技能面: 早盘冲高到1891.6附近后轰动回落,现在回落给到1883,整体是涨后修改,待修改完毕后继续看涨的思路不变。 已然行情归于调整修改,短线上有一个下行通道,若回落不破下行通道下轨支撑,反而上行打破,那么短线可能会构成旗形拾掇,当然这需求时间去验证,若能构成旗形拾掇,后市继续大涨可期。 下方短线支撑在1880附近,强支撑在1874-1876方位,这里是顶底转化支撑,也是日线20日均线支

注意力机制(四)(多头注意力机制)
🌈 个人主页:十二月的猫-CSDN博客 🔥 系列专栏: 🏀《深度学习基础知识》 相关专栏: ⚽《机器学习基础知识》 🏐《机器学习项目实战》 🥎《深度学习项目实战(pytorch)》 💪🏻 十二月的寒冬阻挡不了春天的脚步,十二点的黑夜遮蔽不住黎明的曙光 目录
冯喜运:4.26美GDP和PCE掀起汇市浪潮:黄金原油多头和空头决战
【黄金消息面分析】:美国经济在2024年第一季度的表现引发了市场对美联储未来政策路径的重新评估。根据美国商务部经济分析局的最新数据,GDP年化增长率为1.6%,低于经济学家预测的2.4%,且远低于前一季度的3.4%。数据公布后现货黄金短线走高5美元,最高触及2334.60美元,后一路震荡下行,回吐数据公布后的所有涨幅,回落至2316.02美元/盎司左右。美元指数在数据公布后30分钟上涨逾50
transformer中,多头注意力机制
在Transformer模型中,多头注意力机制通常在自注意力机制(Self-Attention)的步骤中使用。自注意力机制是Transformer中的核心组件之一,用于在输入序列中建立全局依赖关系,并为每个位置生成一个上下文相关的表示。 具体来说,自注意力机制通过计算每个位置与序列中所有其他位置的注意力权重,然后将这些权重与相应位置的表示进行加权求和,从而生成每个位置的上下文相关表示。而多头注意

多头蜗杆的轴截面和端截面的关系
最近有一个点,之前没有注意,就是多头蜗杆的导程与齿距的关系,它们会影响蜗杆断截面的形状,是不是听的有点别扭,往下看: 上图是一个蜗杆的轴剖面齿形,看到这个图形,如果看不到蜗杆实物或者有明显的标准,我们是没办法判断这个蜗杆的头数是多少。 从下面几张图可以看到,同样的轴截面齿形可以采用不同头数的蜗杆: 这个就比较有意思了,那么要满足什么条件才能达到这样的效果呢?起始书上早就告诉我们了:

“25万人爆仓近10亿美元”!中东紧张情势加剧,比特币遭遇史诗级崩跌!避险属性失效还是减半前清算多头杠杆?
中东紧张情势加剧,伊朗14日清晨证实已向以色列发射大批无人机和导弹,以报复4月1日针对其大马士革领事馆的致命袭击。 以色列军方也确认,伊朗已向以色列发射了200多台无人攻击机。随后美国总统拜登承诺对以色列提供“坚不可摧”的支持,并补充说,美国将“尽一切努力保护以色列的安全”。 消息传出,币圈投资者最担心的情景发生了:凌晨4点开始,比特币价格在15分钟内瞬间暴跌了5

分类预测 | Matlab实现基于迁移学习和GASF-CNN-Mutilhead-Attention格拉姆角场和卷积网络多头注意力机制多特征分类预测/故障识别
分类预测 | Matlab实现基于迁移学习和GASF-CNN-Mutilhead-Attention格拉姆角场和卷积网络多头注意力机制多特征分类预测/故障识别 目录 分类预测 | Matlab实现基于迁移学习和GASF-CNN-Mutilhead-Attention格拉姆角场和卷积网络多头注意力机制多特征分类预测/故障识别分类效果基本介绍模型描述程序设计参考资料 分类效果
TR4 - Transformer中的多头注意力机制
目录 前言自注意力机制Self-Attention层的具体机制Self-Attention 矩阵计算 多头注意力机制例子解析 代码实现总结与心得体会 前言 多头注意力机制可以说是Transformer中最主要的模块,没有之一。这次我们来仔细分析一下注意力机制与多头注意力机制。 自注意力机制 在Transformer模型中,输入的文本序列经过输入处理转换为一个向量的序列
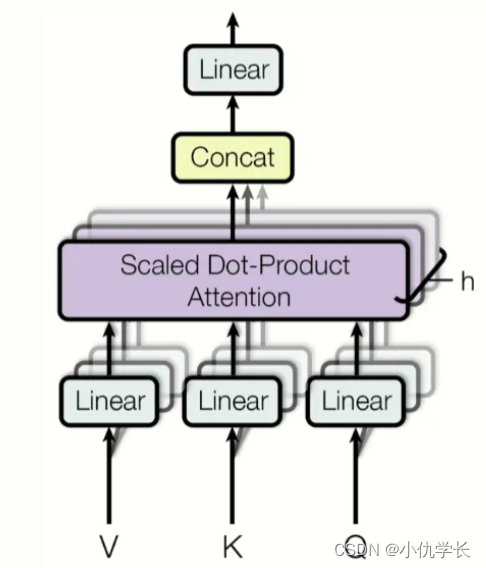
深度学习理论基础(六)Transformer多头注意力机制
目录 一、自定义多头注意力机制1. 缩放点积注意力(Scaled Dot-Product Attention)● 计算公式● 原理 2. 多头注意力机制框图● 具体代码 二、pytorch中的子注意力机制模块 深度学习中的注意力机制(Attention Mechanism)是一种模仿人类视觉和认知系统的方法,它允许神经网络在处理输入数据时集中注意力于相关的部分。通过引
Transformer模型-Multi-Head Attention多头注意力的简明介绍
今天介绍transformer模型的Multi-Head Attention多头注意力。 原论文计算scaled dot-product attention和multi-head attention 实际整合到一起的流程为: 通过之前文章,假定我们已经理解了attention;今天我们按顺序来梳理一下整合之后的顺序。重新梳理Attention Is All You N
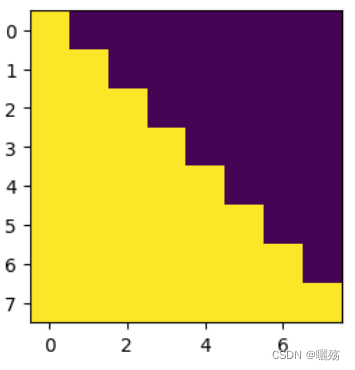
Transformer学习: Transformer小模块学习--位置编码,多头自注意力,掩码矩阵
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Transformer学习 1 位置编码模块1.1 PE代码1.2 测试PE 2 多头自注意力模块2.1 多头自注意力代码2.2 测试多头注意力 3 未来序列掩码矩阵 1 位置编码模块 P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d m o
分类预测 | Matlab实现TCN-BiGRU-Mutilhead-Attention时间卷积双向门控循环单元多头注意力机制多特征分类预测/故障识别
分类预测 | Matlab实现TCN-BiGRU-Mutilhead-Attention时间卷积双向门控循环单元多头注意力机制多特征分类预测/故障识别 目录 分类预测 | Matlab实现TCN-BiGRU-Mutilhead-Attention时间卷积双向门控循环单元多头注意力机制多特征分类预测/故障识别分类效果基本介绍模型描述程序设计参考资料 分类效果 基本介

EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经网络双向门控循环单元融合多头注意力机制多变量时间序列预测(Matlab)
EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经网络双向门控循环单元融合多头注意力机制多变量时间序列预测(Matlab) 目录 EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经网络双向门控循环单元融合多头注意力机制多变量时间序列预测(Matlab)预测效果基本介绍程序设计参考资料 预测效果

全球首创 | 领创激光研发“多头激光切割铝单板生产线”
激光加工一直有着精度高,速度快,效率高,可塑性高等优点,随着近几年激光在各个领域的应用,业界对激光加工的要求也越来越高,如加工的精度,速度、传送装置等等都提出了更高的要求。从传送装置来说,目前现有的切割机的传送装置存在体积大、工件运送不稳定、运送装置易被激光击穿等缺陷。为了满足市场的需要,需要对现有的激光传送设备进行改良,领创激光智能装备部经过半年的研究和试验,研制出世界首台可以“三梁三头” 同步

多维时序 | Matlab实现BiGRU-Mutilhead-Attention双向门控循环单元融合多头注意力机制多变量时序预测
多维时序 | Matlab实现BiGRU-Mutilhead-Attention双向门控循环单元融合多头注意力机制多变量时序预测 目录 多维时序 | Matlab实现BiGRU-Mutilhead-Attention双向门控循环单元融合多头注意力机制多变量时序预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.多维时序 | Matlab实现BiG
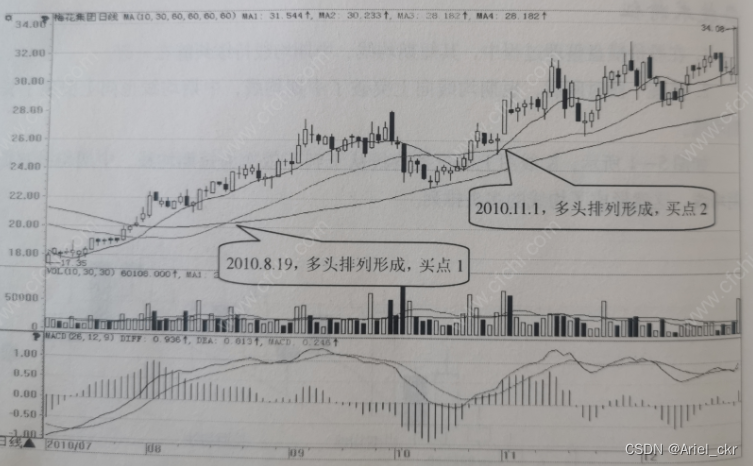
技术指标的买入形态之均线形成多头排列
一、技术特征 1、在股价横盘整理过程中,其短期均线、中期均线持续纠缠在一起。 2、整理一段时间后,短期均线向上突破了中期均线,中期均线也向上突破了长期均线。 均线多头排列是股价处于上涨行情中的信号。 二、买点描述 当均线的多头排列完成时,买点出现。 三、经典案例 四、实战提高 1、多头排列的形成可能是以短期均线突破中期均线为标志,也可能是以中期均线突破长期均线为标志。 2、一旦短
美易官方:美股太疯狂!美银成为最大多头
在当前全球经济环境下,美股市场的表现无疑成为了投资者关注的焦点。近期,美国银行(美银)的一份报告更是引起了市场的广泛关注。美银在报告中大胆预测,标普500指数到年底将涨至5400点,这一预测无疑给已经火热的美股市场再添一把火。那么,美股市场究竟为何如此疯狂?美银为何会成为最大的多头?这一预测又是否可信呢? 首先,我们要明确的是,美股市场的疯狂并非空穴来风。在过去的几年里,美国经济的持续增长、科