本文主要是介绍【RAG】浅尝基于多头注意力机制思想设计的Multi-Head RAG(多头RAG),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、动机
现有RAG设计和评估方法,没有方案或评估方法明确针对具有多方面性的问题。下面解释一下多方面性的问题: "多方面性的问题"是指那些需要理解和整合多个不同领域或主题的知识和信息才能得到完整和准确回答的问题。这类问题的特点在于它们涉及的内容跨度广,可能包括但不限于以下几个方面:
-
多样性的主题:问题可能涉及多个不同的主题或领域,例如,一个关于历史事件的问题可能同时关联到政治、社会、经济和技术等多个方面。
-
复杂的关系:问题中的不同方面之间可能存在复杂的相互关系,需要对这些关系有深入的理解才能准确回答。
-
多源信息:为了回答这类问题,可能需要从多个不同的信息源或文档中检索和整合数据。
-
综合回答:需要对检索到的信息进行综合分析,以形成一个全面、准确的回答。
例如,考虑一个问题:“亚历山大大帝是如何影响现代汽车工业的?” 这个问题本身就是高度多方面性的,因为它涉及到古代历史(亚历山大大帝)和现代技术(汽车工业)。要准确回答这个问题,可能需要检索和整合关于亚历山大大帝的历史资料、关于汽车工业的发展史,以及两者之间可能存在的间接联系等多个方面的信息。MRAG的设计使其能够更好地处理这种类型的问题。
这类问题需要在单个查询中结合多个显著不同的方面,这在现有RAG方案中尚未得到解决。文章提出了MRAG,通过利用Transformer的多头注意力层的激活来解决上述问题,而不是使用传统的解码器层激活。作者认为,不同的注意力头可以捕获数据的不同方面,从而在不增加存储需求的情况下,提高对复杂多方面查询的检索准确性。
二、MRAG架构
2.1 解码器架构
在MRAG中,解码器的输入是一个由 n n n个token组成的文本块。解码器的输出是每个attention head对第 i i i个token x i x_i xi的输出。
-
注意力头输出:
对于第 i i i个token x i x_i xi,第h个attention head的输出定义为:
head h ( x i ) = ∑ j w i j v h j \text{head}_h(x_i) = \sum_{j} w_{ij} v_{hj} headh(xi)=j∑wijvhj
其中,权重 w i j w_{ij} wij 是通过softmax函数计算得到的:
w i j = softmax ( q h i T k h j d k ) w_{ij} = \text{softmax} \left( \frac{q_{h_i}^T k_{hj}}{\sqrt{d_k}} \right) wij=softmax(dkqhiTkhj)
这里, q h i q_{h_i} qhi 是与head h 相关联的可学习query向量, k h j k_{hj} khj 是第j个token的可学习key向量, v h j v_{hj} vhj是第j个token的可学习value向量。 d k d_k dk是key向量的维度,用于softmax的缩放,防止梯度消失或爆炸。 -
多头注意力输出:
所有attention head的输出被合并,形成第 i i i个token的多头注意力输出 m u l t i − h e a d ( x i ) multi-head(x_i) multi−head(xi):
multi-head ( x i ) = W o concat ( head 1 ( x i ) , . . . , head h ( x i ) ) \text{multi-head}(x_i) = W_o \text{concat}(\text{head}_1(x_i), ..., \text{head}_h(x_i)) multi-head(xi)=Woconcat(head1(xi),...,headh(xi))
这里, W o W_o Wo 是一个线性层,用于合并所有attention heads的输出结果。 -
前馈层:
多头注意力的输出随后会通过一个前馈神经网络层进一步处理。
2.2 标准RAG
在标准RAG中,嵌入是通过以下步骤生成的:
- 使用最后一个decoder block的输出。
- 对最后一个token x n x_n xn 应用feed-forward层。
- 获取激活向量$ feed-forward(multi-head(x_n))$作为嵌入表示。
2.3 Multi-Head RAG
MRAG的关键思想是使用最后一个attention层生成的多个激活向量,而不是仅使用最后一个feed-forward解码器层的输出。具体来说:
-
对于最后一个token x n x_n xn,生成一组嵌入 S S S:
S = { e k ∀ k } S = \{ e_k \forall k \} S={ek∀k}
其中 e k e_k ek 是第 k k k个头在最后一个token x n x_n xn 上的输出。 -
这种方法允许MRAG捕获输入数据的多个方面,因为不同的attention heads可能专注于数据的不同特征。
2.4 MRAG pipline

MRAG流程由两个主要部分组成:数据准备(Data Preparation)和查询执行(Query Execution)。这两部分都依赖于一个数据存储(Data Store),它是一个向量数据库,用于存储文档或文本片段的嵌入表示。
2.4.1 数据准备(Data Preparation)
数据准备阶段的目的是填充数据存储,使其包含多方面MRAG文本嵌入及其对应的文档或文本片段。
- 嵌入模型:选择一个基于解码器的嵌入模型(Embedding Model),用于生成文本片段的多方面嵌入。
- 多方面嵌入:为每个文本片段创建多方面嵌入,每个嵌入代表文本的不同方面。
- 数据存储:将生成的多方面嵌入及其对应的文本片段存储在数据存储中。
2.4.2 查询执行(Query Execution)
查询执行阶段的目的是使用MRAG处理用户查询,并检索最相关的文档或文本片段。
- 查询嵌入:使用与数据准备阶段相同的嵌入模型为输入查询生成多方面嵌入。
- 检索策略:使用特殊的多方面检索策略,在数据存储中找到与查询最相关的嵌入及其对应的文本片段。
- 评估:可选地,使用特定的评估指标来衡量检索到的数据与多方面需求的匹配程度。
2.4.3 数据存储结构
MRAG在数据存储中以不同于标准RAG的方式存储数据。在MRAG中,每个多方面嵌入由多个单方面嵌入组成,每个单方面嵌入都指向原始文本片段。这意味着数据存储包含多个嵌入空间,每个空间捕获文本的不同方面。
2.4.4 检索策略
MRAG的检索策略包括以下步骤:
-
重要性评分:为所有嵌入空间分配重要性分数,以反映不同空间的相关性。

该算法基于经验启发式方法,旨在评估每个注意力头的相关性。 a i a_i ai 表示头 h i h_i hi 的“重要性”,L2范数越大,表示头 h i h_i hi 越重要。 b i b_i bi 作为衡量嵌入空间“分散度”的代理,余弦距离越大,表示嵌入空间中向量之间的分散度越高。 通过计算 a i a_i ai 和 b i b_i bi 的乘积,算法奖励那些具有高平均关注度和高平均分散度的头,同时惩罚那些具有低关注度或低分散度的头。
-
传统RAG检索:对每个嵌入空间分别应用传统RAG检索,返回每个空间中最接近的文本片段列表。
-
投票策略:使用投票策略从所有嵌入空间返回的文本片段列表中选择最佳的k个文本片段。这个策略结合了嵌入空间的重要性分数和文本片段在列表中的位置。
2.4.5 方便集成
- MRAG设计为可以与现有的RAG解决方案和基准框架(如RAGAS)无缝集成,并且可以与不同类型的数据存储一起使用。用户可以选择自己的嵌入模型和查询,MRAG提供了合成数据生成器和查询生成器,用于评估目的。
- MRAG可以与不同类型的数据存储和最近邻(NN)搜索方法无缝使用。它可以与精确和近似的最近邻搜索结合使用,以找到匹配的(嵌入,文本块)对。
三、总结
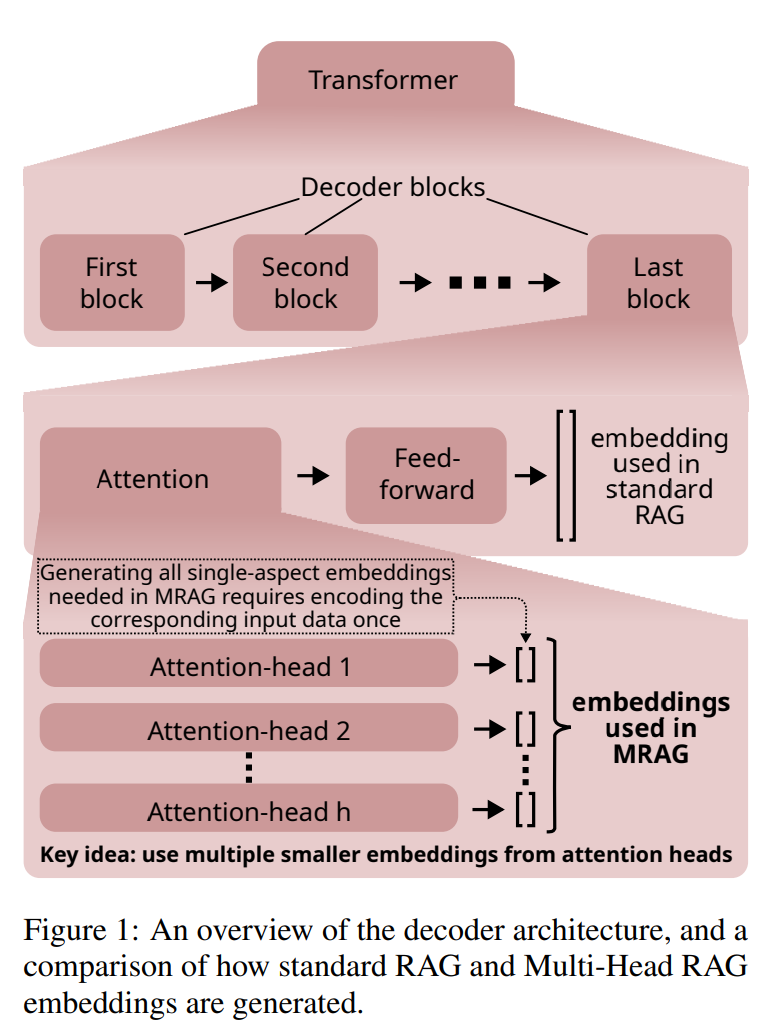
标准RAG(Retrieval-Augmented Generation)和Multi-Head RAG(MRAG)都是为了增强大型语言模型(LLMs)能力的框架,但它们在实现方式上存在一些关键差异。下面对标准RAG和MRAG的对比做个小总结:
标准RAG
- 嵌入生成:在标准RAG中,嵌入是通过使用解码器层的激活向量来生成的。具体来说,它通常采用最后一个解码器块的输出来创建文档或文本片段的嵌入表示。
- 检索:当接收到查询时,标准RAG会构建一个查询嵌入,然后在向量数据库中检索与该嵌入最相似的文档或文本片段。
- 应用场景:标准RAG适用于各种场景,但在处理需要多个不同方面信息的复杂查询时可能会遇到挑战,因为相关文档的嵌入可能在嵌入空间中相隔较远。
- 局限性:由于它依赖于单一的嵌入空间,标准RAG在处理多方面问题时可能无法有效地检索所有相关的文档。
多头RAG (MRAG)
- 嵌入生成:MRAG的核心创新在于使用Transformer的多头注意力层的激活来生成嵌入,而不是解码器层。这种方法利用了多头注意力机制,每个头可以捕获数据的不同方面。
- 多方面嵌入:MRAG为每个输入生成一组嵌入,每个嵌入代表数据的不同方面。这称为**“Multi-Aspect(多方面)嵌入”**,它由多个“单方面嵌入”组成,每个嵌入对应于注意力层中的一个头。
- 数据存储:MRAG在数据存储中为每个文本片段存储多个嵌入,每个嵌入捕捉文本的不同方面。这允许MRAG在多个嵌入空间中进行检索,每个空间代表数据的一个特定方面。
- 检索策略:MRAG使用一种特殊的检索策略,它首先为每个嵌入空间分配重要性分数,然后使用投票机制从不同空间检索到的文本片段中选择最相关的片段。
参考文献
- paper:Multi-Head RAG: Solving Multi-Aspect Problems with LLMs,https://arxiv.org/pdf/2406.05085
- code:https://github.com/spcl/MRAG
这篇关于【RAG】浅尝基于多头注意力机制思想设计的Multi-Head RAG(多头RAG)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





