本文主要是介绍多头Attention MultiheadAttention 怎么用?详细解释,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
import torch
import torch.nn as nn# 定义多头注意力层
embed_dim = 512 # 输入嵌入维度
num_heads = 8 # 注意力头的数量
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)# 创建一些示例数据
batch_size = 10 # 批次大小
seq_len = 20 # 序列长度
query = torch.rand(seq_len, batch_size, embed_dim) # 查询张量
key = torch.rand(seq_len, batch_size, embed_dim) # 键张量
value = torch.rand(seq_len, batch_size, embed_dim) # 值张量
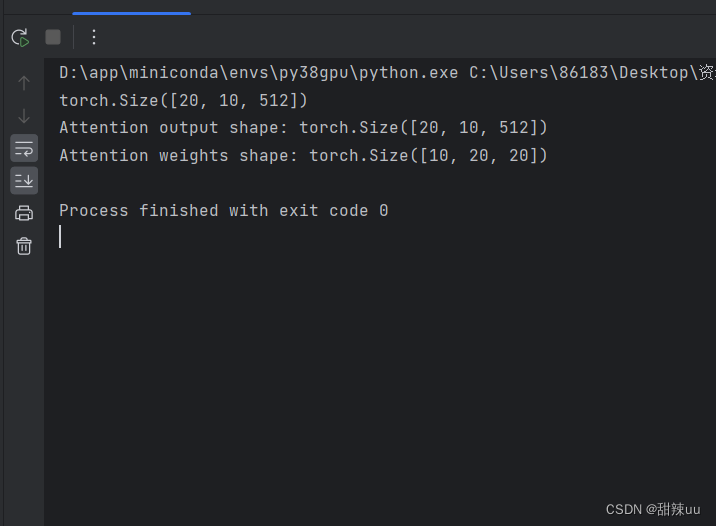
print(query.shape)
# 计算多头注意力
attn_output, attn_output_weights = multihead_attn(query, key, value)
print("Attention output shape:", attn_output.shape) # [seq_len, batch_size, embed_dim]
print("Attention weights shape:", attn_output_weights.shape) # [batch_size, num_heads, seq_len, seq_len]
这篇关于多头Attention MultiheadAttention 怎么用?详细解释的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




