multiheadattention专题

用einsum实现MultiHeadAttention前向传播
einsum教程网站Einstein Summation in Numpy | Olexa Bilaniuk's IFT6266H16 Course Blog 编写训练模型 import tensorflow as tfclass Model(tf.keras.Model):def __init__(self, num_heads, model_dim):super().__init__
多头Attention MultiheadAttention 怎么用?详细解释
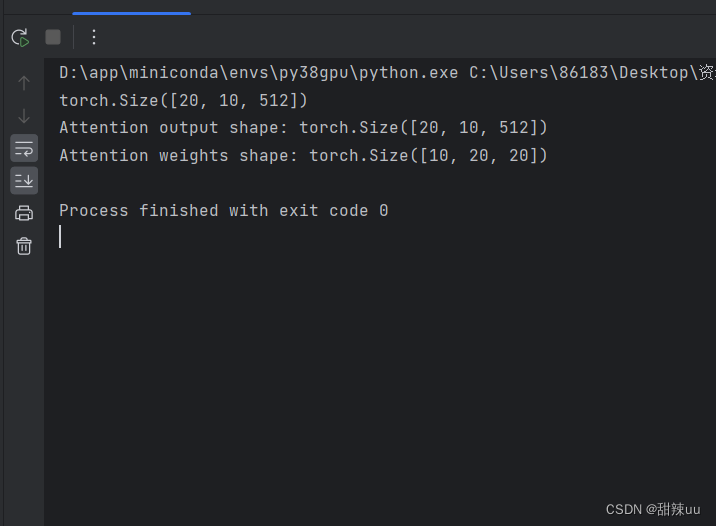
import torchimport torch.nn as nn# 定义多头注意力层embed_dim = 512 # 输入嵌入维度num_heads = 8 # 注意力头的数量multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)# 创建一些示例数据batch_size = 10 # 批次大小seq_le
MultiHeadAttention在Tensorflow中的实现原理
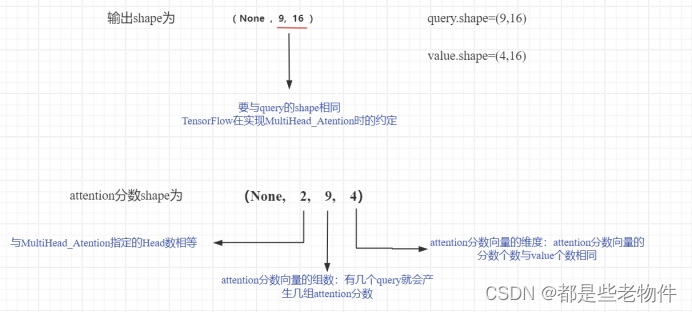
前言 通过这篇文章,你可以学习到Tensorflow实现MultiHeadAttention的底层原理。 一、MultiHeadAttention的本质内涵 1.Self_Atention机制 MultiHeadAttention是Self_Atention的多头堆嵌,有必要对Self_Atention机制进行一次深入浅出的理解,这也是MultiHeadAttenti
multiheadattention类原理及源码理解
网络找的一段代码如下: class MultiHeadedAttention(nn.Module):def __init__(self, h, d_model, dropout=0.1):"Take in model size and number of heads."super(MultiHeadedAttention, self).__init__()assert d_model % h =
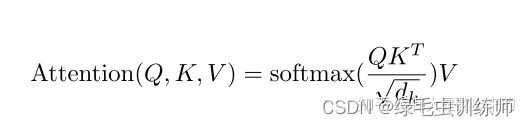
VIT中PatchEmbed、MultiHeadAttention代码详解(PyTorch)
本文对PatchEmbed和MulitHeadAttention进行代码的详细解读,希望可以给同样被此处困扰的小伙伴提供一些帮助,如有错误,还望指正。 文章目录 一、VIT简单介绍二、PatchEmbed1.PatchEmbed的目的2.代码的执行过程3.注意4.完整代码解释5.代码简化版 三、Attention机制1.self-attention和MultiHeadAttention的区