本文主要是介绍VIT中PatchEmbed、MultiHeadAttention代码详解(PyTorch),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文对PatchEmbed和MulitHeadAttention进行代码的详细解读,希望可以给同样被此处困扰的小伙伴提供一些帮助,如有错误,还望指正。
文章目录
- 一、VIT简单介绍
- 二、PatchEmbed
- 1.PatchEmbed的目的
- 2.代码的执行过程
- 3.注意
- 4.完整代码解释
- 5.代码简化版
- 三、Attention机制
- 1.self-attention和MultiHeadAttention的区别
- 2.部分代码解释
- 3.实现思想
- 4.完整代码解释
一、VIT简单介绍
相信看到本文的小伙伴基本都是了解了VIT为何物,否则也不会对PatchEmbed感兴趣,所以本文只对VIT做一个简单的介绍。
VIT是Vision Transformer的简称,是将Transformer模型运用在图片上的一个重要的网络模型,也是Transformer四大核心模块之一。
其思想就是将图片分块再拼接形成如同文本数据一般的序列数据,方便将数据输入到Transformer网络中。如图为VIT的网络模型结构,本文不会讨论其所有的子模块,而是选择器PatchEmbed模块和MultiHeadAttention模块进行代码的详解。
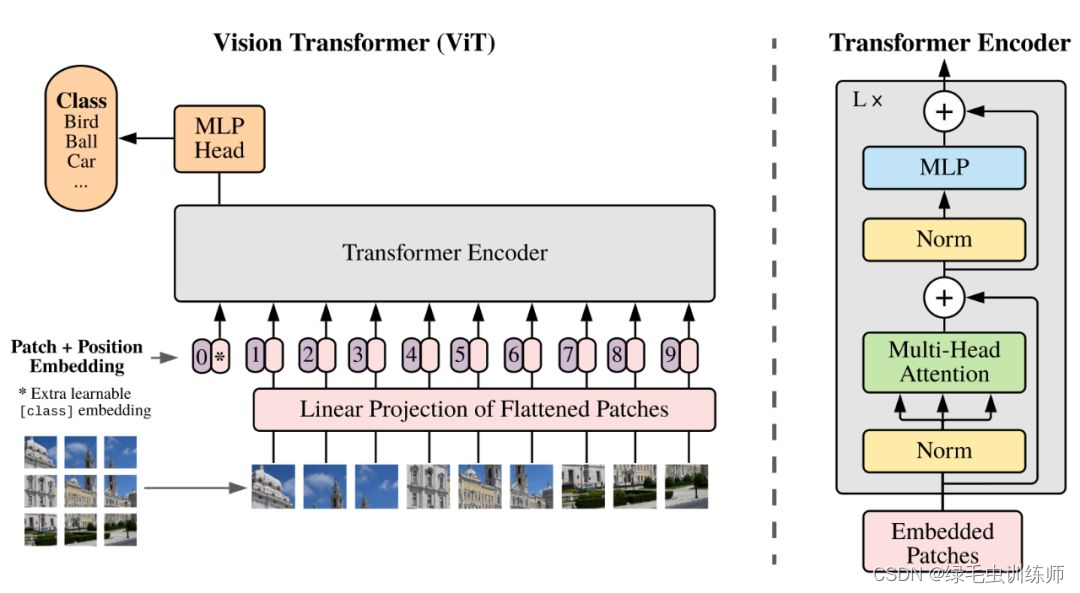
二、PatchEmbed
1.PatchEmbed的目的
将输入的图片用分块再拼接的思想转化为序列的形式,因为Transformer只能接收序列数据。注意这里只是用了分块再拼接的思想,看代码的时候,不需要这个思想也是可以看懂的,如果理解不了,就直接看代码就可以了。或者说看懂了代码之后就理解这个思想了。
2.代码的执行过程
1.输入的图片size为[B, 3, 224, 224]
2.确定好分块的大小为patch_size=16,确定好16,就可以确定卷积核的大小为16,步长为16,即patch_size = kernel_size = stride
3.首先图片通过卷积nn.Conv2d(3, 768,(16,16), (16,16))后size变为[B, 768, 14, 14]
4.再经历一次flatten(2),变为[B, 768, 14*14=196],这里flatten(2)的2意思是在位序为2开始进行展平
5.最后经过一次转置transpose(1, 2),size变成[B, 196, 768]
3.注意
许多人还是不理解为什么要将图片的size转成[B, 196, 768],因为Transformer接受的是序列格式的数据,而不是图片4维【B,C,H,W】的格式,序列如文本数据的格式为【B,N,C】,N为token的个数,C为每个token的维度。只有将图片通过分块拼接成序列形式,才可以输入到transformer网络中。
4.完整代码解释
class PatchEmbed(nn.Module):def __init__(self, img_size=224, # 输入图片大小patch_size=16, # 分块大小in_c=3, # 输入图片的通道数embed_dim=768, # 经过PatchEmbed后的分块的通道数norm_layer=None): # 标准化层super(PatchEmbed, self).__init__()img_size = (img_size, img_size) #将img_size、patch_size转为元组patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_size# // 是一种特殊除号,作用为向下取整# grid_size:分块后的网格大小,即一张图片切分为块后形成的网格结构,理解不了不用理解,就是为了求出分块数目的self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.num_patches = self.grid_size[0] * self.grid_size[1] # 分块数量self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) # 分块用的卷积# 如果norm_layer为None,就使用一个空占位层,就是看要不要进行一个标准化self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()# nn.Identity()层是用来占位的,没什么用def forward(self, x):B, C, H, W = x.shape# assert是python的断言,当后面跟的是False时就会停下assert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})""""x = self.proj(x).flatten(2).transpose(1, 2)1.第一步将x做卷积 [B, 3, 224, 224] -> [B, 768, 14, 14]2.从位序为2的维度开始将x展平 [B, 768, 14, 14] -> [B, 768, 196]3.转置[B, 196, 768] 得到batch批次,每个批次有196个“词”,每个“词”有768维"""x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return x
5.代码简化版
上述代码可以简化为如下代码,不同之处在于使用了Rearrange函数
Rearrange函数可以很方便的操作张量的shape,直接替代了view和reshape方法
Rearrange函数的简单使用如下:
from einops import rearrangeimg = torch.randn(1, 3, 224, 224)
print(img.shape)
patch = rearrange(img, 'b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=16, s2=16)
"""
解释:
img [1, 3, 224, 224]
【b c (h s1) (w s2)】其中s1=s2=16,故可知h=w=224/16=14
故【b (h w) (s1 s2 c)】=[b 196 768]
"""
print(patch.shape)
简化版的PatchEmbed如下:
class PatchEmbed(nn.Module):def __init__(self, patch_size=16, in_channel=3, emb_size=768):super(PatchEmbed, self).__init__()self.patch_embed_linear = nn.Sequential(# 将原始图片切分为16*16并将其拉平Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size),nn.Linear(patch_size * patch_size * in_channel, emb_size))def forward(self, x):x = self.patch_embed_linear(x)return x
除此之外,使用卷积操作也是可以的:
class PatchEmbedding(nn.Module):def __init__(self, in_channel=3, embed_dim=768, patch_size=16):super(PatchEmbedding, self).__init__()self.patch_embed_conv = nn.Sequential(# [b, 3, 224, 224]nn.Conv2d(in_channel, embed_dim, kernel_size=patch_size, stride=patch_size),# [b, 768, 14, 14]Rearrange('b c h w -> b (h w) c')# [b, 196, 768])def forward(self, x):x = self.patch_embed_conv(x)return x三、Attention机制
1.self-attention和MultiHeadAttention的区别
自注意力机制和多头注意力机制原理上几乎差不多,而二者的不同之处在于自注意机制是用一组QKV来使token获取上下文信息。
而由下图可知,多头注意力机制是使用多组QKV来让token得到多组的上下文信息,最后使用一个W0矩阵对得到的所有Zi进行整合。
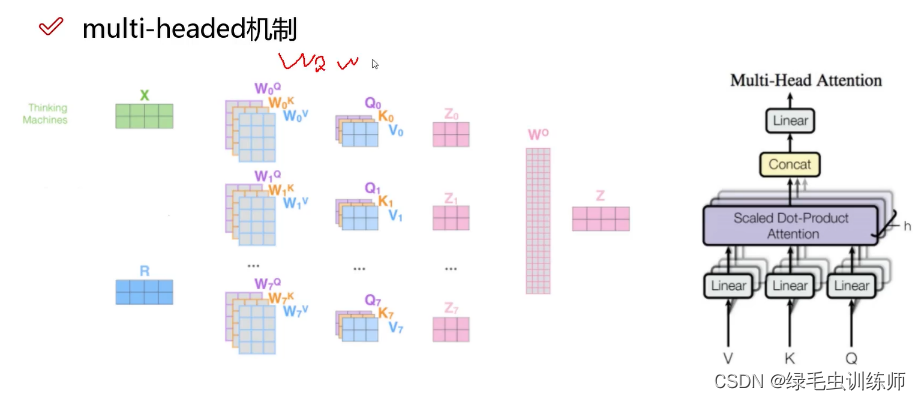
2.部分代码解释
在下面的完整代码中,有如下一行代码,刚好找到了图解,所以单独拿出来,以便于理解。
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
上面的代码可以用下图来理解,通过一次的全连接操作,就可以生成x的QKV矩阵

通过上图的解释,不难得出,该行代码可以用如下三行代码来替换:
self.q = nn.Linear(dim, dim)
self.k = nn.Linear(dim, dim)
self.v = nn.Linear(dim, dim)
对于代码中的参数qk_scale,记住这是公式中的根号dk就可以了。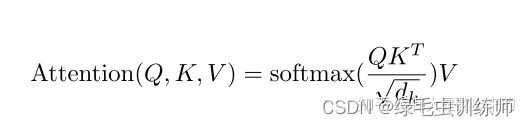
3.实现思想
代码在实现多头注意力机制的时候,使用了一次计算多组的方法,即多头所用的qkv,一次性生成,各组间的计算也是一次性通过矩阵计算的方式并行计算完成。
# 一次性生成
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
# 一次性计算
attn = (q @ k.transpose(-2, -1)) * self.scale # 计算相似度
x = (attn @ v).transpose(1, 2).reshape(B, N, C) # 计算注意力值
在这两行代码中,q、k、v代表的就是多组的qkv矩阵,通过一个矩阵计算的算式即可将每一组的qkv都计算出来。
4.完整代码解释
class Attention(nn.Module):# 在实现上多头注意实际上就是在单头的基础上增添num_heads个维度,且在最后输出attention时增加一个权重矩阵def __init__(self,dim, # 输入token的dim 768num_heads=8,qkv_bias=False, # 在生成qkv时是否使用偏置qk_scale=None, # q、k的缩放因子,保证内积计算不会受到向量长度的影响attn_drop_ratio=0,proj_drop_ratio=0):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // self.num_heads # 计算每一个head需要传入的dim 768/8=96self.scale = qk_scale or head_dim ** -0.5 # 若给定qk_scale则使用其作为缩放因子,若没给则使用后者self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)"""self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)目的:得到对应x的q、k、v矩阵,其中x是token_num个dim维的token组成的矩阵过程:x:[token_num, dim] 经过Linear层后得到矩阵 qkv[token_num, dim * 3]将qkv矩阵按dim进行拆分,就可以得到size为[token_num, dim]的q、k、v三个矩阵故该线性层可以拆分为:self.q = nn.Linear(dim, dim)self.k = nn.Linear(dim, dim)self.v = nn.Linear(dim, dim)新的理解:经过一个线性层,就是让输入矩阵乘一个[in_channel, out_channel]的矩阵如:x[token_num, dim] 经过 Linear(dim, dim*3) 就是乘一个[dim, dim*3]的矩阵,最后变成[token_num, dim*3]"""self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim) # 将每一个head的结果拼接的时候所乘的权重self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x): # x是经历了PatchEmbed后的xB, N, C = x.shape # 【B,N,C】:【B, 196, 768】 qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)"""输入x:[batch, N, C]1.self.qkv(x) : qkv:[B, N, 3*C]2.reshape() : qkv:[B, N, 3, self.num_heads, C // self.num_heads]3.permute(2, 0, 3, 1, 4) : qkv:[3, B, self.num_heads, N, C // self.num_heads]size说明:3:将qkv分为q、k、v三个矩阵 | q:[B, self.num_heads, N, C(dim)]B: 每个q/k/v矩阵都对应有B个batch | 单个q : [self.num_heads, N, C(dim)]self.num_heads : 在根据头数,将q/k/v划分为对应头数个矩阵 | 每个头:[N, C(dim)]: 反正就是将qkv划分为和输入x一致大小的矩阵"""q, k, v = qkv[0], qkv[1], qkv[2] # 【B,8,N,96】:【batch,8个头,N个词,每个词96维】attn = (q @ k.transpose(-2, -1)) * self.scale # 计算相似度"""q、k、v都是【B, 8, N, 96】的矩阵,就是多头注意力机制的多个qkv然后利用attn = (q @ k.transpose(-2, -1)) * self.scale公式让这多组q@k一次性计算出来x = (attn @ v).transpose(1, 2).reshape(B, N, C)也是一样的,通过一个公式将多组的 softmax(q@k)@v计算出来"""attn = attn.softmax(dim=-1) # 计算概率attn = self.attn_drop(attn)x = (attn @ v).transpose(1, 2).reshape(B, N, C) # 计算注意力值x = self.proj(x) # 乘最后的权重矩阵x = self.proj_drop(x)return x
这篇关于VIT中PatchEmbed、MultiHeadAttention代码详解(PyTorch)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





