patchembed专题
PatchEmbed
PatchEmbed 是用于计算机视觉任务的神经网络层,特别是在Vision Transformer (ViT) 模型中使用。它负责将输入的图像分割成固定大小的图像块(patches),并将这些图像块线性嵌入到高维空间中。这是Vision Transformer处理图像的方式,它不像传统的卷积神经网络那样使用卷积层,而是通过这种分割和嵌入的方式来处理图像。 具体来说,PatchEmbed 的过程包
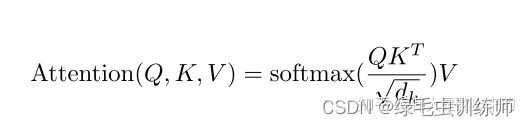
VIT中PatchEmbed、MultiHeadAttention代码详解(PyTorch)
本文对PatchEmbed和MulitHeadAttention进行代码的详细解读,希望可以给同样被此处困扰的小伙伴提供一些帮助,如有错误,还望指正。 文章目录 一、VIT简单介绍二、PatchEmbed1.PatchEmbed的目的2.代码的执行过程3.注意4.完整代码解释5.代码简化版 三、Attention机制1.self-attention和MultiHeadAttention的区