单张专题

单张图片上传表单提交
freemarker <!DOCTYPE html><html lang="zh-cn" class="hb-loaded"><head><title>简洁大气快速登录注册模板</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"><script type="text/javascript"
freemarker+springMVC+ajaxfileupload实现异步图片上传(单张)
第一步:下载JQuery的JS文件ajaxfileupload.js 并引入到freemarker 第二步:freemarker页面 <span style="font-size:18px;"><!DOCTYPE html><html lang="zh-cn" class="hb-loaded"><head> <meta http-equiv="pragma" content=

【稀疏三维重建】Flash3D:单张图像重建场景的GaussianSplitting
项目主页:https://www.robots.ox.ac.uk/~vgg/research/flash3d/ 来源:牛津、澳大利亚国立 提示: 文章目录 摘要1.引言2.相关工作3.方法3.1 背景:从单个图像中重建场景3.2 单目 4.实验4.14.2 跨域新视角合成4.3 域内新视图合成4.4 域内新视图合成 摘要 Flash3D,一种通用的单一图像场景重建。

单张图像扩散模型(Single Image DIffusion Model)
论文:SinDDM: A Single Image Denoising Diffusion Model, ICML 2023 去噪扩散模型(DDM)在图像生成、编辑和恢复方面带来了惊人的性能飞跃。然而,现有DDM使用非常大的数据集进行训练。在这里,介绍一个用于在单个图像上训练DDM的框架。SinDDM,通过使用多尺度扩散过程来学习训练图像的内部统计信息。为了驱动反向扩散过程,使用了一个完全卷积的
把COCO数据集的josn标注转变成VOC数据集xml格式的标注;json数据标注转xml数据标注;把coco数据集json格式转变单张图片对应的xml格式
主要是以目标检测为列进行的 COCO数据集json格式样本 {"info": {"description": "COCO 2017 Dataset","url": "http://cocodataset.org","version": "1.0","year": 2017,"contributor": "COCO Consortium","date_created": "2017/09/01"

【class9】人工智能初步(处理单张图片)
Class9的任务:处理单张图像 为了更高效地学习,我们将“处理单张图像”拆分成以下几步完成: 1. 读取图像文件 2. 调用通用物体识别 3. 提取图像分类信息 4. 对应分类文件夹还未创建时,创建文件夹 5. 移动图像到对应文件夹 0.获取了图像路径 整理清楚解决问题的思路以后,我们开始获取图像路径。我们直接从铭铭的文件夹'img'中选出一张图像'cat.jpg'。它的路径可以表示为 '
一举颠覆Transformer!最新Mamba结合方案刷新多个SOTA,单张GPU即可处理140k
还记得前段时间爆火的Jamba吗? Jamba是世界上第一个生产级的Mamba大模型,它将基于结构化状态空间模型 (SSM) 的 Mamba 模型与 transformer 架构相结合,取两种架构之长,达到模型质量和效率兼得的效果。 在吞吐量和效率等关键衡量指标上,Jamba处理128k长上下文时吞吐量是 Mixtral 8x7B的3倍;在成本上,Jamba一共支持256k上下文,单张
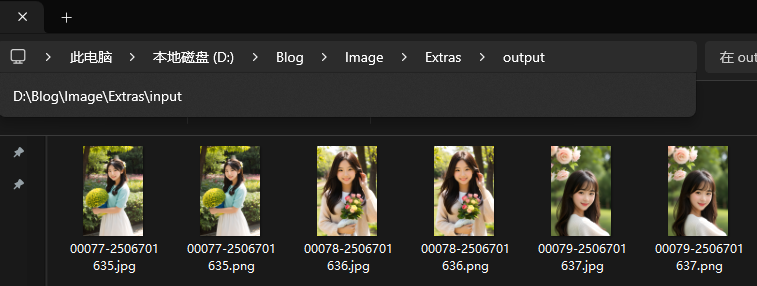
Stable Diffusion WebUI 附加功能/图片放大(Extras):单张图片/批量处理/从目录进行批量处理
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 大家好,我是水滴~~ 篇文章主要讲解 Stable Diffusion WebUI 的附加功能/图片放大(Extras)的使用,主要包括:单张图片、批量处理、从目录进行批量处理。文章中包含大量的图片和示例,非常适合新手同学,希望对你有所帮助! 文章目录 一、单张图像1. 来源(Sourc

mmclassification单张图像训练在prompt成功而在pycharm报错找不到mmcls的解决方法
在mmclassification环境配置好后进行图像分类单张图片预训练测试 我这里单张图像训练教程参考链接如下: https://blog.csdn.net/Stone_hello/article/details/117025082?spm=1001.2014.3001.5506 在模型下载好,配置文件写好后,在prompt命令行里输入: conda activate mmcls(mmc

Stability AI发布Stable Video 3D模型:可从单张图像创建多视图3D视频,视频扩散模型史诗级提升!
Stability AI发布了Stable Video 3D (SV3D),这是一种基于稳定视频扩散的生成模型,推动了3D技术领域的发展,并大大提高了质量和视图一致性。 该版本有两个版本: SV3D_u:该变体基于单图像输入生成轨道视频,无需相机调节。 SV3D_p:扩展SVD3_u的功能,此变体可容纳单图像和轨道视图,允许沿着指定的相机路径创建3D视频。 Stable Vid

caffe+python 使用训练好的VGG16模型 对 单张图片进行分类,输出置信度
网上看了一堆都是图片转lmdb格式,然后测试总的准确率,我想测试每张图片的top1,top2以及对应置信度是多少,摸索了一下午+一晚上终于搞定,期间遇到不少坑!!!同时感谢实验室博士师兄一块帮我找bug 说明:数据集是上海BOT大赛的(12种动物),网上下载的vgg16权重文件,并且修改输出类别为12,对最后三层全连接网络训练了8个小时,top1准确率为80%,top5准确率95% 使用的测试
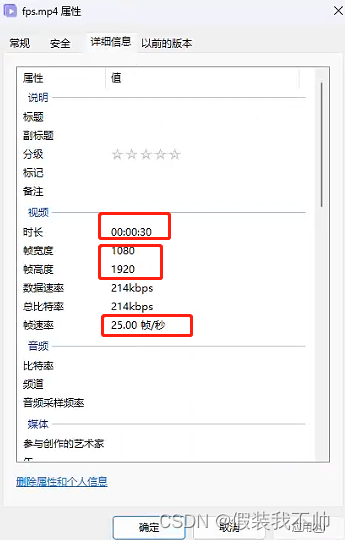
ffmpeg单张图片生成固定时长的视频
ffmpeg -r 25 -f image2 -loop 1 -i fps_1.jpg -vcodec libx264 -pix_fmt yuv420p -s 1080*1920 -r 25 -t 30 -y fps.mp4 这个命令将 fps_1.jpg 图片转换为一个 30 秒长的视频,分辨率为 1920x1080,帧率为 25 帧/秒,并使用 libx264 编码器进行压缩。 -r 2
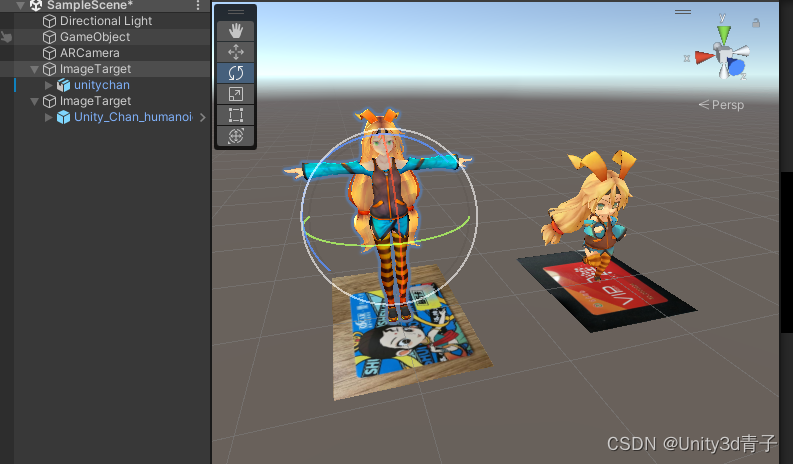
【Vuforia+Unity】01实现单张多张图片识别产生对应数字内容
1.官网注册 Home | Engine Developer Portal 2.下载插件SDK,导入Unity 3.官网创建数据库上传图片,官网处理成数据 下载好导入Unity! 下载好导入Unity! 下载好导入Unity! 下载好导入Unity! 4.在Unity设置 开始创建场景 选择数据库,

【从单张图像解锁深度信息】Depth Anything一种用于鲁棒单目深度估计的高度实用的解决方案
Depth Anything是一种用于鲁棒单目深度估计的高度实用的解决方案。 在不追求新颖的技术模块的情况下,我们的目标是建立一个简单而强大的基础模型,处理任何情况下的任何图像。 为此,我们通过设计数据引擎来收集并自动注释大规模未标记数据(~62M)来扩展数据集,这显着扩大了数据覆盖范围,从而能够减少泛化误差。 我们研究了两种简单而有效的策略,使数据扩展前景光明。 首先,利用数据增强工具创建更

港大与TikTok合作研发Depth Anything,从单张图像解锁深度信息,引领MDE新纪元
单目深度估计:挑战与机遇 单目深度估计(MDE)在机器人、自动驾驶、虚拟现实等领域中具有广泛的应用。然而,由于其依赖于精确的深度信息,且面临着数据集构建困难、样本标注成本高等挑战,使得MDE技术的发展步伐受限。 Depth Anything的技术创新 由香港大学和TikTok合作研发的Depth Anything模型在MDE领域是一次重要突破。该模型的创新之处在于有效利用了大规模

ImageNet预训练图像分类模型预测单张图像
导入基础工具包 import osimport cv2import pandas as pdimport numpy as npimport torchimport matplotlib.pyplot as plt%matplotlib inline 计算设备确定 # 有 GPU 就用 GPU,没有就用 CPUdevice = torch.device('cuda:0' if torc
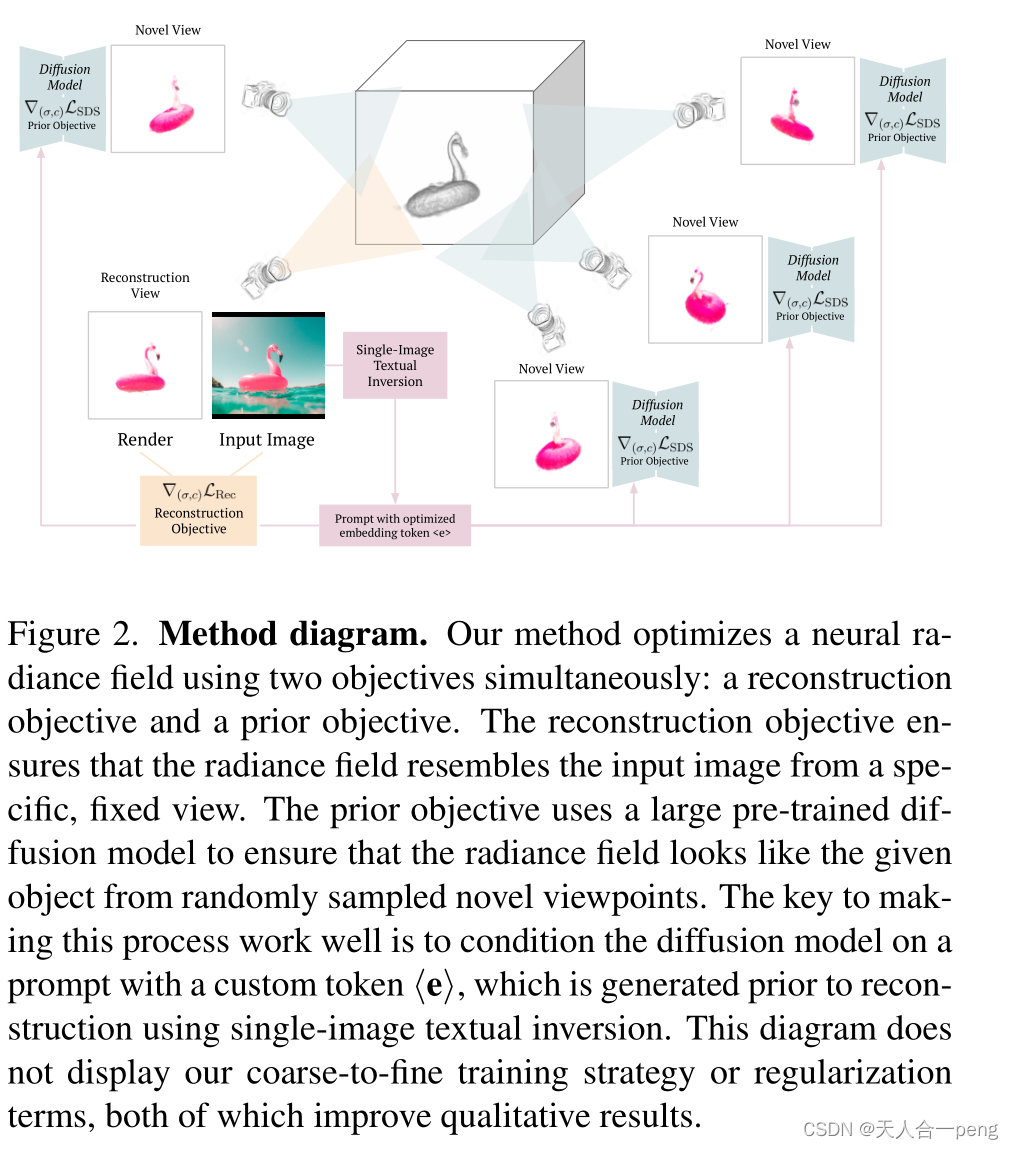
单张图像三维重建RealFusion 360◦ Reconstruction of Any Object from a Single Image
Luke Melas-Kyriazi, Iro Laina, Christian Rupprecht, Andrea Vedaldi.RealFusion 360◦ Reconstruction of Any Object from a Single Image。RealFusion: 360° Reconstruction of Any Object from a Single Image

CVPR 2022最佳学生论文:单张图像估计物体在3D空间中的位姿估计
©作者 | 陈涵晟 单位 | 同济大学、阿里达摩院 来源 | 机器之心 距离 CVPR 2022 各大奖项公布没多久,来自同济大学研究生、阿里达摩院研究型实习生陈涵晟为我们解读最佳学生论文奖。 本文解读我们获得 CVPR 2022 最佳学生论文奖的工作。论文研究的问题是基于单张图像估计物体在 3D 空间中的位姿。现有方法中,基于 PnP 几何优化的位姿估计方法往往通过深度网络提取 2D-3D

uniapp+uview封装上传图片组件(单张/多张)
uniapp+uview封装上传图片组件(单张/多张) 先看效果 1.uploadImg.vue <template><view class="uploadImg flex-d flex-wrap"><!-- 多张图片上传 --><view class="imgList imgArr flex-d flex-wrap" v-for="(item,index) in fileList" :k

【数字人】11、DERAM-TALK | 使用扩散模型实现 audio+单张图的带表情驱动(字节跳动)
论文:DREAM-Talk: Diffusion-based Realistic Emotional Audio-driven Method for Single Image Talking Face Generation 项目:https://magic-research.github.io/dream-talk/ 代码:暂无 出处:字节 时间:2023.12 效果: 使用扩散模
判断单张图片是否存在重叠部分的常见方法
Python-判断单张图片中是否存在重叠部分的常见方法通常包括以下几种: 使用边缘检测和轮廓发现 像上面提到的那样,你可以使用OpenCV库中的边缘检测(如Canny算法)和轮廓发现函数findContours,利用轮廓层级关系来判断是否有重叠。特征匹配 这适用于需要检测图像中相似对象重叠的情况。可以通过SIFT、SURF或ORB等特征点检测和描述算子兼已知模式匹配的方法来识别重叠部分。模板匹配

OpenCV图像数据处理——python将单张图片裁剪为若干份存入文件夹,将多张图片裁剪为若干份存入多个文件夹,代码
目录 1.将单张图片裁剪为若干份存入文件夹 2.将多张图片裁剪为若干份存入多个文件夹 1.将单张图片裁剪为若干份存入文件夹 核心代码(将单张图片进行裁剪的算法) 以裁剪为60*60的图片为例 import cv2import os# 需要裁剪的图片路径filename = 'D:/resource_photo/1.jpg'# 读取图片img = cv2.imre
第60篇一对多之学生端私有白板图片保存及学生传数组过去不再单张传周三
关键词:学生端私有白板图片保存,学生传数组过去不再单张传 一、私有白板向老师端传图片数据 1.1 服务器运行平台 老师端:https://localhost:9101/demos/index.html?roomid=888&t=600 学生一: https://localhost:9101/demos/student.html?studentId=1001&userAvatar=http

【AIGC-图片生成视频系列-4】DreamTuner:单张图像足以进行主题驱动生成
目录 一. 项目概述 问题: 解决: 二. 方法详解 a) 整体结构 b) 自主题注意力 三. 文本控制的动漫角色驱动图像生成的结果 四. 文本控制的自然图像驱动图像生成的结果 五. 姿势控制角色驱动图像生成的结果 2023年的最后一天,发个文记录下。马上就要迎来新的一年,在这里预祝各位读者新年新气象! 今天要介绍的是字节的DreamTuner: Single Ima

单张图像3D重建:原理与PyTorch实现
近年来,深度学习(DL)在解决图像分类、目标检测、语义分割等 2D 图像任务方面表现出了出色的能力。DL 也不例外,在将其应用于 3D 图形问题方面也取得了巨大进展。 在这篇文章中,我们将探讨最近将深度学习扩展到单图像 3D 重建任务的尝试,这是 3D 计算机图形领域最重要和最深刻的挑战之一。 在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/G

【yolov5改编系列之一】yolov5-6.0中detect.py检测单张图片,官方文档内容太多,看着眼花缭乱,我直接给它删掉一大堆。
引言 各位同仁大家好,网上的资源众多但是感觉用起来有点麻烦,干脆自己整理一下。 yolov5官方的detect.py文件集成度比较高。一般情况下我们不需要同时实现这么多的功能,比如:检测图像、视频、摄像头等,包括支持pytorch、tensorflow等模型框架。 本节内容是基于yolov5-6.0的detect.py文件改写的。我相信也适用于相近的yolov5版本。 本节代码功能支撑:w