本文主要是介绍单张图像三维重建RealFusion 360◦ Reconstruction of Any Object from a Single Image,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Luke Melas-Kyriazi, Iro Laina, Christian Rupprecht, Andrea Vedaldi.RealFusion 360◦ Reconstruction of Any Object from a Single Image。RealFusion: 360° Reconstruction of Any Object from a Single Image

Abstract
We consider the problem of reconstructing a full 360◦
photographic model of an object from a single image of it.
We do so by fitting a neural radiance field to the image,
but find this problem to be severely ill-posed. We thus take
an off-the-self conditional image generator based on diffu-
sion and engineer a prompt that encourages it to “dream
up” novel views of the object. Using the recent DreamFu-
sion method, we fuse the given input view, the conditional
prior, and other regularizers in a final, consistent recon-
struction. We demonstrate state-of-the-art reconstruction
results on benchmark images when compared to prior meth-
ods for monocular 3D reconstruction of objects. Qualita-
tively, our reconstructions provide a faithful match of the
input view and a plausible extrapolation of its appearance
and 3D shape, including to the side of the object not visible in the image.
1. Introduction
The alternative to training a 3D diffusion model is to ex-
tract 3D information from an existing 2D model. A 2D im-
age generator can in fact be used to sample or validate mul-
tiple views of a given object; these multiple views can then
be used to perform 3D reconstruction.
In this paper, we study this problem in the context of
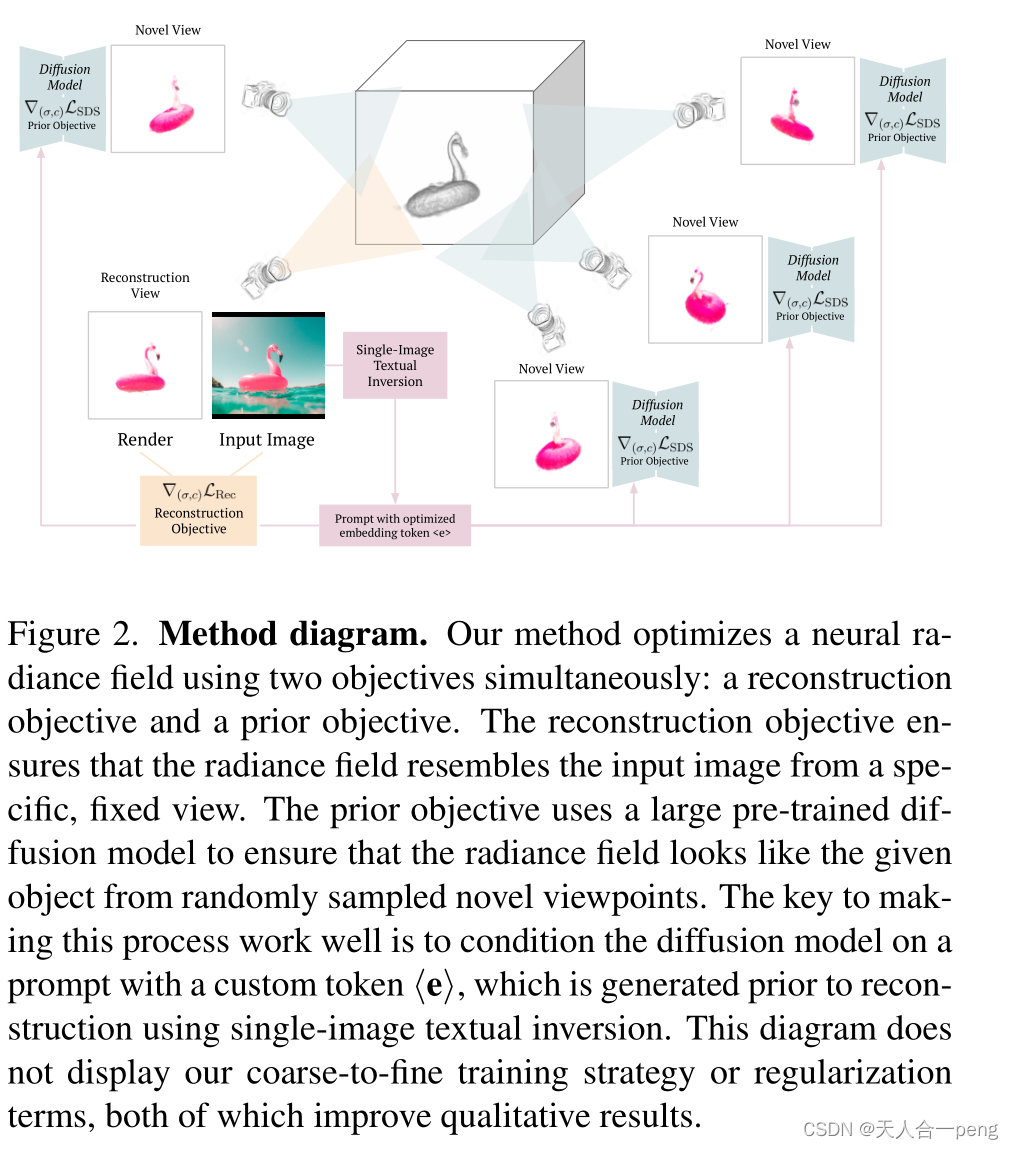
diffusion models. We express the object’s 3D geometry and
appearance by means of a neural radiance field. Then, we
train the radiance field to reconstruct the given input image
by minimizing the usual rendering loss. At the same time,
we sample random other views of the object, and constrain
them with the diffusion prior, using a technique similar to
DreamFusion
To summarize, we make the following contributions:
(1) We propose RealFusion, a method that can extract from
asingle image of an object a 360◦ photographic 3D recon-
struction without assumptions on the type of object imaged
or 3D supervision of any kind; (2) We do so by leveraging
an existing 2D diffusion image generator via a new single-
image variant of textual inversion; (3) We also introduce
new regularizers and provide an efficient implementation
using InstantNGP; (4) We demonstrate state-of-the-art re-
construction results on a number of in-the-wild images and
images from existing datasets when compared to alternative
approaches.
这篇关于单张图像三维重建RealFusion 360◦ Reconstruction of Any Object from a Single Image的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






