本文主要是介绍【AIGC-图片生成视频系列-4】DreamTuner:单张图像足以进行主题驱动生成,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一. 项目概述
问题:
解决:
二. 方法详解
a) 整体结构
b) 自主题注意力
三. 文本控制的动漫角色驱动图像生成的结果
四. 文本控制的自然图像驱动图像生成的结果
五. 姿势控制角色驱动图像生成的结果
2023年的最后一天,发个文记录下。马上就要迎来新的一年,在这里预祝各位读者新年新气象!
今天要介绍的是字节的DreamTuner: Single Image is Enough for Subject-Driven Generation,可以通过单张图像实现特定主题的驱动生成。
一. 项目概述
什么是主题驱动生成?使用一张或几张参考图像生成定制概念的个性化应用。
问题:
-
现有的基于微调的方法需要在主题学习和维护预训练模型的生成能力之间进行权衡,个人理解是模型特化和泛化的权衡。
-
基于附加图像编码器的其他方法往往由于编码压缩而丢失主题的一些重要细节。
解决:
文中提出了 DreamTurner,这是一种从粗到细注入定制主题的参考信息的新颖方法。
-
首先提出了一种用于粗略主题身份保留的主题编码器,其中在视觉文本交叉注意之前通过附加注意层引入压缩的一般主题特征。
-
然后,我们将预训练的文本到图像模型中的self-attention修改为self-subject-attention层,以细化目标主体的细节。值得强调的是,self-subject-attention是一种优雅、有效、免训练的方法,用于维护定制概念的详细特征,可以在推理过程中用作即插即用的解决方案。
-
最后,通过仅对单个图像进行额外的微调,DreamTurner 在由文本或姿势等其他条件控制的主题驱动图像生成方面取得了卓越的性能。

二. 方法详解
DreamTuner 作为一种基于微调和图像编码器的主题驱动图像生成的新颖框架,它保持从粗到细的主题身份。
DreamTuner由三个阶段组成:主题编码器预训练、主题驱动微调和主题驱动推理。
-
首先,训练主题编码器以进行粗略的身份保留。主题编码器是一种图像编码器,为生成模型提供压缩图像特征。冻结的 ControlNet 用于解耦内容和布局。
-
然后我们在参考图像和一些生成的常规图像上微调整个模型,如 DreamBooth 中一样。请注意,主题编码器和自主题注意力用于常规图像生成以细化常规数据。
-
在推理阶段,通过微调获得的主题编码器、自身主题注意力和主题词[S*]用于从粗到细地进行主题身份保留。预训练的 ControlNet 还可用于布局控制生成。
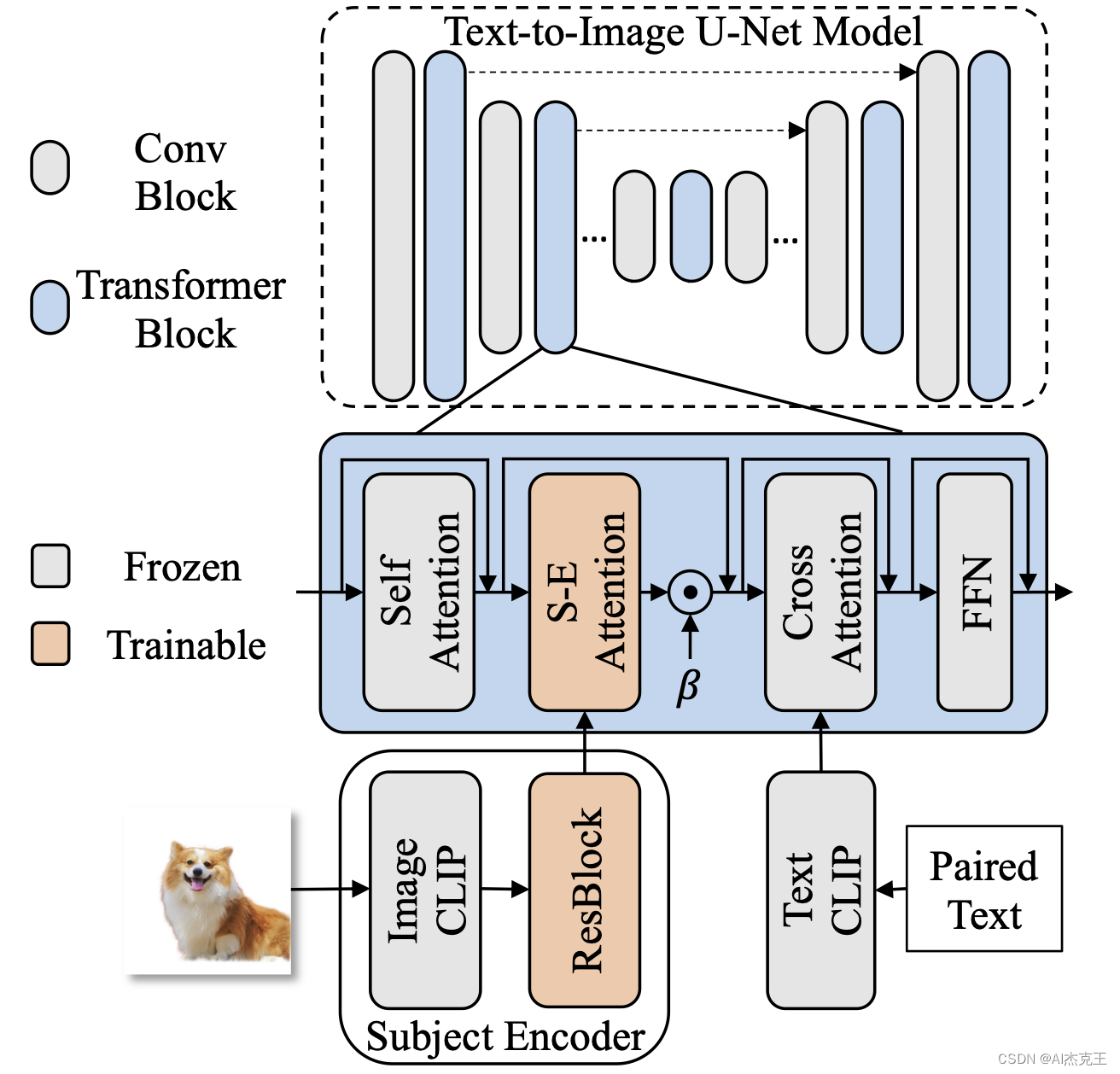
a) 整体结构

-
提出的主题编码器作为一种图像编码器,为主题驱动生成提供粗略参考。使用冻结的 CLIP 图像编码器来提取参考图像的压缩特征。使用显著对象检测(SOD)模型或分割模型来去除输入图像的背景并强调主题。
-
然后引入一些残差块(ResBlock)进行域移位。CLIP提取的多层特征在通道维度上cat操作,然后通过残差块调整到与生成特征相同的维度。使用附加的主题编码器注意(SEA)层将主题编码器的编码参考特征注入到文本到图像模型中。主题编码器注意层添加在视觉文本交叉注意之前,因为交叉注意层是控制生成图像的总体外观的模块。
-
根据与交叉注意力相同的设置构建主题编码器注意力,并将输出层初始化为零。附加系数β引入来调整主题编码器的影响。
-
此外,进一步引入ControlNet来帮助解耦内容和布局。具体来说,我们训练主题编码器和冻结深度 ControlNet。由于ControlNet提供了参考图像的布局,主题编码器可以更加关注主题内容。
b) 自主题注意力
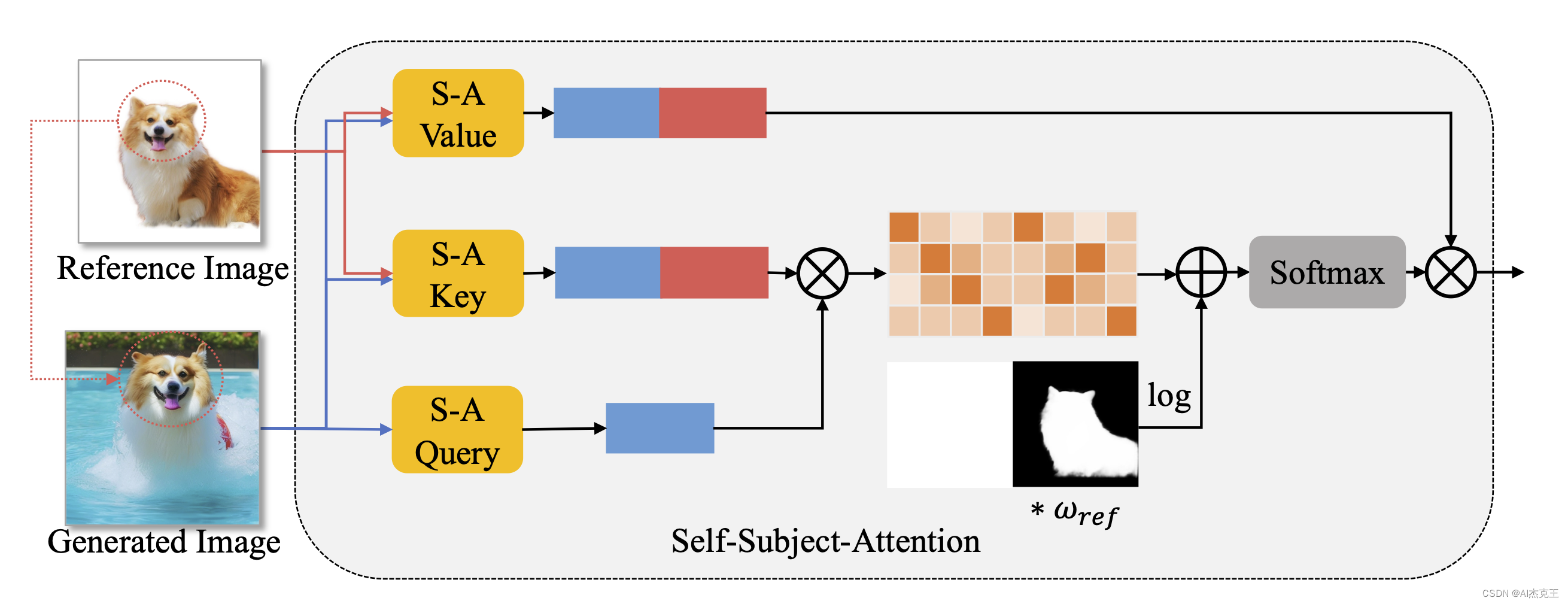
-
由于主题编码器为生成过程提供了特定主题的一般外观,因此进一步提出基于原始自注意力层的自主题注意力,以实现良好的主题身份保存。
-
将预训练的文本到图像 U-Net 模型提取的参考图像的特征注入到自注意力层中。
-
参考特征可以提供精细且详细的参考,因为它们与生成图像的特征共享相同的分辨率。具体来说,在每个时间步长通过扩散前向过程对参考图像进行噪声处理t。
-
然后从噪声参考图像中提取每个自注意力层之前的参考特征,这些特征与时间步长生成的图像特征共享相同的数据分布。
-
利用参考特征将原始的自注意力层修改为自主题注意力层。将生成图像的特征作为查询,并将生成图像特征和参考图像特征的进行cat操作作为键和值。
-
为了消除参考图像背景的影响,使用显著对象检测(SOD)模型创建前景掩模,其中使用0和1来指示背景和前景。
-
此外,掩模还可以通过权重策略来调整参考图像影响的大小,即掩模乘以调整系数, 起到注意偏差的作用,因此使用对数函数作为预处理。
将原来的分类器免引导方法也修改为:
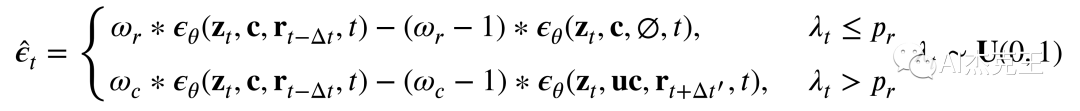
第一个方程强调参考图像的引导,第二个方程强调条件的引导,用概率控制选择第一个或者第二个的可能性。
三. 文本控制的动漫角色驱动图像生成的结果
结果显示了专注于动漫角色的文本控制的主题驱动图像生成的输出。
局部编辑结果(例如第一行的表达式编辑)和全局编辑结果(包括后续五行的场景和动作编辑),即使输入复杂的文本也能产生高度详细的图像。值得注意的是,图像准确地保留了参考图像的细节。


四. 文本控制的自然图像驱动图像生成的结果
该方法在 DreamBooth 数据集上进行评估,其中每个主题的一张图像用作参考图像。通过使用主题编码器和自我主题注意力,生成精确的参考。
这使得 DreamTuner 能够成功生成与文本输入一致的高保真图像,同时还保留关键的主题细节,包括但不限于、小狗头上的白色条纹、包上的徽标、罐头上的图案和文字。


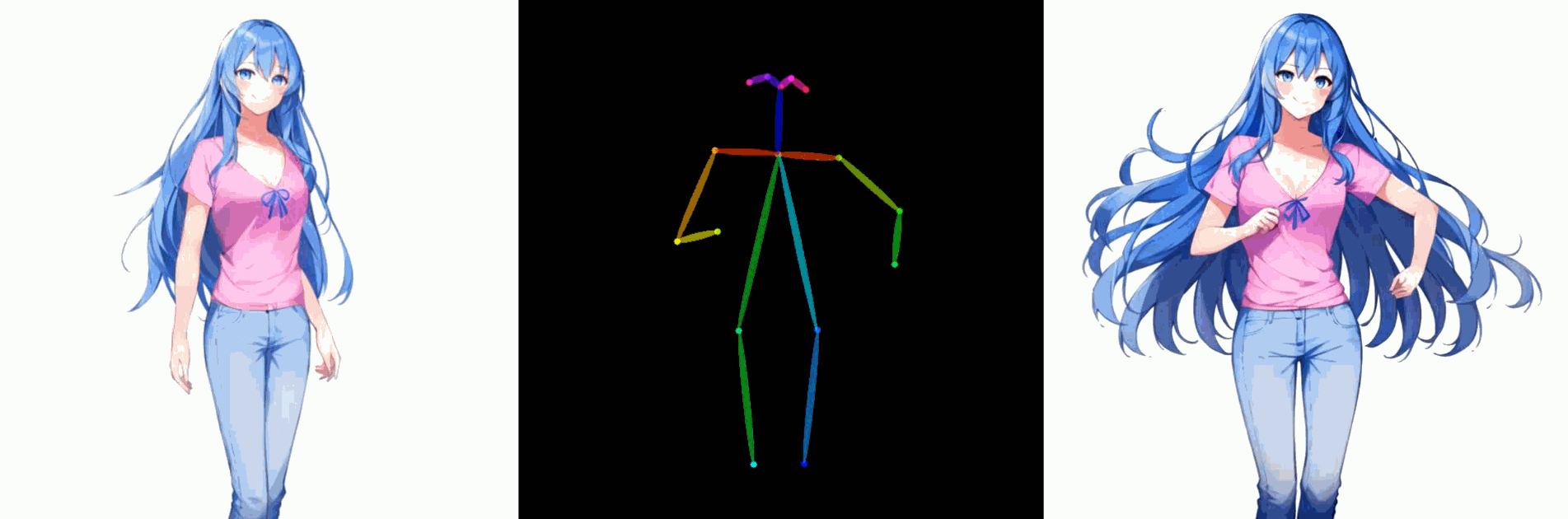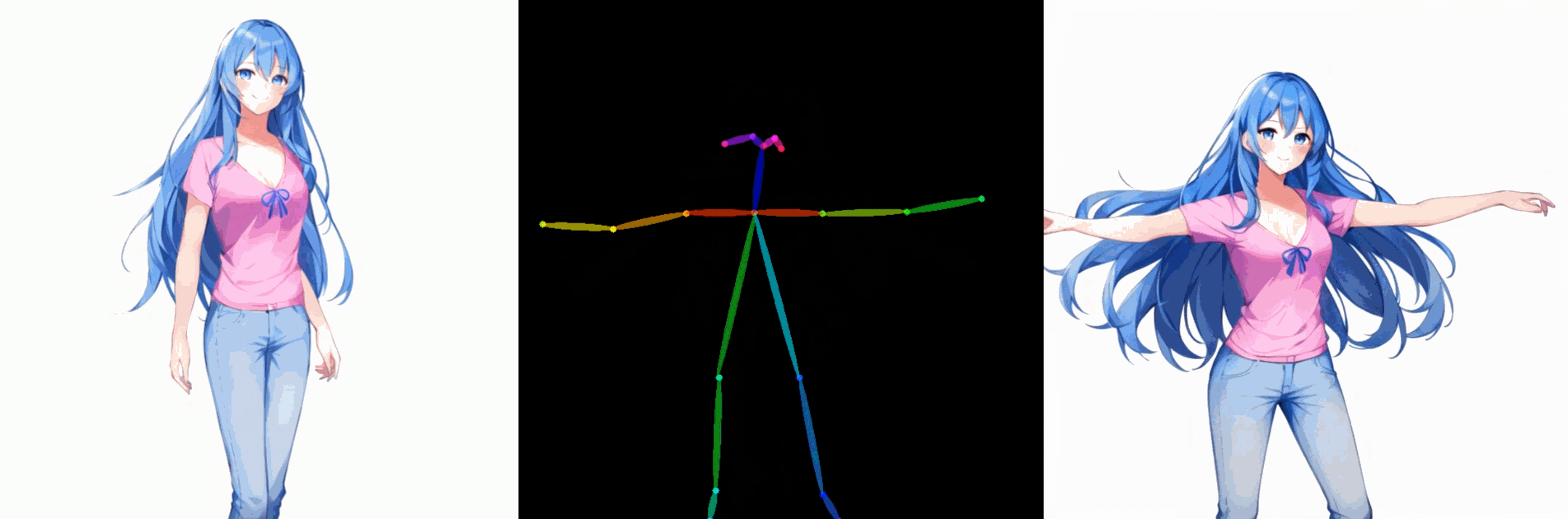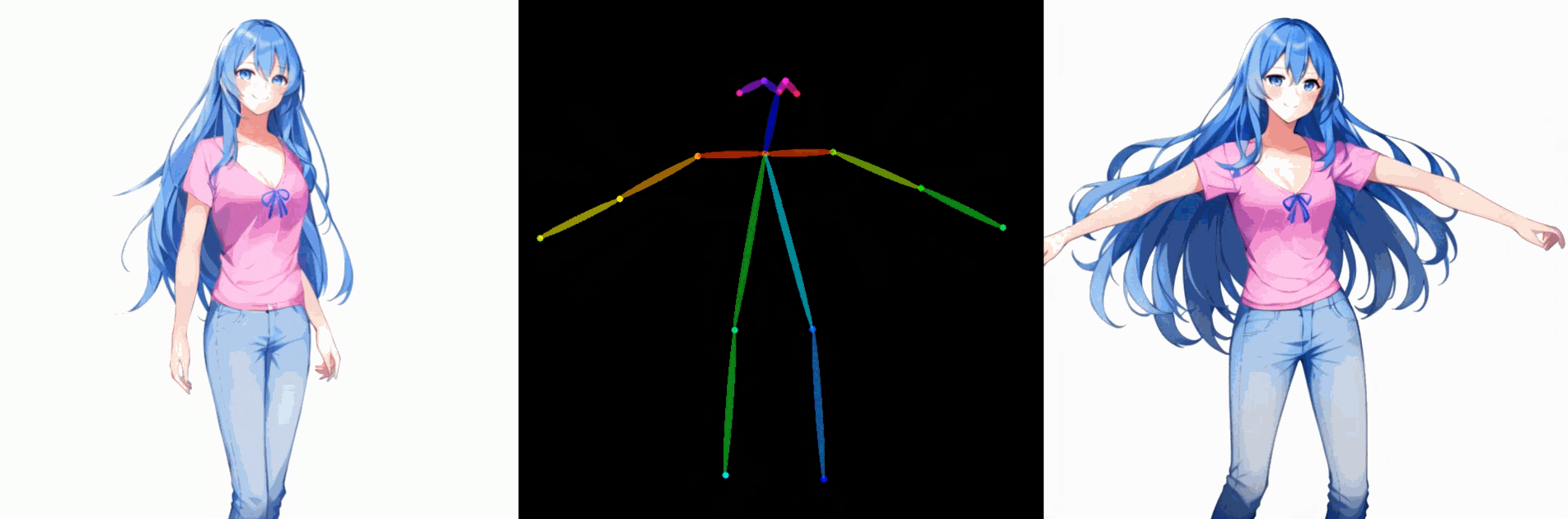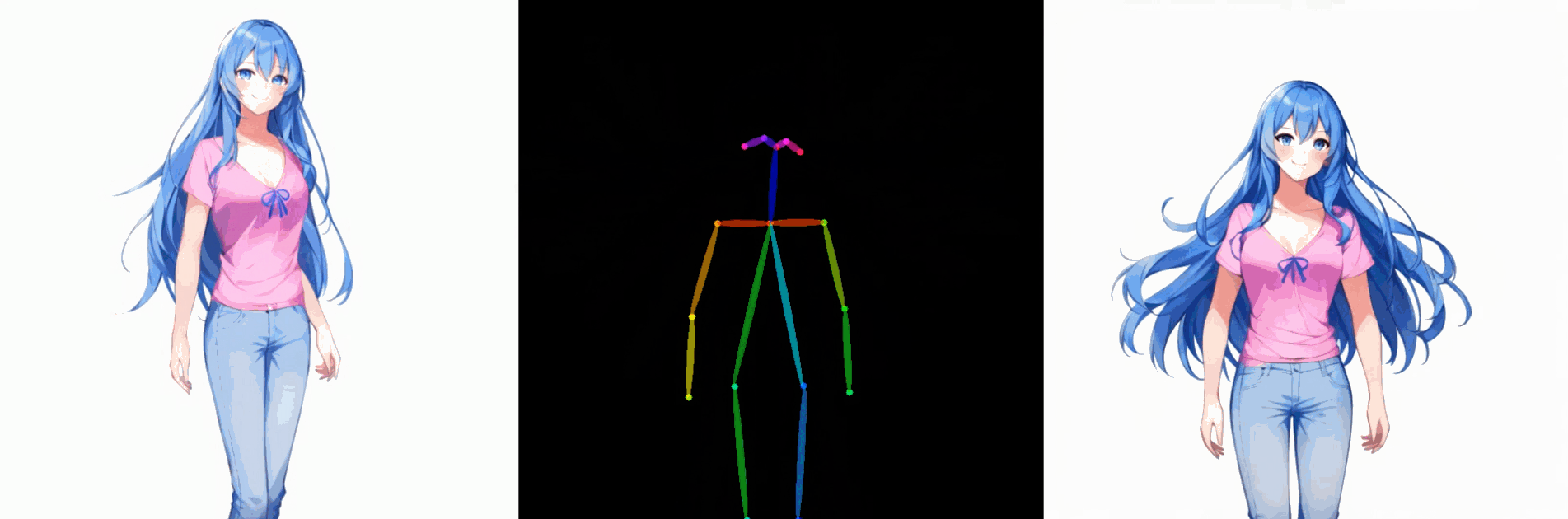
五. 姿势控制角色驱动图像生成的结果
该方法可以与 ControlNet 相结合,将其适用性扩展到各种条件,例如姿势。在下面的示例中,仅使用一张图像进行 DreamTuner 微调,并使用参考图像的姿态作为参考条件。为了保证帧间的一致性,参考图像和生成图像的前一帧都用于自我注意力,参考权重分别为10和1。
欢迎加入AI杰克王的免费知识星球,海量干货等着你,一起探讨学习AIGC!

这篇关于【AIGC-图片生成视频系列-4】DreamTuner:单张图像足以进行主题驱动生成的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




