本文主要是介绍【稀疏三维重建】Flash3D:单张图像重建场景的GaussianSplitting,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目主页:https://www.robots.ox.ac.uk/~vgg/research/flash3d/
来源:牛津、澳大利亚国立
提示:
文章目录
- 摘要
- 1.引言
- 2.相关工作
- 3.方法
- 3.1 背景:从单个图像中重建场景
- 3.2 单目
- 4.实验
- 4.1
- 4.2 跨域新视角合成
- 4.3 域内新视图合成
- 4.4 域内新视图合成
摘要
Flash3D,一种通用的单一图像场景重建。模型从一个单目深度估计的“基础”模型开始,扩展到一个完整的三维形状和外观重建器。为了高效,基于前向的GS进行扩展。具体的,模型预测了深度图表面的第一层GS,然后添加一层空间中的额外的高斯偏移,允许模型完成遮挡和截断后的重建。Flash3D高效,只需在单一GPU上训练一天。训练和测试在 RealEstate10k数据集上。当转移到NYU和KITTI的未知数据集时,其表现远优于竞争对手。
1.引言
深度估计器只能预测最近的可见表面的三维形状,它们不提供任何外观信息,也不提供场景的遮挡或帧外部分的估计。仅凭深度不足以准确地解决诸如新视图合成(NVS)等任务,这还需要建模看不见的区域和视图依赖的外观。
这里,我们的场景重建也可以受益于建立一个现有的基础模型,但选择一个单眼深度预测器作为一个更自然的选择:通过建立在一个高质量的深度预测器[UniDepth:CVPR 2024]上,实现了对新数据集的优秀泛化,以至于我们的3D重建比那些专门在这些测试领域上训练的模型更准确。
其次,本文改进了单目场景重建的前馈逐像素GS。如上所述,应用于单个对象,每个像素的重建器可以使用背景像素的库来建模对象的隐藏部分,这在重建整个场景时是不可能的。本文预测每个像素的多个高斯分布,其中沿着每条射线的第一个高斯分布被鼓励符合深度估计,从而对场景的可见部分进行建模。这类似于[1,3,36,58,74,76][9]中的分层表示[1,3,36,58,74,76]和多高斯采样。然而,在我们的例子中,高斯分布是确定性的,并不局限于特定的深度范围,并且该模型可以自由地将高斯分布偏离射线来模拟场景中被遮挡或截断的部分。
总的来说,Flash3D是一个简单且性能高的单目场景重建模型:
( a ) 渲染重建的三维场景的高质量图像,
( b ) 在室内和室外的各种场景上操作;
( c ) 重建遮挡区域
Flash3D在RealEstate10K数据集上的所有指标上实现了最先进的新视图合成精度
2.相关工作
2.1 Monocular feed-forward reconstruction
单目前馈重建器的工作原理是通过神经网络传递场景的单个图像,从而直接输出三维重建。对于场景,[Single-view view synthesis with multiplane images 74-76等]和MINE [36]通过使用神经辐射场,预测多平面图像(速度、泛化性较差); SynSin [84]使用一个单目深度预测器来重建一个场景;然而,它的重建是不完整的,需要一个渲染网络来改进最终的新视图。对于单个对象,一个显著的例子就是(LRM),它获得了高质量的单目重建,但模型的规模和训练成本巨大。与我们最相关的工作是Splatter Image(CVPR 2024),它使用GS来提升效率。我们的方法也使用GS作为表示,但对于场景而不是对象。
2.2 Few-view feed-forward reconstruction
早期的例子使用神经辐射场(NeRF)[43]作为物体[12,25,29,38,51,79,92]和场景[12,14,88]的3D表示。这些方法隐式地学习在视图之间的点的匹配;[MVSNeRF和93]的工作使点匹配更加明确。其他方法将对象的三维形状估计为一个opacity field,但另一种选择是直接预测场景的新视图[44,55,65,66],而没有明确的体积重建,这是由光场网络[63]开创的一个概念。其他方法则从稀疏视角和narrow baseline stereo pairs [64, 72] 中使用替代的 multi-plane images。与我们的方法更相关的是pixelSplat [9], latentSplat [83] 和 MVSplat:从一对图像中重建场景。他们利用交叉视图的注意力来有效地共享信息和预测高斯混合物来表示场景几何。其他最近的前馈方法[69,89,95]结合LRM和高斯溅射从少量的图像重建。我们解决的是单眼重建,这是一个更困难的问题,因为缺乏来自三角测量的几何线索。
2.3 Iterative reconstruction。
基于迭代或优化的方法通过迭代拟合一个或多个图像的三维模型来重建它们。由于它们的迭代性质,以及需要渲染3D模型以使其适合于数据,通常比前馈方法要慢得多。DietNeRF [28]使用语言模型进行规则重建,RegNeRF [45]和RefNeRF [77]使用手工制作的规则重建器,而SinNeRF [87]使用单眼深度。RealFusion [40]使用图像扩散模型作为基于slow score distillation sampling迭代[49]的单目重建的先验。许多后续工作[70,86]都采取了类似的路径。使用多视图感知生成器[23,37,41,73,82,97]可以提高收敛速度和鲁棒性。Viewset Diffusion [67] 和 RenderDiffusion[2]等方法将三维重建与基于扩散的生成相融合,可以减少但不消除迭代生成的成本。相比之下,我们的方法是前馈的,速度接近实时(10fps)。有些方法以前馈的方式生成新的视图,但通过迭代和自回归,一次一个视图。例如PixelSynth [52], extending SynSin, GeNVS [8], 和Text2Room [26]。
2.4 Monocular depth prediction。
Flash3D基于单目深度估计[4,6,7,15,16,20,21,33,34,46,50,56,59,90,98],预测图像中每个像素的metrics或相对深度。通过从大型数据集学习视觉深度线索,通常是自监督,证明了较高的准确性和跨数据集进行概括的能力。实验中使用了一种最先进的度量深度估计器:UniDepth(CVPR 2024)。
3.方法
设 I I I∈ R 3 × H × W R^{3×H×W} R3×H×W 是一个场景的RGB图像。我们的目标是学习一个神经网络Φ,它以 I I I作为输入,并预测场景的3D内容的表示 G G G = Φ ( I ) Φ(I) Φ(I),包含了三维几何和光学。
3.1 背景:从单个图像中重建场景
表示:将场景作为三维高斯的集合。场景表示为: G G G = {( σ i σ_i σi, µ i µ_i µi, Σ i Σ_i Σi, c i c_i ci)} i = 1 G ^G_{i=1} i=1G。 c i ci ci: S 2 S^2 S2→ R 3 R^3 R3是每个部分的辐射函数(带方向的颜色)。 g i ( x ) g_i (x) gi(x) = exp ( − 1 2 (-\frac {1}{2} (−21( x − µ i ) T x-µ_i)^T x−µi)T Σ i − 1 Σ_i^{-1} Σi−1( x − µ i ) ) x-µ_i)) x−µi))是相应的(未归一化)高斯函数。
3.2 单目
为了泛化,=在=大量数据训练的高质量的预训练模型上构建Flash3D。=考虑到单目场景重建和单目深度估计之间的相似性,使用一个现成的单目深度预测器 Ψ Ψ Ψ:返回一个深度映射 D = Ψ ( I ) D = Ψ(I) D=Ψ(I),其中 D ∈ R + H × W D∈R^{H×W}_+ D∈R+H×W.
基础框架。基线网络 Φ ( I , D ) Φ(I,D) Φ(I,D) 输入图像 I I I和估计的深度图 D D D,,返回所需的每像素的高斯参数。具体地,对于每个像素u, 条目 [ Φ ( I , D ) ] u [Φ(I,D)]_u [Φ(I,D)]u = ( σ , ∆ , s , θ , c ) (σ,∆,s,θ,c) (σ,∆,s,θ,c)包括不透明度 σ ∈ R + σ∈R_+ σ∈R+,位移 ∆ ∈ R 3 ∆∈R^3 ∆∈R3,尺度 s ∈ R 3 s∈R^3 s∈R3,参数化旋转R(θ)的四元数 θ ∈ R 4 θ∈R^4 θ∈R4,和颜色参数c 。每个高斯的协方差由 Σ = R ( θ ) T d i a g ( s ) R ( θ ) Σ=R(θ)^Tdiag(s)R(θ) Σ=R(θ)Tdiag(s)R(θ),均值由 µ = ( u x d / f , u y d / f , d ) + ∆ µ=(u_xd/f,u_yd/f,d)+∆ µ=(uxd/f,uyd/f,d)+∆,其中f是相机的焦距(已知或来自估计Ψ)和来自深度图的 d = D ( u ) d=D(u) d=D(u)。网络Φ是一个U-Net ,利用ResNetBlock进行编码和解码。解码器网络输出一个张量 Φ d e c ( Φ e n c ( I , D ) ) ∈ R ( C − 1 ) × H × W Φ_{dec}(Φ_{enc}(I,D))∈R^{(C−1)×H×W} Φdec(Φenc(I,D))∈R(C−1)×H×W。请注意,网络输出只有C−1通道,因为深度是直接从Ψ获取的。
多高斯预测。虽然上述模型中的高斯值能够从相应的像素的射线上得到偏移,但每个高斯值都很自然地倾向于对投射到该像素上的物体部分进行建模。斯曼诺维茨等人[68]指出,对于单个对象,大量的背景像素与任何对象表面都没有关联,这些背景像素可以被模型重新利用,以捕捉3D对象中未观察到的部分。然而,场景却不是这样,场景的目标是重建每个输入像素,甚至更远。
由于没有“空闲”像素,模型很难重新利用一些高斯模型来建模遮挡周围和图像视场之外的3D场景。因此,我们建议对每个像素预测K > 1个不同的高斯分布。从概念上讲,给定一个图像I和一个估计的深度图D,我们的网络预测每个像素u的一组:形状、位置和外观参数 P = ( σ i , δ i , ∆ i , Σ i , c i ) i = 1 K P={(σ_i,δ_i,∆_i,Σ_i,c_i)}^K_{i=1} P=(σi,δi,∆i,Σi,ci)i=1K,其中第i个高斯分布的深度来自:

其中 d = D ( u ) d = D(u) d=D(u) 为深度图D中像素u处的预测深度,δ1 = 0为常数。由于深度偏移量 δ i δ_i δi不能是负的,这确保了后续的高斯层“落后于”之前的层,并鼓励网络建模封闭的表面。第i个高斯分布的均值由 µ i = ( u x d i / f , u y d i / f , d i ) + ∆ i µ_i=(u_xd_i/f,u_yd_i/f,d_i)+∆_i µi=(uxdi/f,uydi/f,di)+∆i给出。在实践中,我们发现K = 2是一个足够表达性的表示。
通过padding 越过边界进行重建。网络能够在视场之外建模3D内容是很重要的。虽然多高斯层在这方面有帮助,但通过填充物越过边界进行重建。正如我们的经验所表明的那样,对于网络能够在其视场之外建模3D内容是很重要的。虽然多高斯层在这方面有帮助,但在图像边界附近,特别需要额外的高斯层(例如,当缩放图像时,能够进行良好的新视图合成)。为了便于获得这样的高斯分布,编码器 Φ e n c Φ_{enc} Φenc首先将输入图像和深度 ( I , D ) (I,D) (I,D) 的每个边上填充P > 0个像素,以便输出 Φ k ( I , D ) ∈ R ( C − 1 ) × ( H + 2 P ) × ( W + 2 P ) Φ_k(I,D)∈R^{(C−1)×(H+2P)×(W+2P)} Φk(I,D)∈R(C−1)×(H+2P)×(W+2P) 大于输入。
4.实验
分为四个关键的发现:1.跨数据集泛化——利用单目深度预测网络和对单个数据集进行训练,可以在其他数据集上获得良好的重建质量(4.2节)。2.通过与专门为该任务设计的方法进行比较,我们确定了Flash3D可以作为单视图三维重建的有效表示(4.3节)。3.单视图Flash3D学习到的先验与通过双视图方法对比(效果相同)(4.4节)。最后是烧蚀研究。
4.1
数据集。Flash3D只在大规模的RealEstate10k[72]数据集上进行训练,其中包含了来自YouTube的房产视频。我们遵循默认的训练/测试分割,使用67,477个场景进行训练,使用7,289个场景进行测试。
指标。pixel-level PSNR, patch-level SSIM,以及 feature-level LPIPS.
对比方法。几种单视图场景重建方法,包括LDI [76]、 Single-View MPI [74]、SynSin [84]、BTS [85]和MINE [36]。也比较了最先进的双视图新视图合成方法,包括[14],pixelSplatSplat[9],MVSplat[11],和latentSplat[83]。
实施细节。Flash3D包括一个预先训练的单深度[47]模型,一个ResNet50 [24]编码器,以及多个深度偏移解码器和高斯解码器。整个模型在一个A6000 GPU上进行40,000次迭代,batchsize为16。Unidepth在训练过程中保持冻结,通过预提取整个数据集的深度图来加快训练。
4.2 跨域新视角合成
为了评估跨域泛化能力,在不可见的室外(KITTI [17])和室内(NYU [61])数据集上的性能。对于KITTI,使用一个完善的评估方案,使用1079张图像进行测试。
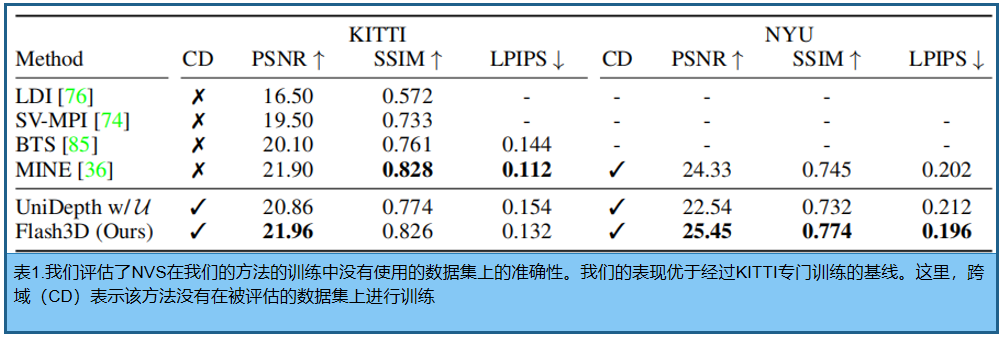
4.3 域内新视图合成
RealEstate10k评估source和target之间不同距离下的重建质量,因为较小的距离会使任务更容易。
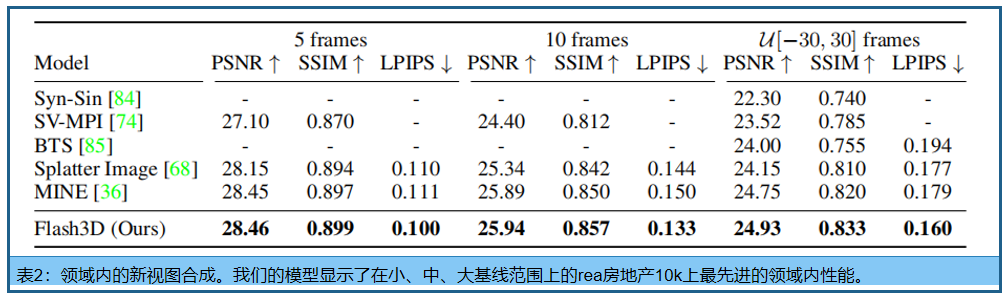

4.4 域内新视图合成
d \sqrt{d} d 1 0.24 \frac {1}{0.24} 0.241 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ
ϕ \phi ϕ
这篇关于【稀疏三维重建】Flash3D:单张图像重建场景的GaussianSplitting的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





