本文主要是介绍【数字人】11、DERAM-TALK | 使用扩散模型实现 audio+单张图的带表情驱动(字节跳动),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

论文:DREAM-Talk: Diffusion-based Realistic Emotional Audio-driven Method for Single Image Talking Face Generation
项目:https://magic-research.github.io/dream-talk/
代码:暂无
出处:字节
时间:2023.12
效果:
- 使用扩散模型实现可以控制表情的数字人生成,使用语音即可驱动单张图,看放出来的 demo 的话,生成视频基本没有抖动,牙齿补全的很好(虽然有时候同一视频不同帧的牙齿形状有变化,但已经算是很厉害了)
贡献:
- 一个创新的两阶段生成框架 DREAMTalk,它能够生成表情丰富并且嘴唇动作与音频同步的说话面部动画。
- 一个扩散模块 EmoDiff,它能够根据音频和参考的情感风格,生成多样的、动态性高的情感表达和头部姿势。
- 一个情感 ARKit 数据集,它精确地隔离了嘴部参数与其他面部属性,非常适合用于嘴唇动作精细化的任务。
一、背景
虽然现在有很多方法借助 emotional 标注数据集(如 MEAD)来进行带表情的说话头的生成,但生成的表情不是很自然,作者认为其主要的挑战如下:
-
第一:难以同时实现准确的表情和准确的嘴唇形状。
MEAD 这种数据集中的表情主要集中在眉毛、眨眼、嘴型,但整个视频很短,所以很难提取声音和嘴唇的关系来得到一个很准确的 lip-sync 模型。
所以,SPACE[10] 使用两个无表情的数据集 VoxCeleb2 [5] and RAVDESS [20] 和 MEAD 一起训练模型。但是,将带表情的数据和不带表情的数据一起训练,可能会产生合成的表情,无法达到期望。
EAMM 使用了两个模型来克服上述问题,第一个模型主要是学习与表情无关的 audio-driven face 合成,第二个模型主要是捕捉表情变化。
-
第二:模拟情感表达的微妙之处和变化是具有挑战性的。
情感表达涉及激活众多面部肌肉,并且在整个演讲过程中表现出显著的多样性。
现有方法,如 SPACE、EAMM、Styletalk,通常使用 LSTM 或 CNN 网络作为生成器,将音频转换为面部表征。虽然这些模型足以捕捉普通话语中嘴部和嘴唇的运动,但很难真实的描绘情感表达的细微差别和变化方面面临挑战。因此,生成的情感描绘往往显得平淡且不真实。
为了克服这两个困难,作者提出了 DERAM-TALK,设计了一个两阶段方法,能够同时实现表情真实且嘴唇合成准确
- 第一阶段:EmoDiff Module,捕捉动态且自然的面部表情。作者设计了一个 emotion-conditioned diffusion model 来将 input audio 转化成面部表情
- 第二阶段:Lip Refinement,主要是保证嘴唇和语音的同步性。这是一个特殊的网络系统,这个系统会根据音频信号和特定的情感风格重新优化嘴部的动作参数。与传统的面部模型不同,传统模型通常将嘴巴的动作参数和其他面部表情参数混合在一起,使用3D ARKit模型能够让我们明确地只优化嘴唇的动作。这样做可以确保其他面部表情的强度不会受到影响。我们在嘴唇精细化网络中做出的这个设计选择,保证了在提高嘴唇同步性的同时,不会牺牲情感的表达力。这提供了一种更有针对性、更有效的方法,用于创建富有情感的面部动画。
DREAMTalk 技术通过一个两阶段过程,有效地解决了以前提到的挑战,能够同时生成表情丰富并且嘴唇动作精确同步的说话面部动画。
此外,本文的扩散模型精巧地捕捉了面部的高频细节,而嘴唇精细化处理进一步提高了嘴部动作的精确度。
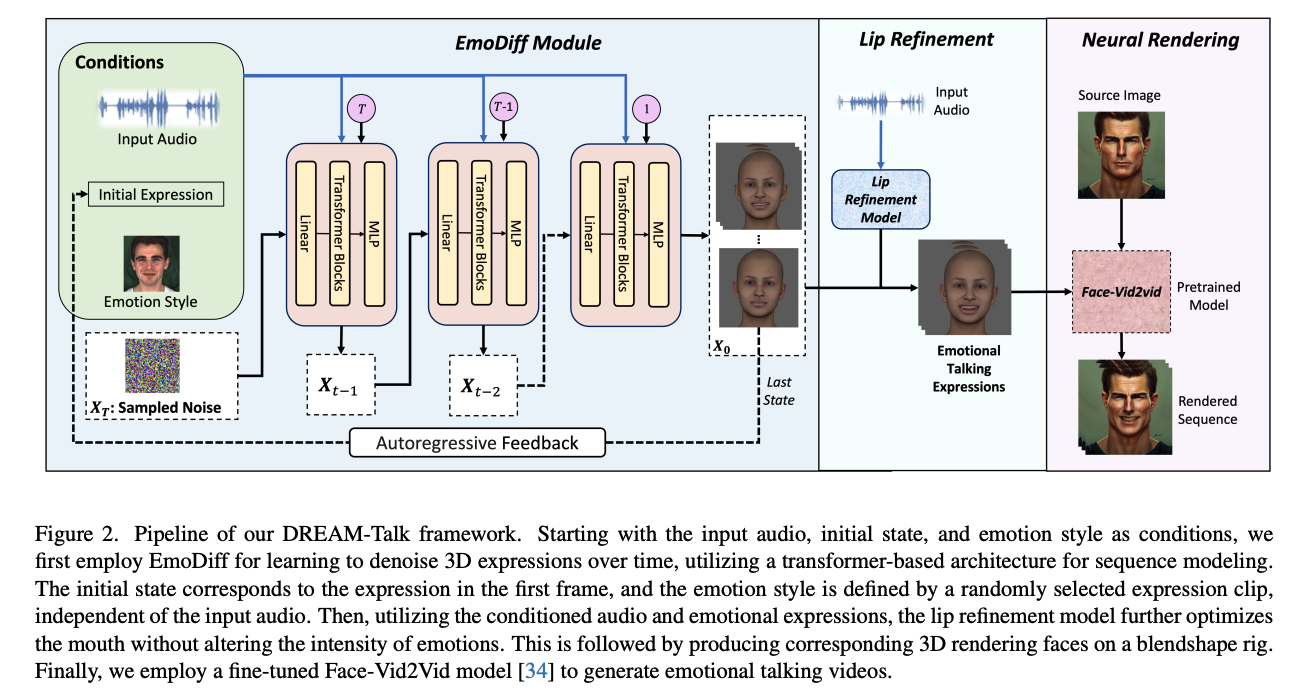
二、方法
相比于 2D landmark,3D landmark 的建模方法抗形变性和保真性更好
传统的 3D model,如 3D Morphable Models (3DMM) 或 FLAME,主要是使用 PCA 来提取主要特征,虽然这些参数提供了对一般面部外观的控制,但它们在隔离特定面部属性方面表现不足,比如眨眼或嘴唇的动作。
由于目标是在保持其他面部特征表现力的同时增强口部区域,所以作者选择使用 ARKit blendshapes。该方法将与口部相关的参数与其他面部元素分开,从而实现针对性优化。
ARKit 面部模型包含 52 个不同的参数,每个参数代表独特的面部特征。它利用基于面部动作编码系统(FACS)的混合形状,允许每个面部表情独立激活特定的面部区域(例如,口部区域、眼睛、眉毛),并且与人类面部解剖结构一致。这种方法为各种面部属性的精确控制和优化提供了可能,使其特别适合专门优化需求。
然后,作者对 MEAD 情绪数据集中的每一帧进行了全面分析,从而提取出相应的 ARKit 参数。这个过程也创建了一个 ARKit定制的面部数据集,这个数据集与MEAD数据集的情绪细微差别保持一致。
2.1 EmoDiff Module
EmoDiff Module 的目标是从 audio 中生成 3D emotional expressions,但是从 audio 到 expression 其实是一对多的问题,很难很好的映射,而且映射后的 3D 参数的一致性和多样性很难平衡
作者设计了一个以声音为条件的扩散模型,使用的是 DDPM 坐骑扩散模型

2.2 Lip Refinement
在从扩散模型获取表示为 x0 的动态情绪表达后,观察到了一个意外的后果,即扩散网络无意中减少了音频的影响,导致音频和口型之间出现了明显的不一致。
这种现象很可能归因于扩散网络生成现实序列的固有倾向,这反过来又减少了音频的影响。
为了解决这个问题,作者引入了一个唇同步细化网络,该网络使用相同的音频和情绪数据来重新校准并生成细化的口部参数。
唇同步网络结合了 LSTM 结构作为音频编码器和 CNN 结构作为情绪编码器。这种设计有效地生成了与输入音频和情绪参考风格紧密对齐的与口部相关的参数。
之后,使用这些细化的面部参数和生成的头部姿势来动画化一个 3D blend shape rig I t I_t It。随后使用 video-to-video 的方法为任意角色生成说话面部视频。消融研究表明,在实施唇部细化后,口部动作和音频之间的同步有了显著的改进。
2.3 Face Neural Rendering
使用 GPU 渲染器获取合成图像之后,作者采用的是运动转移技术来实现不同主体的真实说话头部效果,即 Face-Vid2Vid方法[34] 作为基础的神经渲染管线 R。
此外,为了提高清晰度,作者使用精心挑选的高分辨率表情丰富的说话视频数据集 TalkHead1HK [34]对模型进行了微调,能够提高表情的丰富性和渲染质量。
除了微调,作者还使用文献[1]中概述的面部超分辨率方法将最终图像分辨率提升到 512x512。
为了确保整个过程中有效地保留身份,还使用了 Siarohin等人[25]开发的 FOMM 进行神经运动转移。首先渲染一个带有神经表情的参考帧 I n I_n In,然后将相对运动 M I n → I t M_{I_n→I_t} MIn→It(即说话帧与神经帧之间的变换)应用到源图像 T 上,最终得到了渲染输出 R ( T , M I n → I t ) R(T, M_{I_n→I_t}) R(T,MIn→It)
-
Reference Frame (参考帧) I n I_n In:
这是一个带有神经表达的渲染帧,可以理解为一个基准图像,它包含了某个时刻的面部表情或者姿态。
-
Relative Motion (相对运动) M I n → I t M_{I_n→I_t} MIn→It:
这代表了从一个说话的帧(talking frame)到神经帧(neural frame)之间的变化或转换。简言之,它是一个描述如何从参考帧 I n I_n In 移动到另一个特定帧 I t I_t It 的运动信息。
-
Source Image (源图像) T:
这是要被转换表情或动作的原始图像,可以理解为目标人物的静态图像。
- Ultimate Rendered Outputs (最终渲染输出) R ( T , M I n → I t ) R(T, M_{I_n→I_t}) R(T,MIn→It):
这是最终的输出结果,它通过将相对运动应用于源图像T来生成。换句话说,它是源图像T在经过参考帧In的表情或动作变化后的最终渲染图像。
在实际应用中,这种技术可以用于视频合成、游戏角色动作生成、虚拟现实等领域。例如,可以将一个人的表情实时映射到虚拟角色上,使得虚拟角色能够模仿真人的表情和动作。这种技术的关键之处在于它能够相对于一个参考帧捕捉和转移运动,而不是简单地复制绝对运动,这样可以更自然地保持源图像的身份特征。
三、效果
3.1 数据集
作者将数据集都处理为 25FPS,训练使用:
- MEAD
- HDTF
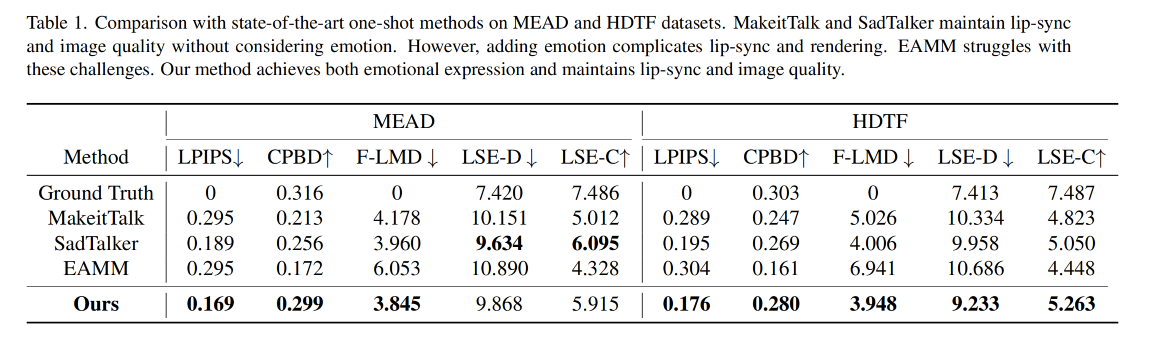
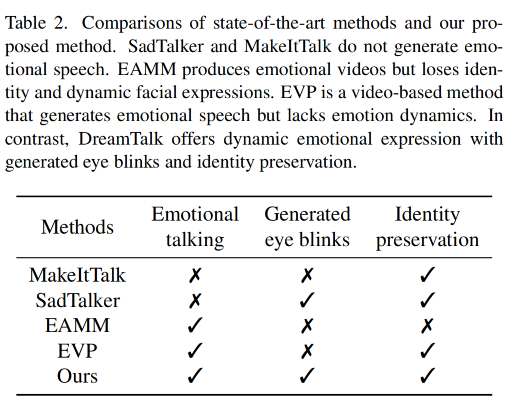
3.2 和 SOTA 的对比


这篇关于【数字人】11、DERAM-TALK | 使用扩散模型实现 audio+单张图的带表情驱动(字节跳动)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







