softmax专题

word2vec 两个模型,两个加速方法 负采样加速Skip-gram模型 层序Softmax加速CBOW模型 item2vec 双塔模型 (DSSM双塔模型)
推荐领域(DSSM双塔模型): https://www.cnblogs.com/wilson0068/p/12881258.html word2vec word2vec笔记和实现 理解 Word2Vec 之 Skip-Gram 模型 上面这两个链接能让你彻底明白word2vec,不要搞什么公式,看完也是不知所云,也没说到本质. 目前用的比较多的都是Skip-gram模型 Go

Softmax classifier
Softmax classifier原文链接 SVM是两个常见的分类器之一。另一个比较常见的是Softmax分类器,它具有不同的损失函数。如果你听说过二分类的Logistic回归分类器,那么Softmax分类器就是将其推广到多个类。不同于SVM将 f(xi,W) 的输出结果 (为校准,可能难以解释)作为每个分类的评判标准,Softmax分类器给出了一个稍直观的输出(归一化的类概率),并且

keras 将softmax值转成onehot 最大值赋值1 其他赋值0
注意: 当使用 categorical_crossentropy 损失时,你的目标值应该是分类格式 (即,如果你有 10 个类,每个样本的目标值应该是一个 10 维的向量,这个向量除了表示类别的那个索引为 1,其他均为 0)。 为了将 整数目标值 转换为 分类目标值,你可以使用 Keras 实用函数 to_categorical: from keras.utils.np_utils import


①softmax回归MNIST手写数字识别
Softmax在机器学习中有着非常广泛的应用,他计算简单而且效果显著。 假设有两个数a和b,且a>b > c 如果取max,结果是a 如果取softmax,则softmax(a) > softmax(b) > softmax(c),softmax把所有的选项都给出概率。 MNIST手写数字识别是一个使用softmax回归(softmax regression)模型

【Caffe】softmax和softmaxwithloss层的理解
softmax_axis_表示在那边切,当为1是,out_num_就表示batchsize,sum_multiplier表示通道数,scale相关的一般表示临时变量的存储,dim=C*W*H,spatial_dim=W*H,inner_num_如果fc层就为1,conv层就为H*W。 本文所举得例子是在mnist的基础上解说的,batchsize为128,类别为10。 首先看softmax求导

TensorFlow实现Softmax回归
原理 模型 相比线性回归,Softmax只多一个分类的操作,即预测结果由连续值变为离散值,为了实现这样的结果,我们可以使最后一层具有多个神经元,而输入不变,其结构如图所示: 为了实现分类,我们使用一个Softmax操作,Softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持可导的性质。 为了完成这一目标,我们首先对每个未规范化的预测求幂,这样可以确保输出非负。 为

Softmax与SoftmaxWithLoss原理及代码详解
一直对softmax的反向传播的caffe代码看不懂,最近在朱神的数学理论支撑下给我详解了它的数学公式,才豁然开朗 SoftmaxWithLoss的由来 SoftmaxWithLoss也被称为交叉熵loss。 回忆一下交叉熵的公式, H(p,q)=−∑jpjlogqj H ( p , q ) = − ∑ j p j log q j H(p, q) = -\sum_j p_j\lo

深度学习基础—Softmax回归
通常对于二分类问题,大家熟知的模型就是logistic回归。那么对于多分类问题呢?如果要多分类,我们可以在网络的最后一层建立多个神经元,每个神经元对应一个分类的输出,输出的是某一个分类的概率,这些概率之和为1。要想做到上述分析,就需要由Softmax激活函数组成的Softmax回归模型来解决。 1.Softmax激活函数 其中,xi是输入,n是输入向量的

Cross_entropy和softmax
1. 传统的损失函数存在的问题 传统二次损失函数为: J ( W , b ) = 1 2 ( h W , b ( x ) − y ) 2 + λ 2 K ∑ k ∈ K w i j 2 J(W,b)=\frac 12(h_{W,b}(x)-y)^2+\frac \lambda{2K}\sum_{k \in K}w_{ij}^2 J(W,b)=21(hW,b(x)−y)2+2Kλk∈K∑

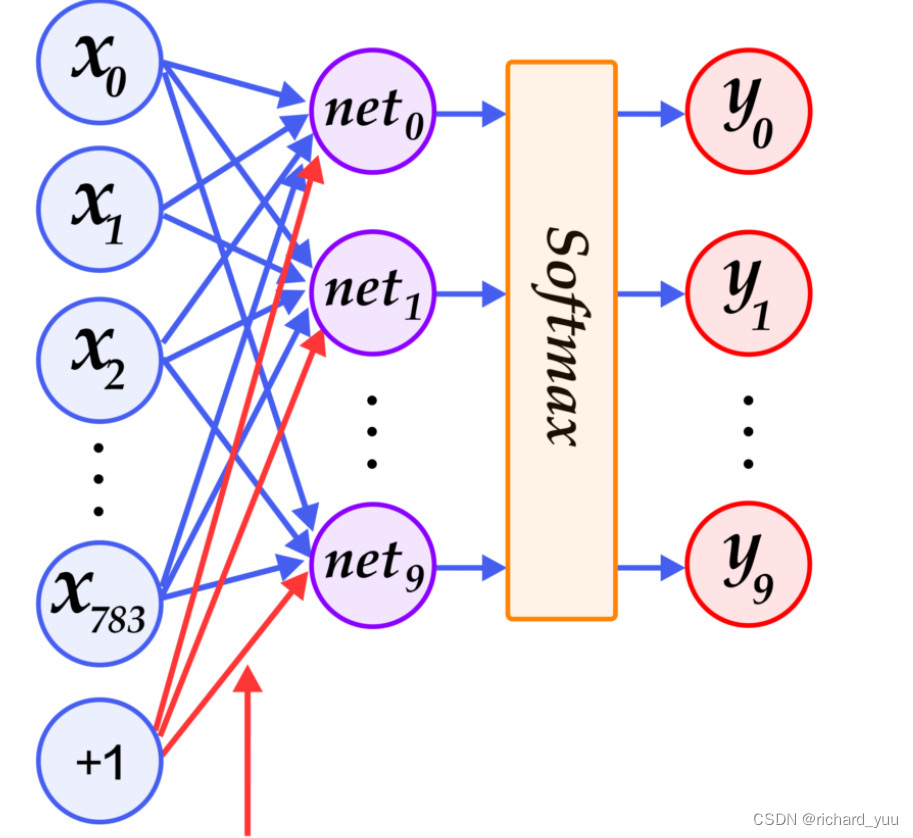
神经网络第三篇:输出层及softmax函数
在上一篇专题中,我们以三层神经网络的实现为例,介绍了如何利用Python和Numpy编程实现神经网络的计算。其中,中间(隐藏)层和输出层的激活函数分别选择了 sigmoid函数和恒等函数。此刻,我们心中不难发问:为什么要花一个专题来介绍输出层及其激活函数?它和中间层又有什么区别?softmax函数何来何去?下面我们带着这些疑问进入本专题的知识点: 1 输出层概述 2 回归问题及恒等函数 3
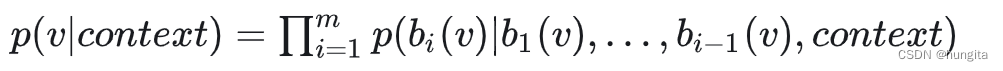
面试:关于word2vec的相关知识点Hierarchical Softmax和NegativeSampling
1、为什么需要Hierarchical Softmax和Negative Sampling 从输入层到隐含层需要一个维度为N×K的权重矩阵,从隐含层到输出层又需要一个维度为K×N的权重矩阵,学习权重可以用反向传播算法实现,每次迭代时将权重沿梯度更优的方向进行一小步更新。但是由于Softmax激活函数中存在归一化项的缘故,推导出来的迭代公式需要对词汇表中的所有单词进行遍历,使得每次迭代过程非常缓慢

【机器学习】基于Softmax松弛技术的离散数据采样
1.引言 1.1.离散数据采样的意义 离散数据采样在深度学习中起着至关重要的作用,它直接影响到模型的性能、泛化能力、训练效率、鲁棒性和解释性。 首先,采样方法能够有效地平衡数据集中不同类别的样本数量,使得模型在训练时能够更均衡地学习各个类别的特征,从而避免因数据不平衡导致的偏差。 其次,合理的采样策略可以确保模型在训练过程中能够接触到足够多的样本,避免过拟合和欠拟合问题,提高模型的泛化能力
RBF-Softmax:让模型学到更具表达能力的类别表示
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 导读 这是一篇商汤科技的ECCV2020的论文,用一种非常优雅的方法解决了传统softmax在训练分类时的两个问题,并在多个数据集上取得了很好的效果,代码已开源。 公众号后台回复“RBF”,下载已打包好的论文和代码。 RBF-Softmax: Learning Deep Representative Prototypes with R


DL基础补全计划(二)---Softmax回归及示例(Pytorch,交叉熵损失)
PS:要转载请注明出处,本人版权所有。 PS: 这个只是基于《我自己》的理解, 如果和你的原则及想法相冲突,请谅解,勿喷。 环境说明 Windows 10VSCodePython 3.8.10Pytorch 1.8.1Cuda 10.2 前言 在《DL基础补全计划(一)—线性回归及示例(Pytorch,平方损失)》(https://blog.csdn.net/u011728480/a
Caffe Prototxt 特殊层系列:Softmax Layer
Softmax Layer作用是将分类网络结果概率统计化,常常出现在全连接层后面 CNN分类网络中,一般来说全连接输出已经可以结束了,但是全连接层的输出的数字,有大有小有正有负,人看懂不说,关键是训练时,它无法与groundtruth对应(不在同一量级上),所以用Softmax Layer将其概率统计化,将输出归一化为和为1的概率值;这样我们能一眼看懂,关键是SoftmaxWithLossLay
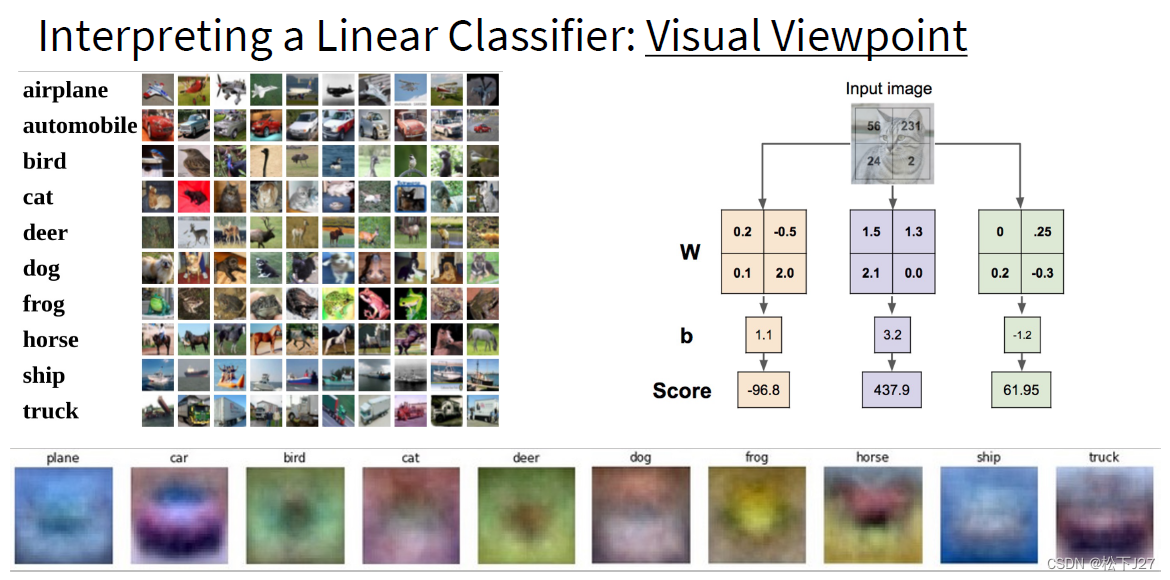
深度学习 --- stanford cs231 编程作业(assignment1,Q3: softmax classifier)
stanford cs231 编程作业(assignment1,Q3: softmax classifier softmax classifier和svm classifier的assignment绝大多部分都是重复的,这里只捡几个重点。 1,softmax_loss_naive函数,尤其是dW部分 1,1 正向传递 第i张图的在所有分类下的得分

Python Numpy联系 手动实现softmax
为了多熟悉下numpy的一些常用操作,这里手动实现一下Softmax 下面截个图说明下softmax import numpy as np#生成一个10*10 的随机二维数组,再加上1000m = np.random.randn(10,10) * 10 + 1000print(m)#axis=1 表示在二维数组中沿着横轴进行取最大值的操作m_row_max = m.max
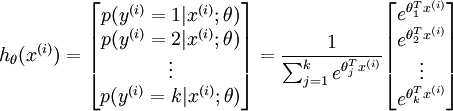
Caffe源码阅读(3)Softmax层和SoftmaxLoss层
Reference Link: http://zhangliliang.com/2015/05/27/about-caffe-code-softmax-loss-layer/ 关于softmax回归 看过最清晰的关于softmax回归的文档来源自UFLDL,简单摘录如下。 softmax用于多分类问题,比如0-9的数字识别,共有10个输出,而且这10个输出的概率和加起来应

【机器学习笔记2.6】用Softmax回归做mnist手写体识别
MNIST是什么 MNIST是一个手写数字数据集,它有60000个训练样本集和10000个测试样本集。可以将MNIST手写体识别看做是深度学习的HelloWorld。 MNIST数据集官方网址:http://yann.lecun.com/exdb/mnist/ 从官网下载的MNIST数据集是二进制形式存储的,可以通过如下代码将其转换为图片形式。 代码示例1: # mnist数据集转成图片i

【机器学习笔记2.5】用Softmax回归做二分类(Tensorflow实现)
Softmax回归和逻辑回归的区别 在本节中,我们介绍Softmax回归模型,该模型是logistic回归模型在多分类问题上的推广,在多分类问题中,类标签 y y y可以取两个以上的值[1]。当类别数 k = 2 k=2 k=2时,softmax 回归退化为 logistic 回归。 Softmax回归 vs. k个logistic回归 如果你在开发一个音乐分类的应用,需要对k种类型

内涵:算法学习之gumbel softmax
1. gumbel_softmax有什么用呢? 假设如下场景: 模型训练过程中, 网络的输出为p = [0.1, 0.7, 0.2], 三个数值分别为"向左", “向上”, "向右"的概率。 我们的决策可能是y = argmax§, 也即选择"向上"这条决策。 但是,这样做会有两个问题: argmax()函数是不可导的。这样网络就无法通过反向传播进行学习。argmax()的选择不具有随机性。同
【机器学习】Softmax回归探索
从零开始探索Softmax回归:深度学习的入门之旅 一、Softmax回归的原理与关键步骤二、研究准备:GPU环境下的PyTorch安装与配置三、研究内容:使用PyTorch实现Softmax回归 随着人工智能和机器学习的迅猛发展,深度学习技术逐渐成为了科技领域的热点。Softmax回归作为深度学习中的一种基础分类算法,广泛应用于图像识别、自然语言处理等场景。本文将从零开

PCA和Softmax学习
PCA和Softmax学习 老师上课说PCA(主成分分析)简单,不用讲,简单是简单,但也要看看,主要就是看fuldl上的教程,然后自己推导和matlab实现。 PCA pca算法 pca是一种降维方法,可以看做是逐一取方差最大方向,就是对协方差矩阵做特征值分解,取最大特征值所对应的方向。算法描述如下: 1 对所有样本进行中心化: xi x_{i} <— xi−1m∑mi=1xi x_{i
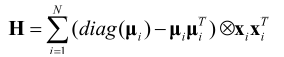
机器学习笔记5:Softmax分类器的logistic回归
在logistic回归模型中,我们只是讲了二分类问题,但是在我们的实际分类应用中,还涉及多分类问题,那么,这个时候,就需要用到softmax分类器了。如下图: 有绿三角、红叉和蓝矩形三个类别要分类,我们是通过三个分类器先分别将绿三角、红叉、蓝矩形分类出来,这样处理多分类问题的,所以对每个类别c,训练一个logistic回归分类器 f w c ( x ) f_{\textbf{w}}^{c}(\t