本文主要是介绍PCA和Softmax学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
PCA和Softmax学习
老师上课说PCA(主成分分析)简单,不用讲,简单是简单,但也要看看,主要就是看fuldl上的教程,然后自己推导和matlab实现。
PCA
pca算法
pca是一种降维方法,可以看做是逐一取方差最大方向,就是对协方差矩阵做特征值分解,取最大特征值所对应的方向。算法描述如下:
1 对所有样本进行中心化: xi <— xi−1m∑mi=1xi
2 计算样本的协方差矩阵 XXT
3 对协方差矩阵 XXT 做特征值分解
4 取最大的 d′ 个特征值所对应的特征向量 w1,w2,w3,⋅⋅⋅,wd′
5 使用特征向量乘以原始数据得到旋转数据 xrot=U′x ,如果实现降维,则使用 x˜=U(1:k)′x
代码如下:
sigma = x * x' / size(x,2); %协方差矩阵
[u, s, v] = svd(sigma); %求特征
xRot = u' * x; %数据旋转后的结果
%降维
u(:,2) = 0;
xHat = u' * x;PCA白化
白化是为了实现:
1 特征之间相关性较低
2 所有特征具有相同的方差
在使用pca降维时,需要计算协方差的特征向量,它们之间是不相关的。为了满足特征具有相同的方差,则使用 1λ√ , λ 为特征向量,即 xPCAwhite,i=xrot,iλi . 这样就 s.t.WTW=I
ZCA白化
ZCA是使旋转尽可能的接近原始数据,在使用时一般保留n个维度。
对于两种白化的实现,由于当特征值 λ 可能为接近0的数,这使得 1λ√ 为无限大,则需要给 λ 加上 ϵ .具体代码实现如下:
epsilon = 1e-5;
xPCAWhite = diag(1./sqrt(diag(s) + epsilon)) * u' * x;
xZCAWhite = u * diag(1./sqrt(diag(s) + epsilon)) * u' * x;对于教程后面的练习题,第一个照着公式撸就好了,第二个主要代码如下:
%% Step 0b: Zero-mean the data (by row)
%为每个图像计算像素强度的均值
avg = mean(x, 1); %每列为一张图片
x = x - repmat(avg, size(x,1), 1);%% Step 1a: Implement PCA to obtain xRot
sigma = x * x' / size(x,1);
[s, u, v] = svd(sigma);
xRot = u' * x;%% Step 1b: Check your implementation of PCA
covar = u;%% Step 2: Find k, the number of components to retain
k = ceil(size(u,1) * 0.99); % 99%向上取整%% Step 3: Implement PCA with dimension reduction
u(:, k + 1:end) = 0;
xHat = u' * x;%% Step 4a: Implement PCA with whitening and regularisation
epsilon = 0.1;
xPCAWhite = zeros(size(x));%% Step 4b: Check your implementation of PCA whitening
epsilon = 0.1;
covar = covar + epsilon;%% Step 5: Implement ZCA whitening
epsilon = 0.1;
xZCAWhite = u * diag(1./(diag(u) + epsilon)) * u' * x;Softmax回归
Softmax回归是解决多分类问题,和logistic类似(logistic是解决二分类问题)。
对于训练集 {(x1,y1),...(xm,ym)} ,其中x为特征,y为类标,k为类别个数, yi∈{1,2,...k} .
hypothesis 如下:
代价函数为:
梯度公式如下:
上述公式都是ufldl中给出的,现在给出梯度的推导:
由于:
在(1.2)中 c≠j 则, ∇θTcxi 等于0
由于在 yi 中,只存在一个j使得 yi=j(j∈k) ,则 ∑kc≠j1{yc=j}=1−1{yi=j}
把(1.1)(1.2)带入第一个式子可得
第一次使用lateX公式编辑,公式写的有点乱。
最后就是matlab实现,主要代码如下:
%softmaxCost.m
%计算hypothesis
exp0 = exp(theta * data); %10 * 100
h = exp0./repmat(sum(exp0), numClasses, 1);%计算代价 权重衰减项
cost = -1 / numCases * sum(sum((groundTruth.*log(h)))) + lambda / 2 * (sum(sum(theta.^2)));%计算梯度
thetagrad = -1 / numCases * ((groundTruth - h)*data') + lambda * theta;%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%softmaxPredict.m
numClasses = softmaxModel.numClasses;
%预测
exp0 = exp(theta * data);
h = exp0./repmat(sum(exp0), numClasses, 1);%预测结果, 概率最大的那个
[m, i] = max(h); %按列比较
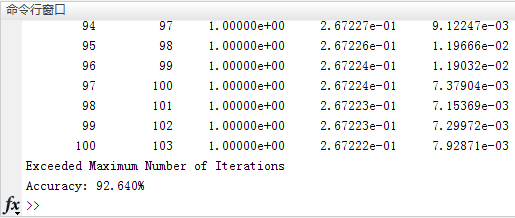
pred = i;最后得到测试准确率为:92.640%
为了清洗的查看错误的结果,对识别错误的数字可视化:
%可视化出错结果
view = find(sparse(labels(:) ~= pred(:)))';
visualization(images(:,view), 28);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%visualization.m
function visualization(data, pSize)
%可视化图
%data 输出数据
%pSize 图像尺寸fsize = 10; %显示10*10张图片
figure(1);%循环绘制子图
for i = 1: fsize * fsizesubplot(fsize, fsize, i);imshow(reshape(data(:,i), pSize, pSize));
endend结果为:

补充(2017.07.12)
这是之前囫囵吞枣的看了一遍,就几乎照着推了一遍,对其原理根本不理解,现在在论文中又看到了softmax,因此又重新看了一下。
首先,softmax是根据logistic得来的,因为logistic分布为两极化,可以使正样本趋近于1,负样本趋近于0,因此softmax函数定义为:
同时,logistic的损失函数是根据似然函数得到的:
由于乘积的方式不好计算,因此去对数,得到对数似然函数:
这篇关于PCA和Softmax学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








