sne专题
![[论文笔记] t-SNE数据可视化](https://i-blog.csdnimg.cn/direct/1471fb8b0b674486a237e13867971c94.png)
[论文笔记] t-SNE数据可视化
pip install matplotlib scikit-learn sentence-transformers 数据分类别可视化 t-SNE算法将高维数据映射到2D空间后的坐标。 t-SNE是一种用于数据降维和可视化的技术,它的作用是将原本在高维空间中的复杂数据压缩到低维空间,同时尽可能保留数据点之间的距离关系。 举例: https://arxiv.

算法金 | 一个强大的算法模型:t-SNE !!
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种用于降维和数据可视化的非线性算法。它被广泛应用于图像处理、文本挖掘和生物信息学等领域,特别擅长处理高维数据。 本文旨在详细介绍 t-SNE 算法的基本

用t-SNE可视化特征,查看特征的可分性
用t-SNE可视化特征,查看特征的可分性 t-SNE是一个很好的可视化工具,这里备份一个用t-SNE可视化特征的例子,以便今后有需要查询使用 import numpy as npimport matplotlib.pyplot as pltimport jsonfrom sklearn import manifold%matplotlib inlinedef draw_

Datacamp 笔记代码 Unsupervised Learning in Python 第二章 Visualization with hierarchical clustering t-SNE
更多原始数据文档和JupyterNotebook Github: https://github.com/JinnyR/Datacamp_DataScienceTrack_Python Datacamp track: Data Scientist with Python - Course 23 (2) Exercise Hierarchical clustering of the grain

数据特征降维 | t-分布随机邻域嵌入(t-SNE)附Python代码
t-分布随机邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)是一种非线性降维和可视化技术,广泛用于高维数据的可视化和聚类分析。 t-SNE的基本思想是通过在高维空间中测量样本之间的相似性,将其映射到低维空间中,以便更好地展示数据的结构和关系。与传统的线性降维方法(如PCA)不同,t-SNE通过考虑样本之间的概率分布来保留局部结构,并在
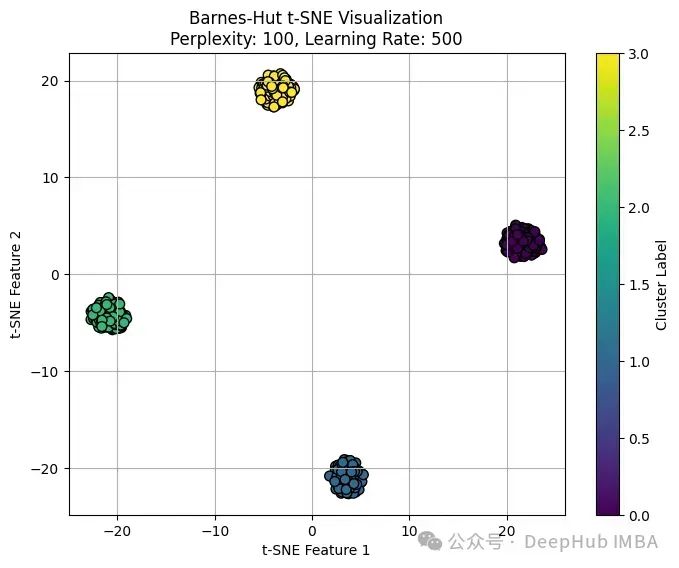
Barnes-Hut t-SNE:大规模数据的高效降维算法
在数据科学和分析中,理解高维数据集中的底层模式是至关重要的。t-SNE已成为高维数据可视化的有力工具。它通过将数据投射到一个较低维度的空间,提供了对数据结构的详细洞察。但是随着数据集的增长,标准的t-SNE算法在计算有些困难,所以发展出了Barnes-Hut t-SNE这个改进算法,它提供了一个有效的近似,允许在不增加计算时间的情况下扩展到更大的数据集。 Barnes-Hut t-SNE 是
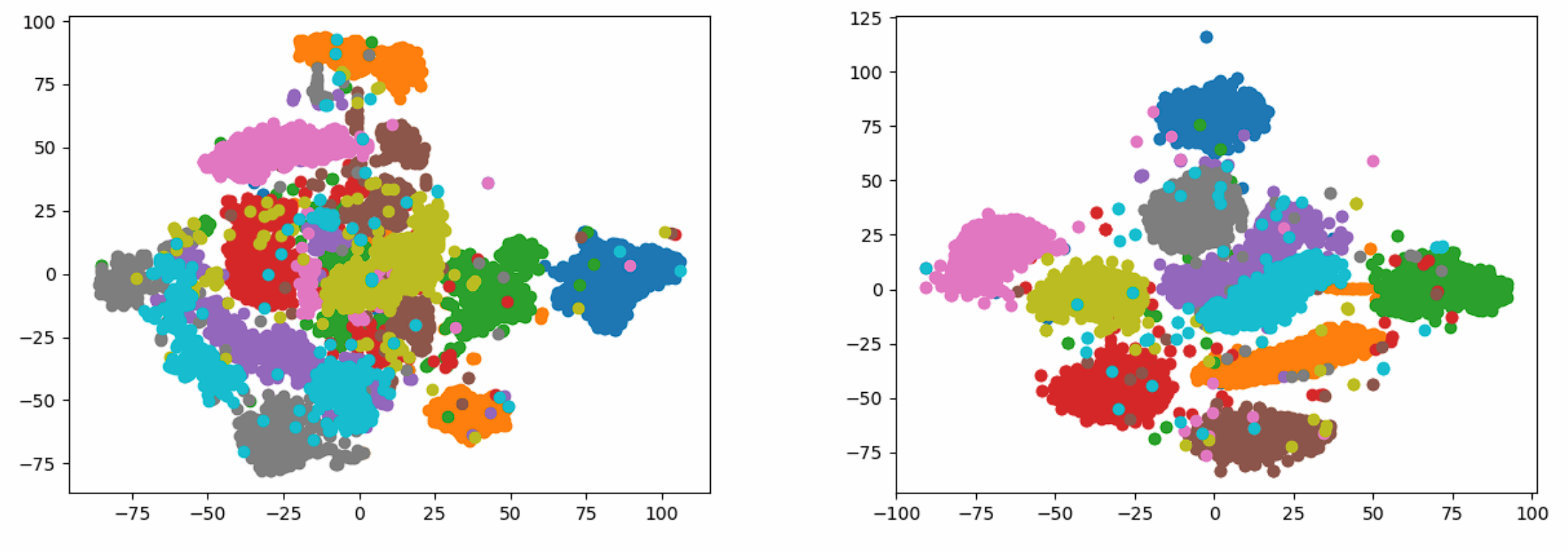
十几年前的降维可视化算法有这么好的效果?还得是Hinton。带你不使用任何现成库手敲t-SNE。
问题描述 依据Visualizing Data using t-SNE实现t-SNE算法,并对MNIST或者Olivetti数据集进行可视化训练。 有以下几点要求: 不能使用现成的t-SNE库,例如sklearn等;可以使用支持矩阵、向量操作的库实现,例如numpy;将数据降低至二维,同一类型的数据使用同一种颜色绘制散点图。 符号介绍 x i x_i xi:第 i i i个原始数据;
降维算法 t-SNE和UMAP的python实现
from sklearn import manifold# t-SNE 倾向于保存局部特征,训练较慢for i in range(listLength):my_value[i] = np.array(my_value[i]).reshape(-1, 64)tsne = manifold.TSNE(n_components=2, init='pca', random_state=501)X_tsne
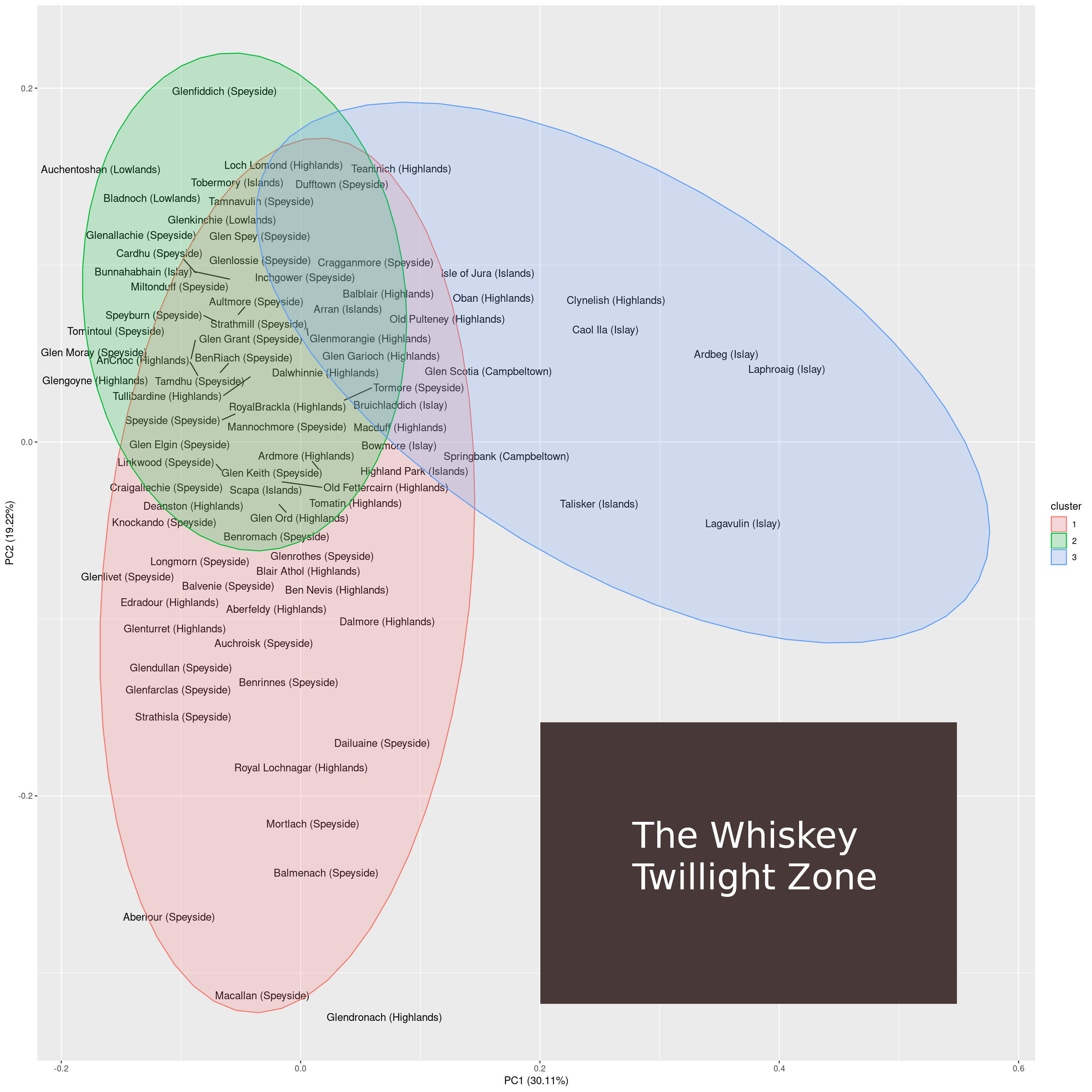
R语言高维数据的pca、 t-SNE算法降维与可视化分析案例报告
维度降低有两个主要用例:数据探索和机器学习。它对于数据探索很有用,因为维数减少到几个维度(例如2或3维)允许可视化样本。然后可以使用这种可视化来从数据获得见解(例如,检测聚类并识别异常值)。对于机器学习,降维是有用的,因为在拟合过程中使用较少的特征时,模型通常会更好地概括。 在这篇文章中,我们将研究三维降维技术: 主成分分析(PCA):最流行的降维方法内核PCA:PCA的一种变体,允许非线性t

t-SNE数据降维(2维3维)及可视化
(最近看了一个叫光谱特征在后门攻击中的用法,读完之后发现是用了一个SVD也就是奇异值分解做了降维,然后用残差网络的representation层残差与残差的奇异值分解后的右奇异值矩阵的第一行做乘法得到correlation,疑惑得很什么时候相关性可以这么算了。于是想到降维可以不用SVD可以用TSNE,就写一下这一块的东西,融合了别人写的二维和三维的可视化) t-SNE全称为t-distribu

导航应用软件开发平台--SNE介绍
近年来,在汽车业和智能交通双重驱动下,车载导航应用产业迅速发展。目前先进的车载导航系统结合了 GPS 全球定位技术,地理信息系统(GIS)技术和现的代计算机技术,实现车辆的实时定位、智能导航,使车辆在陌生的地理环境中顺利通行,极大提高了车辆的运行效率和安全,减轻了驾驶员的工作强度,使驾驶员能够准确及时地控制车辆到达预定的目的地。 车载导航是地理信息技术在大众信息化的方面的主要应用方向,北京超

基于PCA和t-SNE可视化词嵌入
作者|Marcellus Ruben 编译|VK 来源|Towards Datas Science 当你听到“茶”和“咖啡”这个词时,你会怎么看这两个词?也许你会说它们都是饮料,含有一定量的咖啡因。关键是,我们可以很容易地认识到这两个词是相互关联的。然而,当我们把“tea”和“coffee”两个词提供给计算机时,它无法像我们一样识别这两个词之间的关联。 单词不是计算机自然就能理解的东西。为

【深度学习:t-SNE 】T 分布随机邻域嵌入
【深度学习:t-SNE 】T 分布随机邻域嵌入 降低数据维度的目标什么是PCA和t-SNE,两者有什么区别或相似之处?主成分分析(PCA)t-分布式随机邻域嵌入(t-SNE) 在 MNIST 数据集上实现 PCA 和 t-SNE结论 了解 t-SNE 的基本原理、与 PCA 的区别以及如何在 MNIST 数据集上应用 t-SNE 在本文中,您将了解到 t-SNE 与 PCA(
无监督学习 - t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)
什么是机器学习 t-分布邻域嵌入(t-Distributed Stochastic Neighbor Embedding,t-SNE)是一种非线性降维技术,用于将高维数据映射到低维空间,以便更好地可视化数据的结构。t-SNE主要用于聚类分析和可视化高维数据的相似性结构,特别是在探索复杂数据集时非常有用。 t-SNE的基本原理 相似度测量: 对于高维数据中的每一对数据点,计算它们之间的相似度。

error: unknown file type '.pyx' (from 'tsne/bh_sne.pyx')
pip install tsne 在安装 tsne时报错 error: unknown file type '.pyx' (from 'tsne/bh_sne.pyx') ------------------------------------------------------------ 解决办法: 安装:pip install pyrex 如果安装失败 ,

T-SNE笔记 无痛理解
首先看下面两个图, 作左图是t-SNE降维后得到的,有图是PCA 降维后得到的。很明显t-SNE将分的更加清晰,而PCA则重叠严重。 t-sne 是一种非线性的降维方法,一般可视化用的比较多,利用t-sne 可以把高维数据降维到2维或者3维空间上,然后各个数据点跟自己在高维空间上相近的数据点聚集在一起 好比空中漂浮的不同颜色的小球 让它们落地后 再根据原本在空中的聚集情况聚集在一起。 t-sne的
Umap与 t-sne可视化CNN特征
考虑到umap 比 t-sne快,而且全局结构更好。 demo网站 Understanding UMAP doc: https://github.com/lmcinnes/umap How to Use UMAP — umap 0.5 documentation plt.scatter()_coder-CSDN博客_plt.scatter tqdm 遍历 DataLoader 报错
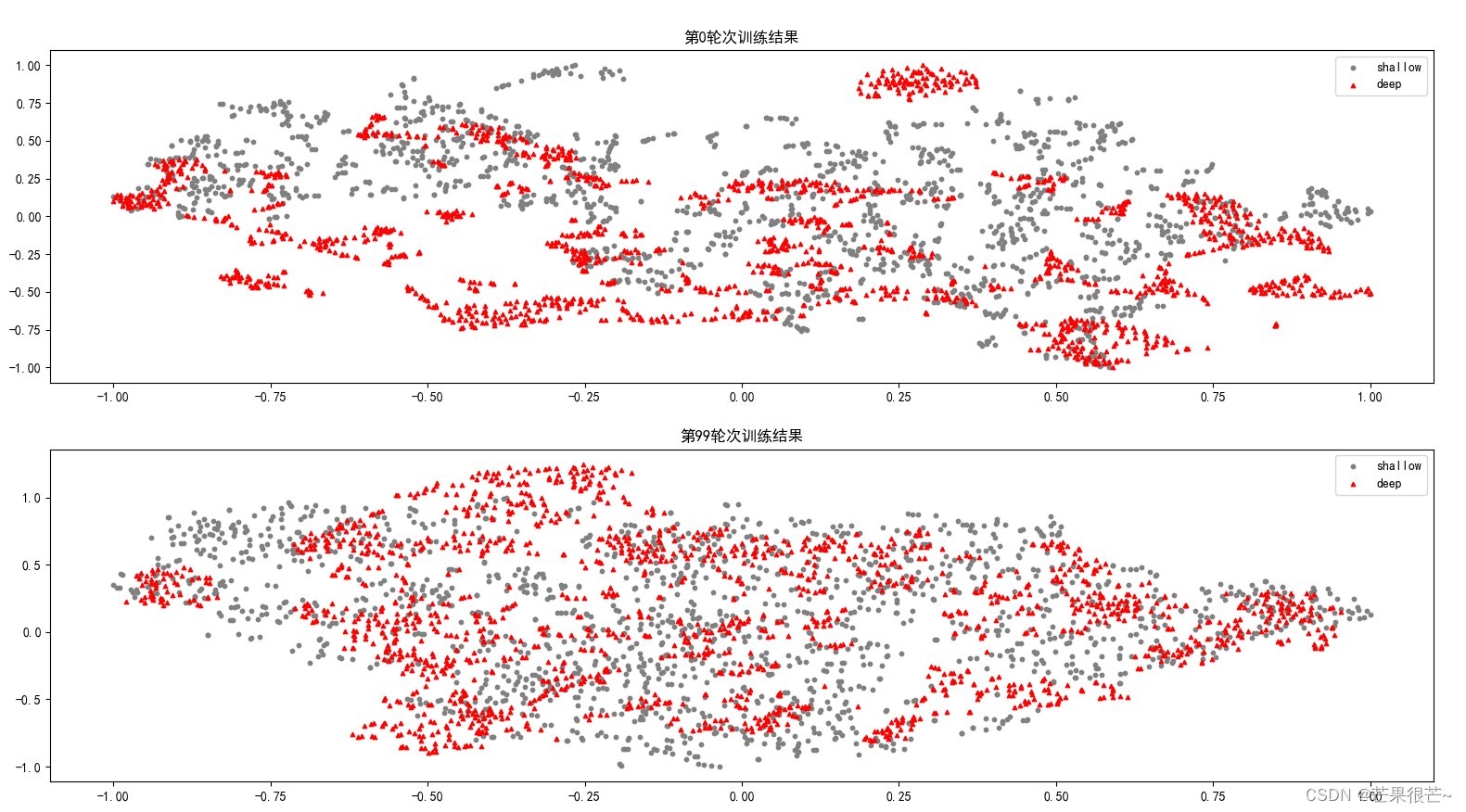
t-SNE高维数据可视化实例
t-SNE:高维数据分布可视化 实例1:自动生成一个S形状的三维曲线 实例1结果: 实例1完整代码: import matplotlib.pyplot as pltfrom sklearn import manifold, datasets"""对S型曲线数据的降维和可视化"""x, color = datasets.make_s_curve(n_samples=1000, ran

t-SNE高维数据可视化实例
t-SNE:高维数据分布可视化 实例1:自动生成一个S形状的三维曲线 实例1结果: 实例1完整代码: import matplotlib.pyplot as pltfrom sklearn import manifold, datasets"""对S型曲线数据的降维和可视化"""x, color = datasets.make_s_curve(n_samples=1000, ran

python——画t-sne图(含代码)
t-sne是一种数据可视化的工具,可以把高维数据降到2-3维,然后画成t-sne图可视化出来。 如下图所示: 这种方法在很多情况下可以很清晰地表示出数据的分布,因此被广泛使用。 在python中也可以直接用代码画出t-sne,话不多说直接上代码: from sklearn import datasetsfrom openTSNE import TSNEimport tsneu
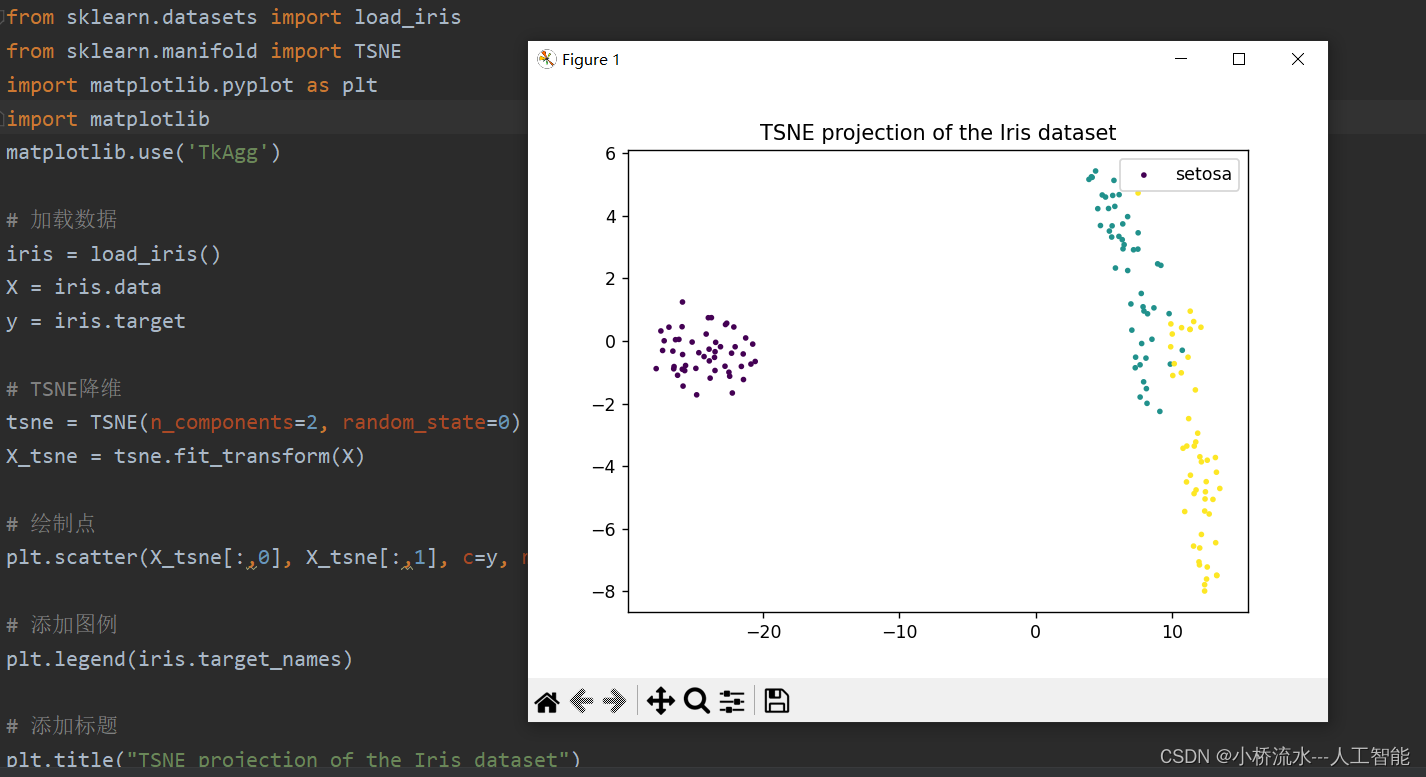
详细解答T-SNE程序中from sklearn.manifold import TSNE的数据设置,包括输入数据,绘制颜色的参数设置,代码复制可用!!
文章目录 前言——TSNE是t-Distributed Stochastic Neighbor Embedding的缩写1、可运行的T-SNE程序2. 实验结果3、针对上述程序我们详细分析T-SNE的使用方法3.1 加载数据3.2 TSNE降维3.3 绘制点3.4 关于颜色设置,颜色使用的标签数据的说明c=y 总结 前言——TSNE是t-Distributed Stocha
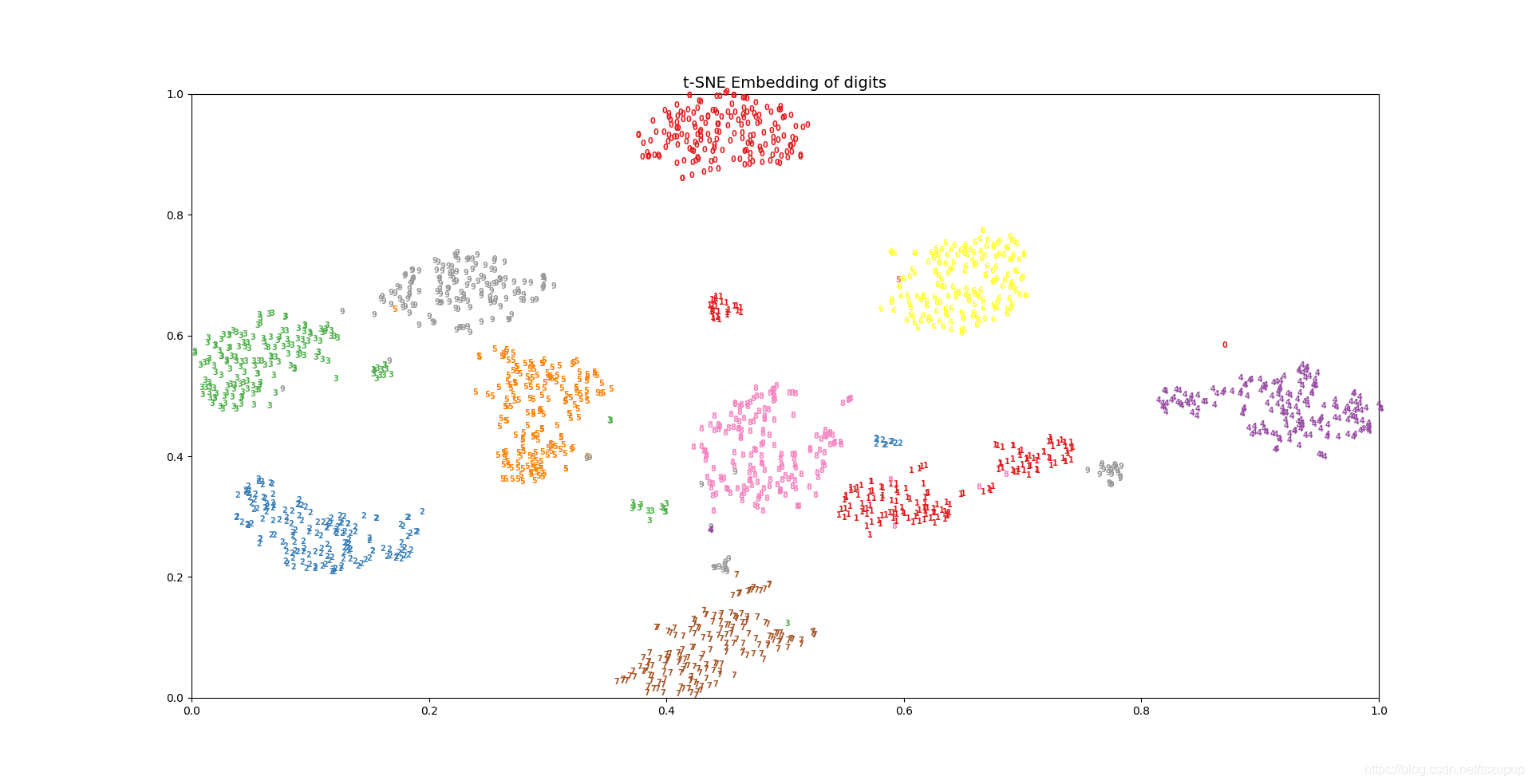
t-SNE算法的基本思想及其Python实现
t-SNE全称为t-distributed Stochastic Neighbor Embedding,翻译为t-随机邻近嵌入,它是一种嵌入模型,能够将高维空间中的数据映射到低维空间中,并保留数据集的局部特性,该算法在论文中非常常见,主要用于高维数据的降维和可视化。提出论文为:Visualizing Data using t-SNE。 t-SNE可以算是目前效果最好的数据降维和可视

【机器学习】降维算法 PCA、LDA、LLE、Laplacian EigenmapsI、SOMAP 、 MDS、SNE、TSNE
机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中。降维的本质是学习一个映射函数 f : x->y,其中x是原始数据点的表达,目前最多使用向量表达形式。 y是数据点映射后的低维向量表达,通常y的维度小于x的维度(当然提高维度也是可以的)。f可能是显式的或隐式的、线性的或非线性的。 目前大部分降维算法处理向量表达的数据,也有一些降维算法处理高阶张量表达的数据

利用python对简书文章进行文本挖掘【词云/word2vec/LDA/t-SNE】
这是一个快速上手词云/word2vec/LDA/t-SNE的一个小例子,实践之后,可以让大家对这些方法有初步的了解。 以下代码在jupyter notebook中测试通过,代码请戳这里。 简单介绍下数据 简书有个简书交友的专题,某知名博主爬取了该专题2700余篇文章,我就偷个懒直接拿来用了~ 数据呢,大概就是长这个样子了: 主要涵盖:作者,主页URL,文章标题,发布时间,阅读量,评