本文主要是介绍Barnes-Hut t-SNE:大规模数据的高效降维算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在数据科学和分析中,理解高维数据集中的底层模式是至关重要的。t-SNE已成为高维数据可视化的有力工具。它通过将数据投射到一个较低维度的空间,提供了对数据结构的详细洞察。但是随着数据集的增长,标准的t-SNE算法在计算有些困难,所以发展出了Barnes-Hut t-SNE这个改进算法,它提供了一个有效的近似,允许在不增加计算时间的情况下扩展到更大的数据集。

Barnes-Hut t-SNE 是一种高效的降维算法,适用于处理大规模数据集,是 t-SNE (t-Distributed Stochastic Neighbor Embedding) 的一个变体。这种算法主要被用来可视化高维数据,并帮助揭示数据中的内部结构。
基础概念
t-SNE 的基础是 SNE(Stochastic Neighbor Embedding),一种概率性降维技术,通过保持高维和低维空间中的概率分布相似来进行数据映射。而t-SNE 是由 Laurens van der Maaten 和 Geoffrey Hinton 于 2008 年提出的。它是一种非线性降维技术,非常适合于将高维数据降维到二维或三维空间中,用于数据可视化。
Barnes-Hut t-SNE 采用了在天体物理学中常用的 Barnes-Hut 算法来优化计算过程。这种算法最初是为了解决 N体问题,即计算多个物体之间相互作用的问题而设计的。
传统的 t-SNE 算法的时间复杂度约为 O(N2),而 Barnes-Hut 版本的 t-SNE 则将时间复杂度降低到 O(NlogN),这使得算法能够更加高效地处理大规模数据集。
工作原理
Barnes-Hut t-SNE改进了原来的t-SNE算法,加入了空间划分的数据结构,以降低点之间相互作用的复杂性。首先我们先简单介绍 t-SNE,因为理解 t-SNE 的基本工作原理对于理解 Barnes-Hut t-SNE 是必要的
t-SNE 的主要步骤包括:
- 相似度计算:在高维空间中,t-SNE 首先计算每对数据点之间的条件概率,这种概率反映了一个点选择另一个点作为其邻居的可能性。这种计算基于高斯分布,并且对于每个点会有不同的标准差(高斯分布的宽度),以保证每个点的有效邻居数大致相同。
- 低维映射:在低维空间(通常是 2D 或 3D)中,t-SNE 同样为数据点之间定义了一个概率分布,但这里使用的是 t 分布(自由度为1的学生 t-分布),这有助于在降维过程中避免“拥挤问题”(即多个高维点映射到相同的低维点)。
- 梯度下降:t-SNE 通过最小化高维和低维空间中概率分布的 Kullback-Leibler 散度来找到最佳的低维表示。这个过程通过梯度下降算法进行优化。
在处理大型数据集时,直接计算所有点对之间的相互作用非常耗时。Barnes-Hut 算法通过以下步骤优化这个过程:
- 构建空间索引树:在二维空间中构建四叉树,在三维空间中构建八叉树。每个节点表示一个数据点,而每个内部节点则表示它的子节点的质心(即子节点的平均位置)。
- 近似相互作用:在计算点之间的作用力(即梯度下降中的梯度)时,Barnes-Hut 算法不是计算每一对点之间的相互作用,而是使用树来估计远距离的影响。对于每个点,如果一个节点(或其包含的数据点的区域)距离足够远(根据预设的阈值,如节点的宽度与距离的比率),则该节点内的所有点可以被视为一个单一的质心,从而简化计算。
- 有效的梯度计算:通过这种近似,算法只需要计算与目标点近邻的实际点以及远处质心的影响,极大地减少了必须执行的计算量。
通过这种方法,Barnes-Hut t-SNE 将复杂度从 O(N2) 降低到 O(NlogN),使其能够有效地处理数万到数十万级别的数据点。但是这种效率的提升是以牺牲一定的精确度为代价的,因为远距离的相互作用是通过质心近似来实现的,而不是精确计算。
代码示例
Barnes-Hut t-SNE已经被集成到scikit-learn库种,所以我们直接可以拿来使用
首先我们生成一些简单的数据:
importnumpyasnpimportmatplotlib.pyplotaspltfromsklearn.manifoldimportTSNEfromsklearn.datasetsimportmake_blobsfromsklearn.model_selectionimporttrain_test_splitfromsklearn.preprocessingimportStandardScalerfromsklearn.metricsimportsilhouette_score# Generate synthetic dataX, y=make_blobs(n_samples=1000, centers=4, n_features=50, random_state=42)

生成4个簇,每个样本包含50个特征,总计1000个样本。
然后我们分割数据集,进行聚类
# Split data into training and testing setsX_train, X_test, y_train, y_test=train_test_split(X, y, test_size=0.3, random_state=42)# Standardize features by removing the mean and scaling to unit variancescaler=StandardScaler()X_train_scaled=scaler.fit_transform(X_train)X_test_scaled=scaler.transform(X_test)# Hyperparameter tuning for t-SNEbest_silhouette=-1best_params= {}perplexities= [5, 30, 50, 100] # Different perplexity values to trylearning_rates= [10, 100, 200, 500] # Different learning rates to tryforperplexityinperplexities:forlearning_rateinlearning_rates:# Apply Barnes-Hut t-SNEtsne=TSNE(n_components=2, method='barnes_hut', perplexity=perplexity,learning_rate=learning_rate, random_state=42)X_train_tsne=tsne.fit_transform(X_train_scaled)# Calculate Silhouette scorescore=silhouette_score(X_train_tsne, y_train)# Check if we have a new best scoreifscore>best_silhouette:best_silhouette=scorebest_params= {'perplexity': perplexity, 'learning_rate': learning_rate}best_embedding=X_train_tsne# Visualization of the best t-SNE embeddingplt.figure(figsize=(8, 6))plt.scatter(best_embedding[:, 0], best_embedding[:, 1], c=y_train, cmap='viridis', edgecolor='k', s=50)plt.title(f'Barnes-Hut t-SNE Visualization\nPerplexity: {best_params["perplexity"]}, Learning Rate: {best_params["learning_rate"]}')plt.colorbar(label='Cluster Label')plt.xlabel('t-SNE Feature 1')plt.ylabel('t-SNE Feature 2')plt.grid(True)plt.show()# Interpretations and resultsprint(f"Best Silhouette Score: {best_silhouette}")print("Best Parameters:", best_params)print("Barnes-Hut t-SNE provided a clear visualization of the clusters, indicating good separation among different groups.")
我们只要在sklearn的TSNE方法种传入参数method='barnes_hut’即可。上面代码运行结果如下:
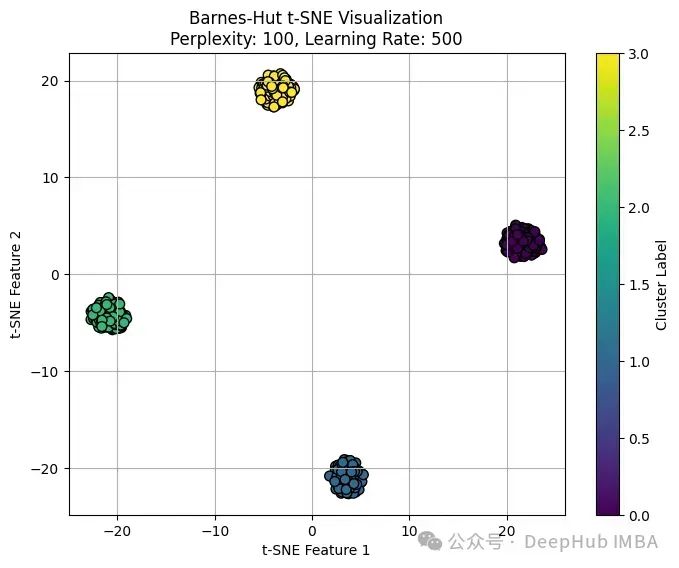
Best Silhouette Score: 0.9504804611206055Best Parameters: {'perplexity': 100, 'learning_rate': 500}Barnes-Hut t-SNE provided a clear visualization of the clusters, indicating good separation among different groups.
可以看到:
Barnes-Hut t-SNE算法已经有效地将高维数据分离成不同的簇。轮廓分数0.95说明聚类分离良好,几乎没有重叠,这个接近1的分数表明,平均而言,数据点离它们的集群中心比离最近的不同集群的中心要近得多。
通过观察可以看到到簇内的密度各不相同。例如图中底部的某个簇(蓝色的)看起来特别紧凑,表明其点之间的相似度很高。相反顶部的另一个簇(黄色的)看起来更为分散,意味着该组内的变异更大。
没有明显的异常值远离其各自的簇,这表明原始高维空间中的簇结构定义良好。
高轮廓分数和清晰的视觉分离,可以说明我们选择的超参数(perplexity:100,学习率:500)非常适合这个数据集。这也表明算法可能已经很好地收敛,找到了一个稳定的结构,强调了簇之间的差异。
总结
Barnes-Hut t-SNE 是一种高效的数据降维方法,特别适合于处理大型和复杂的数据集,它通过引入四叉树或八叉树的结构来近似远距离作用,从而大幅减少了计算量,同时保持了良好的数据可视化质量。Barnes-Hut t-SNE优化了原始 t-SNE 算法的计算效率,使其能够在实际应用中更为广泛地使用。
https://avoid.overfit.cn/post/ec11566be83d4f4fb7cf31d09197d8e4
这篇关于Barnes-Hut t-SNE:大规模数据的高效降维算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








