sft专题

神经网络微调技术全解(01)-不同的微调方法如PEFT、SFT、LoRa、QLoRa等,旨在解决不同的问题和挑战
微调技术在深度学习和大模型的应用中起到了关键作用。不同的微调方法如PEFT、SFT、LoRa、QLoRa等,旨在解决不同的问题和挑战。以下是它们的简介及各自解决的问题。 1. PEFT (Parameter-Efficient Fine-Tuning) 问题:在处理大规模预训练模型时,全面微调所有参数会消耗大量计算资源和存储空间。对于一些特定任务,全面微调可能不必要,并且可能导致过拟合。

sft是mean-seeking rl是mode-seeking
原文链接 KL散度是D(P||Q),P和Q谁在前谁在后是有讲究的,P在前,就从P采样。 D K L ( P ∣ ∣ Q ) = E x − p ( x ) ( l o g ( P ( x ) / Q ( x ) ) ) D_{KL}(P||Q)=E_{x-p(x)}(log(P(x)/Q(x))) DKL(P∣∣Q)=Ex−p(x)(log(P(x)/Q(x)))想象一下,如果某个x的Q=


清华大学提出IFT对齐算法,打破SFT与RLHF局限性
监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是预训练后提升语言模型能力的两大基础流程,其目标是使模型更贴近人类的偏好和需求。 考虑到监督微调的有效性有限,以及RLHF构建数据和计算成本高昂,这两种方法常常被结合使用。但由于损失函数、数据格式的差异以及对

Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(十) 使用 LoRA 微调常见问题答疑
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3
RAG与SFT技术简介
RAG与SFT技术简介 1. 检索增强生成(RAG)1.1 RAG技术的基本概念1.2 RAG的工作流程1.2.1检索阶段1.2.2 生成阶段 1.3 RAG的优势1.4 应用场景 2. 指令微调(SFT)2.1 SFT技术的基本概念2.2 SFT的工作流程2.2.1 预训练模型2.2.2 微调阶段 2.3 SFT的优势2.4 应用场景 1. 检索增强生成(RAG) 1.1
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3

LLaMA3(Meta)微调SFT实战Meta-Llama-3-8B-Instruct
LlaMA3-SFT LlaMA3-SFT, Meta-Llama-3-8B/Meta-Llama-3-8B-Instruct微调(transformers)/LORA(peft)/推理 项目地址 https://github.com/yongzhuo/LLaMA3-SFT默认数据类型为bfloat6 备注 1. 非常重要: weights要用bfloat16/fp32/tf32(第二版
使用SFT和VLLM微调和部署Llama3-8b模型
目录 1. 环境安装2. accelerator准备3. 加载llama3和数据4. 训练参数配置5. 微调6. vllm部署7. Llama-3-8b-instruct的使用参考 1. 环境安装 pip install -q -U bitsandbytespip install -q -U git+https://github.com/huggingface/transfor
llama-factory SFT 系列教程 (四),lora sft 微调后,使用vllm加速推理
文章目录 文章列表:背景简介llama-factory vllm API 部署融合 lora 模型权重 vllm API 部署HuggingFace API 部署推理API 部署总结 vllm 不使用 API 部署,直接推理数据集 tenplatevllm 代码部署 文章列表: llama-factory SFT系列教程 (一),大模型 API 部署与使用llama-fact

llama-factory SFT系列教程 (三),chatglm3-6B 大模型命名实体识别实战
文章列表: llama-factory SFT系列教程 (一),大模型 API 部署与使用llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署 llama-factory SFT系列教程 (三),chatglm3-6B 命名实体识别实战 简介 利用 llama-factory 框架,基于 chatglm3-6B 模型 做命名实体识别任务; 本次实
Trl SFT: llama2-7b-hf使用QLora 4bit量化后ds zero3加上flash atten v2单机多卡训练(笔记)
目录 一、环境 1.1、环境安装 1.2、安装flash atten 二、代码 2.1、bash脚本 2.2、utils.py 注释与优化 2.3、train.py 注释与优化 2.4、模型/参数相关 2.4.1、量化后的模型 2.4.1.1 量化后模型结构 2.4.1.2 量化后模型layers 2.4.2

llama-factory SFT系列教程 (三),chatglm3-6B 命名实体识别实战
背景 llama-factory SFT系列教程 (一),大模型 API 部署与使用llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署本文为llama-factory SFT系列教程 第三篇 简介 利用 llama-factory 框架,基于 chatglm3-6B 模型 做命名实体识别任务; 装包 git clone https://gith
llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署
文章目录 简介支持的模型列表2. 添加自定义数据集3. lora 微调4. 大模型 + lora 权重,部署问题 参考资料 简介 llama-factory SFT系列教程 (一),大模型 API 部署与使用本文为 llama-factory SFT系列教程的第二篇; 支持的模型列表 模型名模型大小默认模块TemplateBaichuan27B/13BW_packbaich

llama-factory SFT系列教程 (一),大模型 API 部署与使用
文章目录 背景简介难点 前置条件1. 大模型 api 部署下一步阅读 背景 本来今天没有计划学 llama-factory,逐步跟着github的文档走,发现这框架确实挺方便,逐渐掌握了一些。 最近想使用 SFT 微调大模型,llama-factory 是使用非常广泛的大模型微调框架; 简介 基于 llama_factory 微调 qwen/Qwen-7B,qwen/Qwe
![[LLM] 大模型基础|预训练|有监督微调SFT | 推理](https://img-blog.csdnimg.cn/direct/14c03de8f5214d4ab22b7ca3a18b43aa.png)
[LLM] 大模型基础|预训练|有监督微调SFT | 推理
现在的大模型在进行预训练时大部分都采用了GPT的预训练任务,即 Next token prediction。 标题:Language Model Training and Inference: From Concept to Code 作者:CAMERON R. WOLFE 原文链接:https://cameronrwolfe.substack.com/p/language-mode
大模型RAG SFT
为什么需要RAG、SFT或者重训?为了拓展模型能力的边界 需要额外给大模型提供私域知识,不能每次都人工加入到prompt中,需要自动加,这就引出了RAG,RAG是让AI回答问题时看一本参考书。 输出不满足格式要求,例如想要一个用例包含固定的字段,但是生成结果不稳定,风格不固定,就要SFT,SFT是让AI的输出形式符合预期。 当需要模型深入理解某个概念或者进行联想和专业推理,例如方法或者方法
just recode for myself 统计大模型SFT的结果与version2中text的结果bad case
问题描述: 利用Qwen大模型进行SFT (lora)。将生成的结果与version2版本下的中文test.txt进行bad case分析 代码实现: from tqdm import tqdm, trangeimport osimport refrom typing import Listimport jsonfrom pdb import set_trace as stoppi

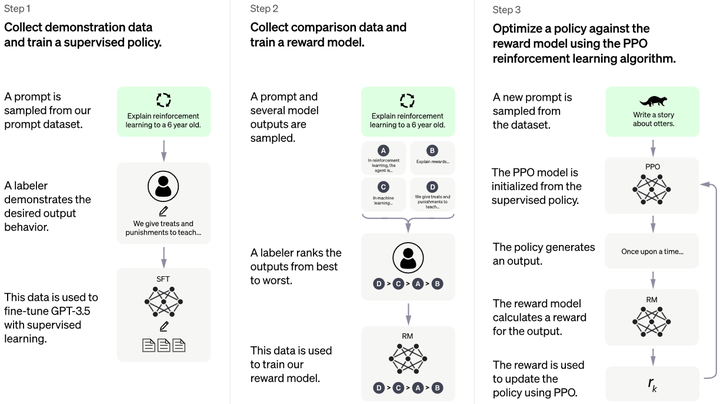
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF
GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHF 文章目录 GPT实战系列-GPT训练的Pretraining,SFT,Reward Modeling,RLHFPretraining 预训练阶段Supervised FineTuning (SFT)监督微调阶段Reward Modeling 奖励评价建模Reinforment Learni
各种LLM数据集包括SFT数据集
各种LLM数据集包括SFT数据集 数集介绍和 hf上的名字对话数据生成方法交通领域数据集SFT 的解释 数集介绍和 hf上的名字 通用预训练数据集 SFT datasets SFT 数据集 50万条中文ChatGPT指令Belle数据集:BelleGroup/train_0.5M_CN 100万条中文ChatGPT指令Belle数据集:BelleGroup/train_1M_C


baichuan2 chat模型sft指令微调数据格式分析
一、前言 百川官网:https://www.baichuan-ai.com/ 模型权重:https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat 记录一下 baichuan 2 的 tokenizer 及 chat 数据构建格式。 二、数据处理代码 根据官方 github 的 finetune 代码,将其 preprocessing 方法抽
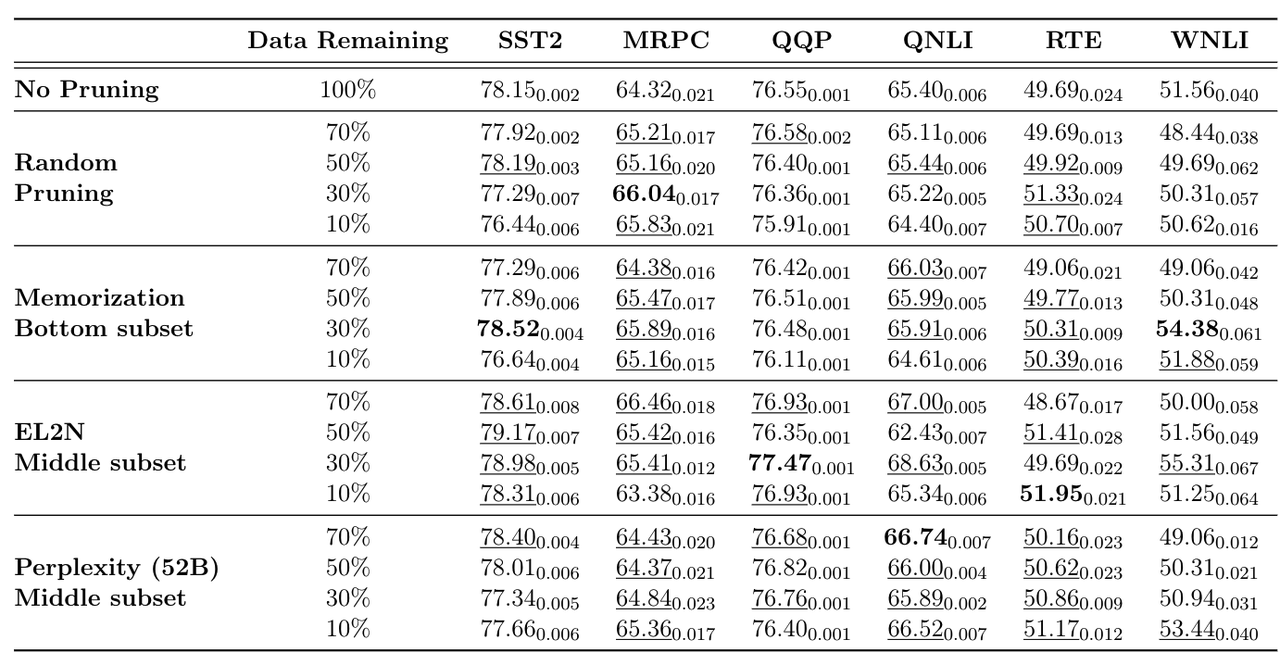
【LLM】sft和pretrain数据处理和筛选方法
note 痛点:训练垂直领域模型,sft数据和增量pretrain数据质量把控很重要 当数据不够时,通过self-instruct等方法造多样化的数据当数据很多时,需要清洗/筛选出高质量数据 文章目录 note一、sft数据的筛选策略1.1 使用self-instruct构造sft数据1.2 筛选高质量sft数据1.3 评估sft数据质量和数量 二、pretrain数据的筛选策略2.1
![[NLP] LLM---<训练中文LLama2(四)方式一>对LLama2进行SFT微调](https://img-blog.csdnimg.cn/bec50e7544ad455fba2cd4cfac385af9.png)
[NLP] LLM---<训练中文LLama2(四)方式一>对LLama2进行SFT微调
指令精调 指令精调阶段的任务形式基本与Stanford Alpaca相同。训练方案也采用了LoRA进行高效精调,并进一步增加了可训练参数数量。在prompt设计上,精调以及预测时采用的都是原版Stanford Alpaca不带input的模版。对于包含input字段的数据,采用f"{instruction}+\n+{input}"的形式进行拼接。 其中,Stanford Alpaca 格式如下

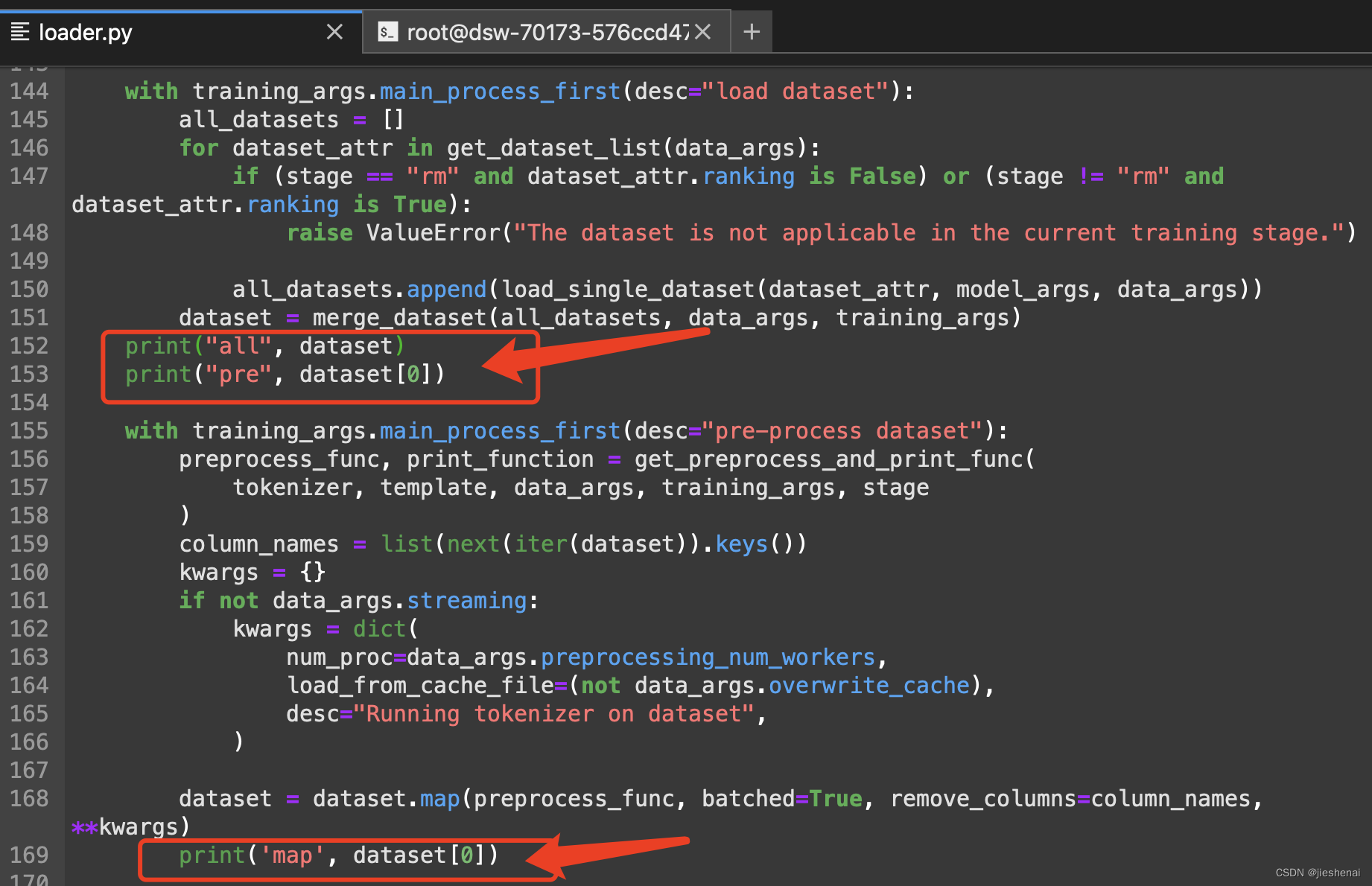
LLM - 数据处理之 Process Dataset For LLM With PT、SFT、RM
目录 一.引言 二.PT 数据流程 1.数据样式 2.生成代码 3.数据生成 三.SFT 数据流程 1.数据样式 2.生成代码 3.数据生成 四.RM 数据流程 1.生成逻辑 2.RM 模型测试 五.总结 一.引言 上篇文章 LLM - 批量加载 dataset 并合并介绍了如何加载多个文件并合成一个 dataset 数据集,本文基于上文生成的 datas