本文主要是介绍llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 简介
- 支持的模型列表
- 2. 添加自定义数据集
- 3. lora 微调
- 4. 大模型 + lora 权重,部署
- 问题
- 参考资料
简介
- llama-factory SFT系列教程 (一),大模型 API 部署与使用
- 本文为 llama-factory SFT系列教程的第二篇;
支持的模型列表
| 模型名 | 模型大小 | 默认模块 | Template |
|---|---|---|---|
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOM | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| DeepSeek (MoE) | 7B/16B/67B | q_proj,v_proj | deepseek |
| Falcon | 7B/40B/180B | query_key_value | falcon |
| Gemma | 2B/7B | q_proj,v_proj | gemma |
| InternLM2 | 7B/20B | wqkv | intern2 |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | - |
| LLaMA-2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| Mistral | 7B | q_proj,v_proj | mistral |
| Mixtral | 8x7B | q_proj,v_proj | mistral |
| OLMo | 1B/7B | att_proj | olmo |
| Phi-1.5/2 | 1.3B/2.7B | q_proj,v_proj | - |
| Qwen | 1.8B/7B/14B/72B | c_attn | qwen |
| Qwen1.5 | 0.5B/1.8B/4B/7B/14B/72B | q_proj,v_proj | qwen |
| StarCoder2 | 3B/7B/15B | q_proj,v_proj | - |
| XVERSE | 7B/13B/65B | q_proj,v_proj | xverse |
| Yi | 6B/9B/34B | q_proj,v_proj | yi |
| Yuan | 2B/51B/102B | q_proj,v_proj | yuan |
参考自:https://zhuanlan.zhihu.com/p/689333581
-
默认模块 作为 --lora_target 参数的默认值,也可使用 --lora_target all 参数指定全部模块;
-
–template 参数可以是 default, alpaca, vicuna 等任意值。但“对话”(Chat)模型请务必使用对应的模板。
项目所支持模型的完整列表请参阅 constants.py。
2. 添加自定义数据集
LLaMA-Factory 数据集说明,参考该文件给出的说明,在dataset_info.json 文件中添加配置信息;
参考如下数据集格式,定义自定义数据集;
[{"instruction": "用户指令(必填)","input": "用户输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
新数据集内容如下:
diy.json
[{"instruction": "你是谁?","input": "","output": "我是Qwen,edit by JieShin.","history": []},{"instruction": "你能帮我干些什么?","input": "","output": "我能和你互动问答,我的其他功能正在开发中。","history": []}
]
添加自定义数据集的步骤如下:
- 将
diy.json文件保存到LLaMA-Factory/data文件夹下;

- 在 dataset_info.json 文件中,配置数据集
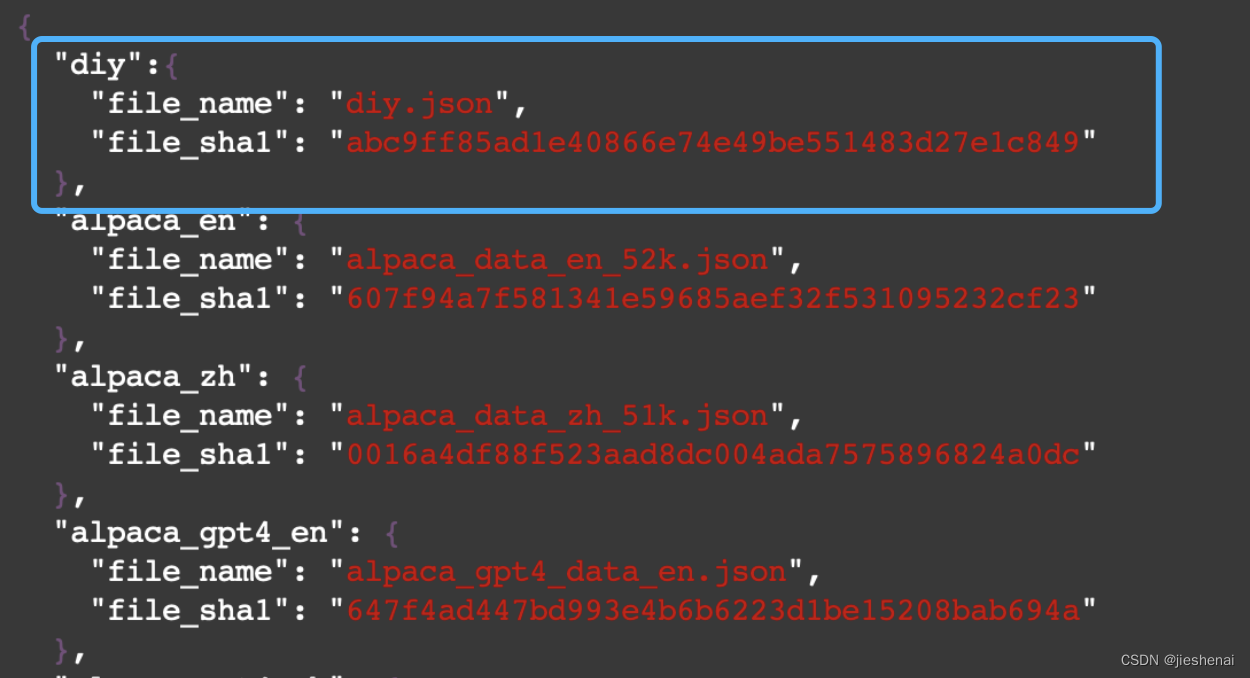
首先计算diy.json文件的sha1sum,sha1sum diy.json

vim dataset_info.json添加自定义数据集的配置信息, 把 diy.json 文件的sha1 值添加到文件中,"diy"为该数据集名;
3. lora 微调
使用配置好的 diy 数据集进行模型训练;
--model_name_or_path qwen/Qwen-7B,只写模型名,不写绝对路径可运行成功,因为配置了export USE_MODELSCOPE_HUB=1
查看 配置是否生效,输出1 即为配置成功:
echo $USE_MODELSCOPE_HUB

CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path qwen/Qwen-7B \
--dataset diy \
--template qwen \
--finetuning_type lora \
--lora_target c_attn \
--output_dir /mnt/workspace/llama_factory_demo/qwen/lora/sft \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_strategy epoch \
--learning_rate 5e-5 \
--num_train_epochs 50.0 \
--plot_loss \
--fp16
训练完成的lora 权重,保存在下述文件夹中;
--output_dir /mnt/workspace/llama_factory_demo/qwen/lora/sft
模型的训练结果如下:
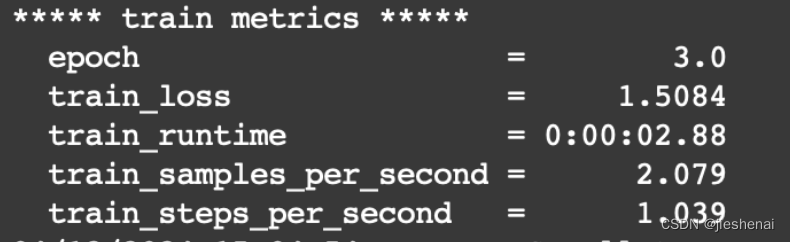
lora 训练后的权重如下图所示:

4. 大模型 + lora 权重,部署
由于llama-factory 不支持 qwen 结合 lora 进行推理,故需要把 lora 权重融合进大模型成一个全新的大模型权重;
可查看如下链接,了解如何合并模型权重:merge_lora GitHub issue
下述是合并 lora 权重的脚本,全新大模型的权重保存到 export_dir 文件夹;
CUDA_VISIBLE_DEVICES=0 python src/export_model.py \--model_name_or_path qwen/Qwen-7B \--adapter_name_or_path /mnt/workspace/llama_factory_demo/qwen/lora/sft/checkpoint-50 \--template qwen \--finetuning_type lora \--export_dir /mnt/workspace/merge_w/qwen \--export_size 2 \--export_legacy_format False
使用融合后到大模型进行推理,model_name_or_path 为融合后的新大模型路径
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 python src/api_demo.py \--model_name_or_path /mnt/workspace/merge_w/qwen \--template qwen \--infer_backend vllm \--vllm_enforce_eager \
~
模型请求脚本
curl -X 'POST' \'http://0.0.0.0:8000/v1/chat/completions' \-H 'accept: application/json' \-H 'Content-Type: application/json' \-d '{"model": "string","messages": [{"role": "user","content": "你能帮我做一些什么事情?","tool_calls": [{"id": "call_default","type": "function","function": {"name": "string","arguments": "string"}}]}],"tools": [{"type": "function","function": {"name": "string","description": "string","parameters": {}}}],"do_sample": true,"temperature": 0,"top_p": 0,"n": 1,"max_tokens": 128,"stream": false
}'
模型推理得到了和数据集中一样的结果,这说明 lora 微调生效了;

以为设置了
"stop": "<|endoftext|>",模型会在遇到结束符自动结束,但模型依然推理到了最长的长度后结束,设置的 stop 并没有生效;
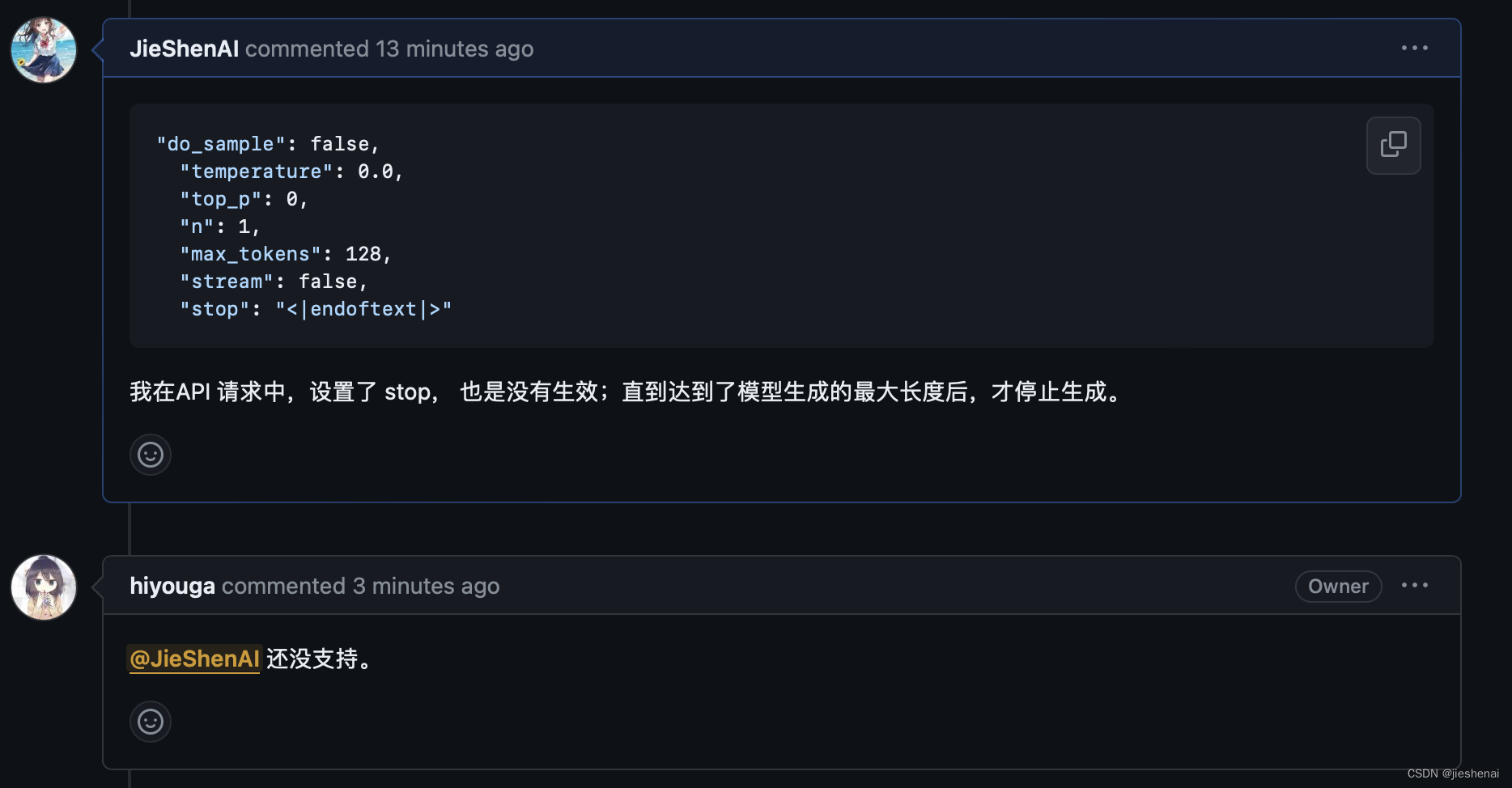
llama-factory的作者表示还没有支持stop,万一未来支持了stop功能,大家可以关注这个issue support “stop” in api chat/completions #3114
问题
虽然设置了 "temperature": 0 , 但是模型的输出结果依然变动很大,运行3-4次后,才出现训练数据集中的结果;
参考资料
- api 参数列表
- 使用LLaMa-Factory简单高效微调大模型
展示了支持的大模型列表;
这篇关于llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







