本文主要是介绍SFT调优,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SFT调优快速手册 - 千帆大模型平台 | 百度智能云文档
人工智能大语言模型微调技术:SFT、LoRA、Freeze 监督微调方法
什么是SFT
监督微调(SFT)是指采用预先训练好的神经网络模型,并针对你自己的专门任务在少量的监督数据上对其进行重新训练的技术。在千帆平台上已经预置了ERNIE-Bot系列大模型和BLOOM系列大模型。
rapidapi
API Hub - Free Public & Open Rest APIs | Rapid
RapidAPI是一个非常有用的工具,它可以帮助开发者快速地集成各种API.
监督微调的步骤
具体来说,监督式微调包括以下几个步骤:
- 预训练: 首先在一个大规模的数据集上训练一个深度学习模型,例如使用自监督学习或者无监督学习算法进行预训练;
- 微调: 使用目标任务的训练集对预训练模型进行微调。通常,只有预训练模型中的一部分层被微调,例如只微调模型的最后几层或者某些中间层。在微调过程中,通过反向传播算法对模型进行优化,使得模型在目标任务上表现更好;
- 评估: 使用目标任务的测试集对微调后的模型进行评估,得到模型在目标任务上的性能指标。
监督微调的特点
监督式微调能够利用预训练模型的参数和结构,避免从头开始训练模型,从而加速模型的训练过程,并且能够提高模型在目标任务上的表现。监督式微调在计算机视觉、自然语言处理等领域中得到了广泛应用。然而监督也存在一些缺点。首先,需要大量的标注数据用于目标任务的微调,如果标注数据不足,可能会导致微调后的模型表现不佳。其次,由于预训练模型的参数和结构对微调后的模型性能有很大影响,因此选择合适的预训练模型也很重要。
1.GPT 第1代模型定出了 GPT 系列模型的基本架构,即:GPT 的系列架构都是基于 Transformer 的 Decoder。
2. GPT-2 定出了 GPT 做各种下游任务的模式,即可以通过使用 Prompt 以一种 Zero-Shot 的方式完成下游任务,无需 Fine-Tuning,无需下游任务的领域内有标签数据。
3. GPT-3 不再执着于 Zero-Shot 的方式,即一条下游任务的数据都不用。而是把注意力集中在 Few-Shot 的方式,即只使用少量下游任务的数据。但是,GPT-3 强调把模型做得很大,最大的模型约 175B 的参数,大到这样的模型可以很好地完成 Few-Shot 的下游任务。预训练好的 GPT-3 在迁移到下游任务时,不进行任何的参数更新,仅仅依靠输入的例子和对问题的描述来完成。

ChatGPT 这个震惊世界的大模型训练方法其实是来自于 InstructGPT 的思想。InstructGPT 所使用的主要技术手段就是这个 Reinforcement Learning from Human Feedback (RLHF)。
关于 Reinforcement Learning from Human Feedback (RLHF) 这个技术,大致可以分为这么3部分:
1. 构造一个带有人类指令的数据集,进行有监督微调:作者们聘请了 40 个人的团队来标数据,主要是针对用户提交给 OpenAI API 的问题 (Prompts) 标了一些期望的回复 (human-written demonstrations),并使用这个标注的数据微调 GPT-3,这一步是个有监督学习 (Supervised Fine-Tuning)。但是值得注意的是,SFT 的数据集是一种对话形式的数据集,带有 Prompt,这种数据集的采集成本很大,所以通常数据的量级不大。
2. 构造一个新数据集,训练一个 Reward Model:对第1步训练的模型喂入一些 Prompt,使它输出多个结果。人类来打分,所得到的这些包含 {Prompt 和人类给的分数} 的数据集训练一个 Reward 模型。这个模型的作用是预测人类更喜欢模型的哪个输出。
3. 使用这个 RM 作为奖励函数,并使用 PPO 算法微调第1步训练的模型以最大化这个奖励:将第1步训练的 LLM 模型视为策略 (Policy),第2步训练的 Reward 模型视为环境 (Environment),采用 PPO 的 RL 方法训练 LLM 模型,得到最终的模型。
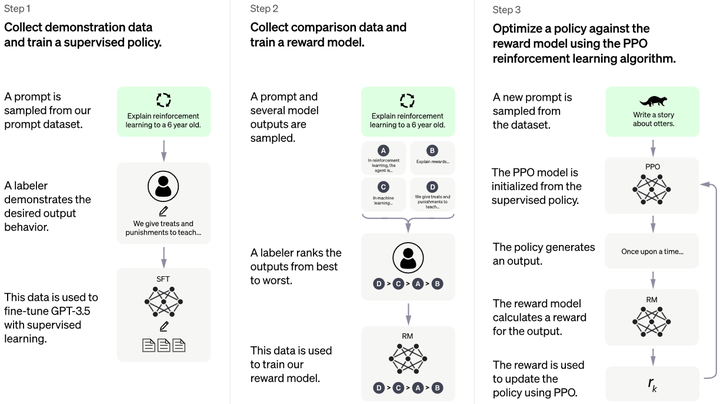
图1:RLHF 技术路线,图源:https://openai.com/blog/chatgpt
因为大语言模型无监督训练方法是 "从互联网上的大量语料库中学习根据上文来预测下一个词",它做的是个生成任务。而不是 "根据人类的指令生成有帮助,无害的对应答案"。换句话讲,你喂进去的文本里有什么,它就学到了什么,没法和人类的意图一致。在实际应用当中,如果我们部署这样的语言模型是会出问题的。
文本里面假如有这样的语料:{请给我算一道数学题,题目是 3+9=,答案是 12},那么使用这样的文本无监督训练好的模型,那么训练好以后你问它:"请给我算一道数学题,题目是 3+9=,答案是:",它就可能会输出正确的答案 12。
文本里面假如有这样的语料:{我说美国总统的任数,你来回答名字,题目是第44任,答案是奥巴马},那么使用这样的文本无监督训练好的模型,那么训练好以后你问它:"我说美国总统的任数,你来回答名字,题目是第44任,答案是:",它就可能会输出正确的答案奥巴马。
但是,你的文本是一段一段的文章,一本一本的书,谁能够保证这个文本里面有类似 {请给我算一道数学题,题目是 3+9=,答案是 12} 这么精确的,带有人类指令的话?
1. 假如 GPT-3 的训练文本中有很多类似的数据,那么训练好以后你问它:"请给我算一道数学题,题目是 3+9=,答案是:",它就可能会输出正确的答案 12。你问它:"我说美国总统的任数,你来回答名字,题目是第44任,答案是:",它就可能会输出正确的答案奥巴马。
2. 假如 GPT-3 的训练文本中没有类似的数据,我们其实就很难对模型的输出进行有效的控制。因为道理也很简单,训练好以后你问它:"请给我算一道数学题,题目是 3+9=,答案是:",它就可能会输出一堆乱七八糟不知所云的回答,而不会输出正确的答案 12。你问它:"我说美国总统的任数,你来回答名字,题目是第44任,答案是:",它就可能会输出一堆乱七八糟不知所云的回答,而不会输出正确的答案奥巴马。
本文介绍的 InstructGPT 这个技术力求语言模型在明面上遵循人类的意图,同时在暗面上满足:
- 生成内容对人类有帮助:能帮人解决问题。
- 生成内容诚实:不应该制造信息或误导用户。
- 生成内容无害:不应该对人或环境造成身体、心理或社会伤害。
InstructGPT 的作者团队首先构造一个带有人类指令的数据集,他们聘请了 40 个人的团队来标数据,主要是针对用户提交给 OpenAI API 的问题 (Prompts) 标了一些期望的回复 (human-written demonstrations),并使用这个标注的数据微调 GPT-3,这一步是个有监督学习。
问:简单地把语言模型再加大可以做到类似的事情吗?
答:已有的大语言模型似乎并不能遵循用户的意图,而且还可能会输出不真实、有毒的内容或者是废话。换句话说,这些模型与他们的用户没有对齐 (Align)。
1.2 InstructGPT 的新发现
1. 相比 GPT-3 的输出,打标签的人更喜欢 InstructGPT 的输出:比如在作者的测试集上,打标签的人更喜欢 1.3B 参数 InstructGPT 的输出相比于 100 倍大小的 175B GPT-3 的输出。InstructGPT 和 GPT-3 具有相同的架构,不同之处仅仅在于 InstructGPT 在人类数据上进行了微调。
2. InstructGPT 在生成内容的真实性上好于 GPT-3:在一些 TruthfulQA 评估的数据及上面,InstructGPT 生成真实和信息丰富的答案大约是 GPT-3 的两倍。并且 InstructGPT 生成一些 "编造" 答案大约是 GPT-3 的一半。
3. InstructGPT 在生成内容的毒性上比 GPT-3 略有改进,但依然存在偏见:作者通过 RealToxicityPrompts 这个数据集来评价语言模型生成内容的毒性,评价方法包含自动评价和人工评价。InstructGPT 模型产生的有毒输出比 GPT-3 少约 25%。InstructGPT 在 Winogender 和 CrowSPairs 数据集上相比于 GPT-3 并没有显着改善。
4. 可以通过修改 RLHF 微调过程来最小化公共 NLP 数据集上的性能回归。
5. InstructGPT 对那些不打训练集标签的人 ("held-out" labelers) 依然有泛化能力:作者发现那些不打训练集标签的人相比 GPT-3 的输出,更喜欢 InstructGPT 输出。
6. 公共 NLP 数据集不能反映 InstructGPT 的性能:作者将在人类偏好数据 (InstructGPT) 上微调的 GPT-3 与在两个不同公共 NLP 任务上微调的 GPT-3 (FLAN 和 T0) 进行比较。人类偏好数据数据集由各种 NLP 任务组成,且每个任务都涵盖一些自然语言的指令。在 API 提示分布上,FLAN 和 T0 模型的表现略低于 SFT 基线,并且标注工相比于 GPT-3 微调的模型,明显更喜欢 InstructGPT。
7. InstructGPT 模型对 RLHF 微调分布之外的指令具有很好的泛化能力:作者定性地探究 InstructGPT 的能力,发现 InstructGPT 能够遵循一些这样的指令,比如:总结代码的功能,问一些关于代码的问题。但是这些指令在微调的数据中很罕见。相比之下,GPT-3 也可以执行这些任务,但需要更仔细地设计 prompt,并且通常不会很好地遵循这些指令。这说明 InstructGPT 即使是在几乎没有直接监督信号的任务上,仍能保留一些基本能力。
8. InstructGPT 仍然犯简单的错误:InstructGPT 有时仍然无法遵循指令,甚至会编造事实,为一些简单问题生成冗长且复杂的回答,或者无法检测到带有错误前提的指令。
总体而言,InstructGPT 的结果表明,尽管安全性和可靠性还有待提高,但是使用人类偏好微调大型语言模型可以显着提高它们在很多任务上的行为。
想要微调一个大模型,前提是得有一份高质量的SFT数据,可以这么说其多么高质量都不过分,关于其重要性已经有很多工作得以验证,感兴趣的小伙伴可以穿梭笔者之前的一篇文章:
《大模型时代下数据的重要性》:https://zhuanlan.zhihu.com/p/639207933
今天我们来简单总结一下目前市面上 “怎么自动化准备SFT数据” 这个话题,并给出对应的参考文献,感兴趣的小伙伴可以自己阅读论文了解细节。注意这里只是介绍机器自动化生成数据,如果有垂类网站等能够爬取真实人类的数据那更好了。
SFT数据无外乎就是<prompt, response> pair,也就是需要准备好高质量的prompt和高质量的response。
那我们就以这两个角度分开看看现在的paper们是怎么分别在prompt和response发力的。
准备prompt
- SELF-INSTRUCT
代表工作有:
《SELF-INSTRUCT: Aligning Language Models with Self-Generated Instructions》: https://arxiv.org/pdf/2212.10560.pdf
BELLE : https://github.com/LianjiaTech/BELLE
其核心是先有一批sft种子数据,然后通过few-shot的形式让模型再生成新的prompt,它的prompt 如下:
You are asked to come up with a set of 30 diverse task instructions. These task instructions will be given to a GPT model and we will evaluate the GPT model for completing the instructions.Here are the requirements:
1. Try not to repeat the verb for each instruction to maximize diversity.
2. The language used for the instruction also should be diverse. For example, you should combine questions with imperative instrucitons.
3. The type of instructions should be diverse. The list should include diverse types of tasks like open-ended generation, classification, editing, etc.
4. A GPT language model should be able to complete the instruction. For example, do not ask the assistant to create any visual or audio output. For another example, do not ask the assistant to wake you up at 5pm or set a reminder because it cannot perform any action.
5. The instructions should be in English.
6. The instructions should be 1 to 2 sentences long. Either an imperative sentence or a question is permitted.
7. You should generate an appropriate input to the instruction. The input field should contain a specific example provided for the instruction. It should involve realistic data and should not contain simple placeholders. The input should provide substantial content to make the instruction challenging but should ideally not exceed 100 words.
8. Not all instructions require input. For example, when a instruction asks about some general information, "what is the highest peak in the world", it is not necssary to provide a specific context. In this case, we simply put "<noinput>" in the input field.
9. The output should be an appropriate response to the instruction and the input. Make sure the output is less than 100 words.
10. Make sure the output is gramatically correct with punctuation if needed.
List of 30 tasks:
- Wizard
该系列思路是进化学习,其代表工作有:
WizardLM: https://arxiv.org/abs/2304.12244
WizardCoder: https://arxiv.org/abs/2306.08568
WizardMath: https://github.com/nlpxucan/WizardLM/tree/main/WizardMath
上面两幅图也很生动的表达了其思路,其核心也是先有一批种子prompt,然后让模型自动化生产新的prompt,只不过不同于self-instruct的是其做了更精细的prompt engineering来进行生成。具体来说其从深度和广度两个方向对prompt进行了进化。
深度进化:其旨在不改变原prompt语义情况下增加难度,具体包括五种操作:添加约束条件、加深理解、具体化、增加推理步骤和复杂化输入。一个prompt engineering如下:
I want you act as a Prompt Rewriter.
Your objective is to rewrite a given prompt into a more complex version to make those famous AI systems (e.g., ChatGPT and GPT4) a bit harder to handle.
But the rewritten prompt must be reasonable and must be understood and responded by humans.
Your rewriting cannot omit the non-text parts such as the table and code in #Given Prompt#:. Also, please do not omit the input in #Given Prompt#.
You SHOULD complicate the given prompt using the following method:
Please add one more constraints/requirements into #Given Prompt#
You should try your best not to make the #Rewritten Prompt# become verbose, #Rewritten Prompt# can only add 10 to 20 words into #Given Prompt#.
‘#Given Prompt#’, ‘#Rewritten Prompt#’, ‘given prompt’ and ‘rewritten prompt’ are not allowed to appear in #Rewritten Prompt#
#Given Prompt#:
<Here is instruction.>
#Rewritten Prompt#:
广度进化:基于给定指令生成一个全新的指令,一个prompt engineering如下:
I want you act as a Prompt Creator.
Your goal is to draw inspiration from the #Given Prompt# to create a brand new prompt.
This new prompt should belong to the same domain as the #Given Prompt# but be even more rare.
The LENGTH and difficulty level of the #Created Prompt# should be similar to that of the #Given Prompt#. The #Created Prompt# must be reasonable and must be understood and responded by humans.
‘#Given Prompt#’, ‘#Created Prompt#’, ‘given prompt’ and ‘created prompt’ are not allowed to appear in #Created Prompt#.
#Given Prompt#:
<Here is instruction.>
#Created Prompt#:
当然并不是每次进化出的prompt都是可用的,所以需要过滤掉,以下四类情况被归类为指令演化失败:
1 与原始指令相比,进化后的指令没有提供任何信息增益(使用ChatGPT进行验证);
2 生成出的指令让LLMs难以回复;(例如当回复包含sorry而且比较短的时候)
3 LLMs生成的回复只包含标点和停止词;
4 进化指令显然从演化中的提示中复制了一些单词,如“给定提示”、“重写提示”、“#重写提示#”等。
- Backtranslation
这里的思路另辟蹊径即使用回译的思路,代表工作有:
《Self-Alignment with Instruction Backtranslation》: https://arxiv.org/pdf/2308.06259.pdf
该工作的前提是要求有一大批未标注的样本比如非常大的文本集(未标记样本集)、sft种子数据。然后用<response, prompt>去训练一个模型论文叫做backward model,可以看到其和sft模型恰好相反,backward model是根据response生成prompt,当训练好模型后就可以喂未标注的大规模样本生成prompt了。
准备response
- sample distillation
最简单也是目前大家最常用的方法就是根据prompt去直接拉取chatgpt甚至是GPT4的回复作为response即直接蒸馏openai,因为chatgpt和GPT4两个天花板模型本身能力非常强,这在一定程度上能够保证response的质量。
- cot distillation
该类思路是说即使是chatgpt和GPT4也不能精确的回复一些高难度的prompt比如数学和推理类prompt,导致自动化得到的response不可用,为此可以做一些思维链来辅助其生成更可行的response,最简单的cot就是大家常见的增加一些类似“请详细给出答案”或者“请一步步推理”等等,下面我们介绍几篇比较复杂的cot工作:
《Tree of Thoughts: Deliberate Problem Solving with Large Language Models》:https://arxiv.org/abs/2305.10601
也是从深度&广度两个方向进行思维链,论文中将其称为cot的加强版ToT,对多个思维链进行采样,并将它们的结果进行投票可以进一步提高LLMs的推理准确性。
《Answering Questions by Meta-Reasoning over Multiple Chains of Thought》:https://arxiv.org/pdf/2304.13007.pdf
简单来说思路就是通过外挂知识库也就是paper中说的证据来提高回复的准确性,首先把原始prompt进行拆解,然后分别检索证据即多条思维链,最后进行汇总。
《SCALING RELATIONSHIP ON LEARNING MATHEMATI- CAL REASONING WITH LARGE LANGUAGE MODELS》:https://arxiv.org/pdf/2308.01825.pdf
该篇paper重在解决数学问题。其基本思路是同一个prompt去调用不同的大模型进而得到不同的解题思路也即不同的思维链,当然要过滤掉最后结果不正确的思维链。通过这样就得到了大量的数据集。
总结
从上面的系列工作不难看出,都是使用LLM模型来自己生成prompt和response数据。总体生成idea就是由简单->复杂。
prompt : 由简单self-instruct -> 复杂的进化学习
response : 简单蒸馏 -> cot蒸馏 -> 多模型蒸馏
复杂化的手段有很多,比如上面的进化学习、cot、多模型等等,我们可以将这些方法论分别进一步互相借鉴套用到prompt和response各种领域,比如将多模型蒸馏用到生成prompt,用多个模型分别做进化学习生成promot,再比如借鉴进化学习,我们可以对一个response进行rewrite,让他写的更长更复杂甚至我们给模型一个<prompt, response>,然后让他根据目前的prompt写一个比目前reponse更好的reponse。
除了互相借鉴,我们还可以将这些方法论进行任意叠加组合,比如先进行得到prompt,然后多模型cot得到response等等。
这篇关于SFT调优的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





