本文主要是介绍【LLM】sft和pretrain数据处理和筛选方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
note
- 痛点:训练垂直领域模型,sft数据和增量pretrain数据质量把控很重要
- 当数据不够时,通过self-instruct等方法造多样化的数据
- 当数据很多时,需要清洗/筛选出高质量数据
文章目录
- note
- 一、sft数据的筛选策略
- 1.1 使用self-instruct构造sft数据
- 1.2 筛选高质量sft数据
- 1.3 评估sft数据质量和数量
- 二、pretrain数据的筛选策略
- 2.1 预训练数据
- 2.2 清洗pretrain数据流程
- 2.3 评估pretrain数据质量
- Reference
一、sft数据的筛选策略
内容概要:
- 构造sft数据
- 评估sft数据质量和数量
- 自动化筛选高质量sft数据
1.1 使用self-instruct构造sft数据
论文:《Self-Instruct: Aligning Language Model with Self Generated Instructions》
self-instruct构造数据:指令生成;实例生成;过滤和后处理(原self-instruct方法在第一步后有分类任务识别,但现在主流方法都是省略这步)。
![[图片]](https://img-blog.csdnimg.cn/c2fd84cade404ab59a573ec9fdeaeb43.png)
(1)生成指令:
- 每次从任务种子池(每个任务有一条指令+一条实例)中随机抽取8条数据
- 划分task粒度可控,如阅文打斗场景,可以分为操场、山顶、平地等打斗场景描写的task。
# seed data
{"id": "seed_task_0", "name": "breakfast_suggestion", "instruction": "Is there anything I can eat for a breakfast that doesn't include eggs, yet includes protein, and has roughly 700-1000 calories?", "instances": [{"input": "", "output": "Yes, you can have 1 oatmeal banana protein shake and 4 strips of bacon. The oatmeal banana protein shake may contain 1/2 cup oatmeal, 60 grams whey protein powder, 1/2 medium banana, 1tbsp flaxseed oil and 1/2 cup watter, totalling about 550 calories. The 4 strips of bacon contains about 200 calories."}], "is_classification": false}# prompt
Come up with a series of tasks:
Task 1: {instruction for existing task 1}
Task 2: {instruction for existing task 2}
Task 3: {instruction for existing task 3}
Task 4: {instruction for existing task 4}
Task 5: {instruction for existing task 5}
Task 6: {instruction for existing task 6}
Task 7: {instruction for existing task 7}
Task 8: {instruction for existing task 8}
Task 9:
(2)生成实例:利用(1)的指令给gpt
(3)过滤和后处理:衡量新数据和池中已有指令数据的相似度,只有当它和池中任何一条指令数据的 ROUGE-L 相似度都低于 0.7 的时候,才能会被加入到指令池中
![[图片]](https://img-blog.csdnimg.cn/11242fab7e8b491b87abe014e1fc511a.png)
1.2 筛选高质量sft数据
(1)sft数据的清洗
- 背景:针对gpt等大模型构造的指令数据,进行sft数据清洗
- AlpacaDataCleaned(https://github.com/gururise/AlpacaDataCleaned)项目:提供Alpaca数据集的干净版本
通过消除错误和不一致,提高微调的alpaca模型性能,并减少幻觉的可能性。 - 清洗大模型生成的sft数据的方法:https://github.com/gururise/AlpacaDataCleaned/tree/main/tools
- 检查数据集的input是否存在潜在问题。
- 询问 GPT-3.5 对于给定的指令和输入是否正确、对应。
- 检查数据集中是否有合并的指令。
- 检查output是否有问题,如阅文的角色灵感场景,是否有截断现象、输出是否符合字典要求等
(2)通过IFD指标筛选sft数据
(1)论文:《From Quantity to Quality: Boosting LLM Performance with Self-Guided Data Selection for Instruction Tuning》平安科技:从大量可用数据集中自动识别高质量数据
- Paper: https://arxiv.org/abs/2308.12032
- Github: https://github.com/MingLiiii/Cherry_LLM
- 核心内容:提出一个指令跟随难度(Instruction-Following Difficulty,IFD)指标,通过该指标来筛选具有增强LLM指令调优潜力的数据样例(樱桃数据,cherry data),而模型仅使用原始数据5%-10%的cherry数据就可以达到全量数据微调的效果,甚至可以有所提高。
- 启发思想:清洗sft数据后可以通过计算IFD,自动化筛选出IFD top-k数据进行微调
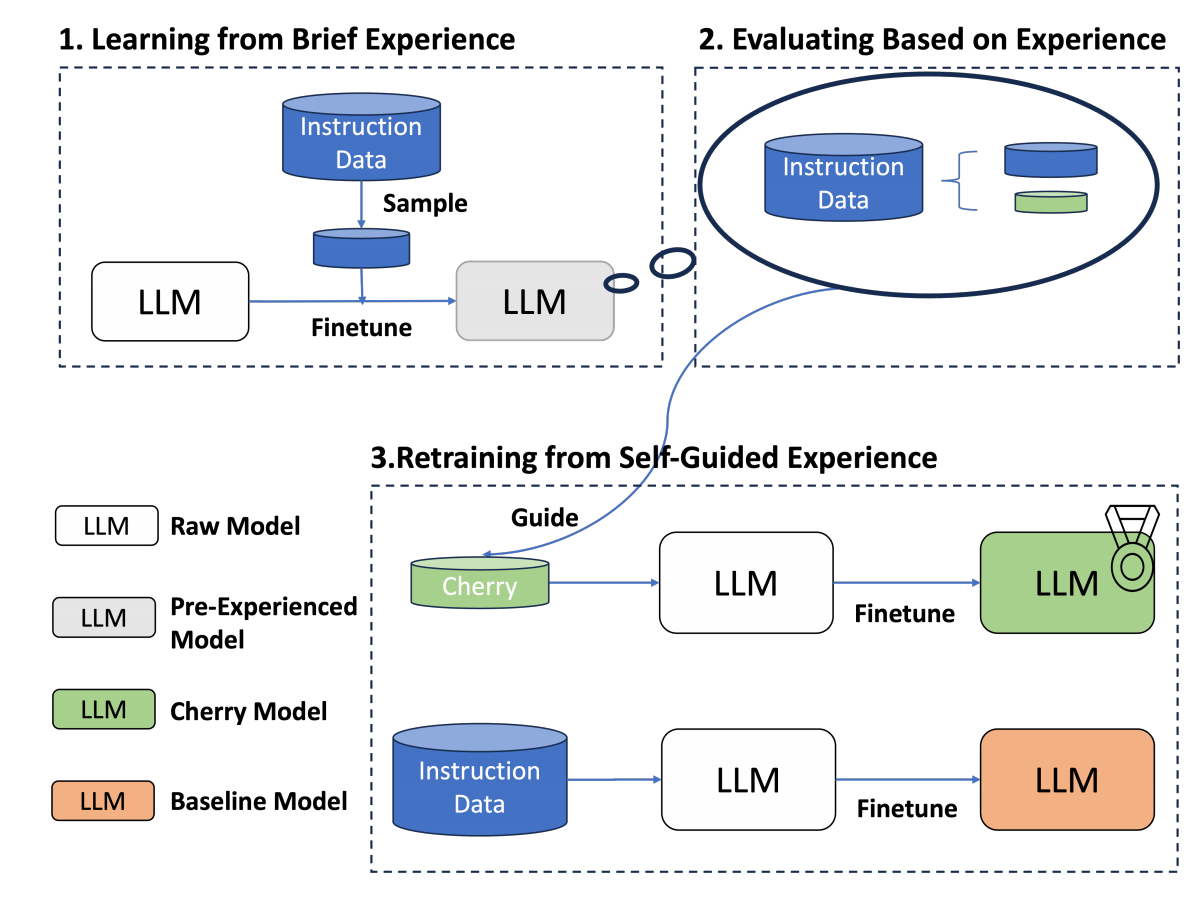
(2)三个步骤:
- step1:利用少量(文中是1k)进行模型sft初学;
- base model一般只能续写,没有指令遵循能力,选少量数据先训练v1模型
- 300样本时模型开始有一定的指令遵循能力
- 为保证数据多样性,使用Kmeans对所有数据聚类为100个簇,每个簇里选10个样本,base model在这1k条数据中sft一个epoch得到Brief Experience model
- step2:利用初学模型计算所有原始数据中IFD指标;
- 条件回答分数CAS:Conditioned Answer Score,模型对指令Q生成答案A的难易程度
- CAS: L θ ( A ∣ Q ) = 1 N ∑ i = 1 N log P ( w i A ∣ Q , w 1 A , w 2 A , … , w i − 1 A ; θ ) L_\theta(A \mid Q)=\frac{1}{N} \sum_{i=1}^N \log P\left(w_i^A \mid Q, w_1^A, w_2^A, \ldots, w_{i-1}^A ; \theta\right) Lθ(A∣Q)=N1i=1∑NlogP(wiA∣Q,w1A,w2A,…,wi−1A;θ)
- (Q, A)是一个问答对
- CAS: L θ ( A ∣ Q ) = 1 N ∑ i = 1 N log P ( w i A ∣ Q , w 1 A , w 2 A , … , w i − 1 A ; θ ) L_\theta(A \mid Q)=\frac{1}{N} \sum_{i=1}^N \log P\left(w_i^A \mid Q, w_1^A, w_2^A, \ldots, w_{i-1}^A ; \theta\right) Lθ(A∣Q)=N1i=1∑NlogP(wiA∣Q,w1A,w2A,…,wi−1A;θ)
- 直接答案分数DAS:Brief Experience model模型对答案续写,计算DAS:
- DAS: s θ ( A ) = 1 N ∑ i = 1 N log P ( w i A ∣ w 1 A , … , w i − 1 A ; θ ) s_\theta(A)=\frac{1}{N} \sum_{i=1}^N \log P\left(w_i^A \mid w_1^A, \ldots, w_{i-1}^A ; \theta\right) sθ(A)=N1i=1∑NlogP(wiA∣w1A,…,wi−1A;θ)
- 指令跟随难度IFD:指令跟随难度指标,数值越大表明该条指令数据的难度越高,对模型微调更有利。
- IFD: r θ ( Q , A ) = s θ ( A ∣ Q ) s θ ( A ) r_\theta(Q, A)=\frac{s_\theta(A \mid Q)}{s_\theta(A)} rθ(Q,A)=sθ(A)sθ(A∣Q),
- 条件回答分数CAS:Conditioned Answer Score,模型对指令Q生成答案A的难易程度
- step3:利用cherry数据进行模型重训练得到最终的sft model。
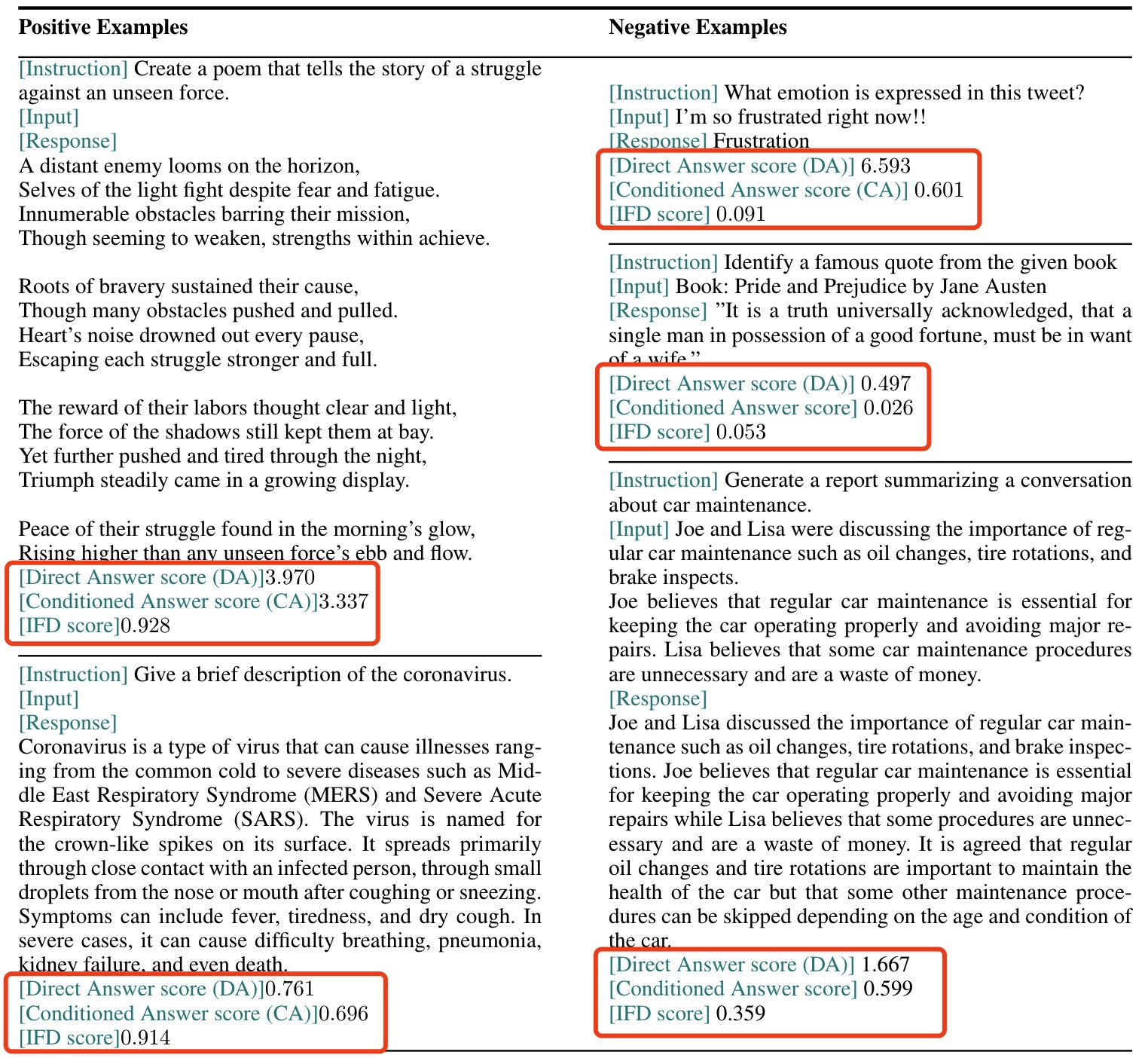
举例子:
- 如下的positive example:条件回答分数CAS越高表示给定的指令,越难生成对应的target部分,CAS越大越好;直接答案分数DAS越高表示预训练的LLM越不容易生成该文本。
- 第一个:CAS和DAS都较高,并且最终的IFD指标也是较高的(是更好的sample);该CAS较高,说明给定instruction生成对应的target是更难的
- 第二个:CAS和DAS都较低,这里的DAS较低是好事,表示LLM直接写出target是难的
- 如下的negative example:
- 第一个:target长度较短,而较短的文本一般困惑度较低,所以该较短的文本DAS数值较高example1更大
- 注意:在项目代码中,条件答案得分(CA)等同于计算loss,猜测是计算instruction+input+answer部分的loss;直接答案得分(DA),是直接answer部分的loss
获取中间置信度的数据:
对类中心的数据点排序->如果某个类数据不够,全采->获取这个类别的的置信度,置信度来自于样本的ppl值->获取最低的ppl阈值和最大的阈值->将最低阈值和最大阈值之间的数据作为中间数据上->如果中间阈值过滤数据量不够采样数量,则全部使用->否则切分成n份进行采样
(3)实验结果:在Alpaca和WizardLM两个数据集上利用Llama-7B进行实验,发现在5%的Alpaca樱桃数据上进行训练就超过了全量数据训练结果。

- 结果对比:对比随机采样、IFD采样、IFD低分采样、CAS采样四种方法对模型指令微调的影响,发现IFD采样在不同数据比例下,均高于全量数据微调效果,但其他采样方法均低于全量数据微调方法。
1.3 评估sft数据质量和数量
(1)sft数据的数量
1)《LIMA: Less Is More for Alignment》哈佛:sft数据质量的重要性大于数量
- Superficial Alignment Hypothesis假设:任务大模型在pretrain阶段已经学习完所有知识,sft是学习与用户交互的方式和风格
- LIMA模型:
- LIMA是一个65b的llama微调模型,没有使用rlhf强化学习
- 单轮对话场景:
- 数据:一共1k条高质量sft数据,有人工手写250条数据,有从社区问答中抽取750个热门问答对,并且在有的prompt中加入let’s think step by step
- 多轮对话场景:30个高质量多轮对话样本微调后,就能大幅度提高多轮对话能力
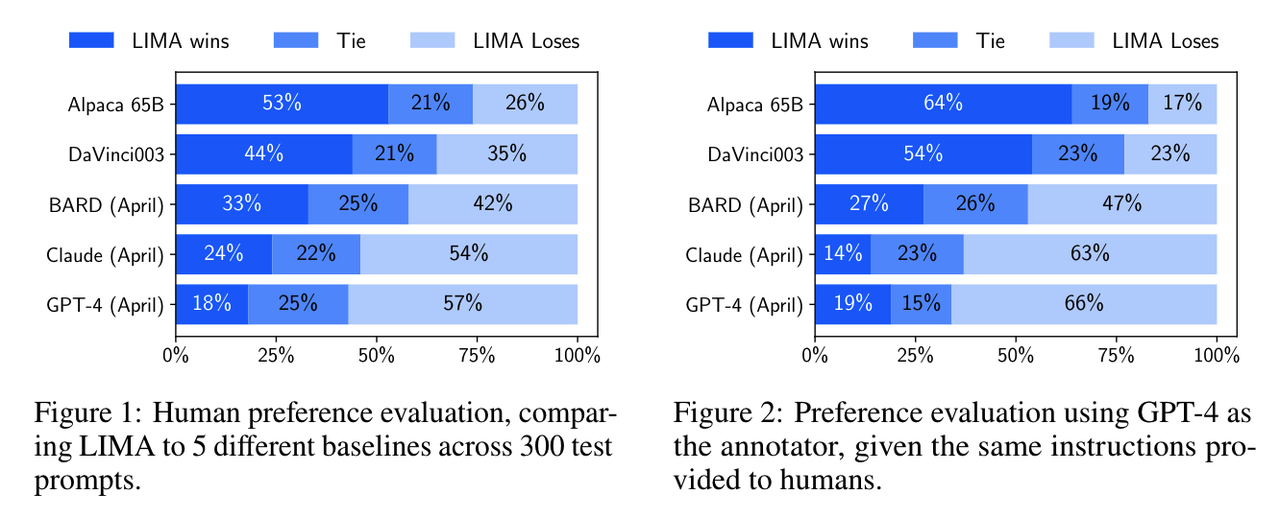
- LIMA模型和其他模型对比结果:
- LIMA的效果优于Alpaca 65B及DaVinci003(尽管它们训练数据量远大于LIMA,且DaVinci003使用了RLHF进行微调,且Alpaca 65B参数量大很多,是在52000条数据调sft数据进行微调)。
- 结果支持了文中最初的假设。
2)论文:《Exploring the Impact of Instruction Data Scaling on Large Language Models:An Empirical Study on Real-World Use Cases》贝壳
- 对于翻译、改写和头脑风暴任务,200万甚至更少的数据量可以使模型表现良好。
- 对于提取、分类、封闭式QA和总结摘要任务,模型的性能可以随着数据量的增加而继续提高,这表明仍然可以通过简单地增加训练数据量来提高模型的性能,但改进的潜力可能是有限的。
- 模型在数学、代码和COT上的表现仍然很差,需要在数据质量、模型规模和训练策略上进一步探索。
3)按照比例筛选sft数据
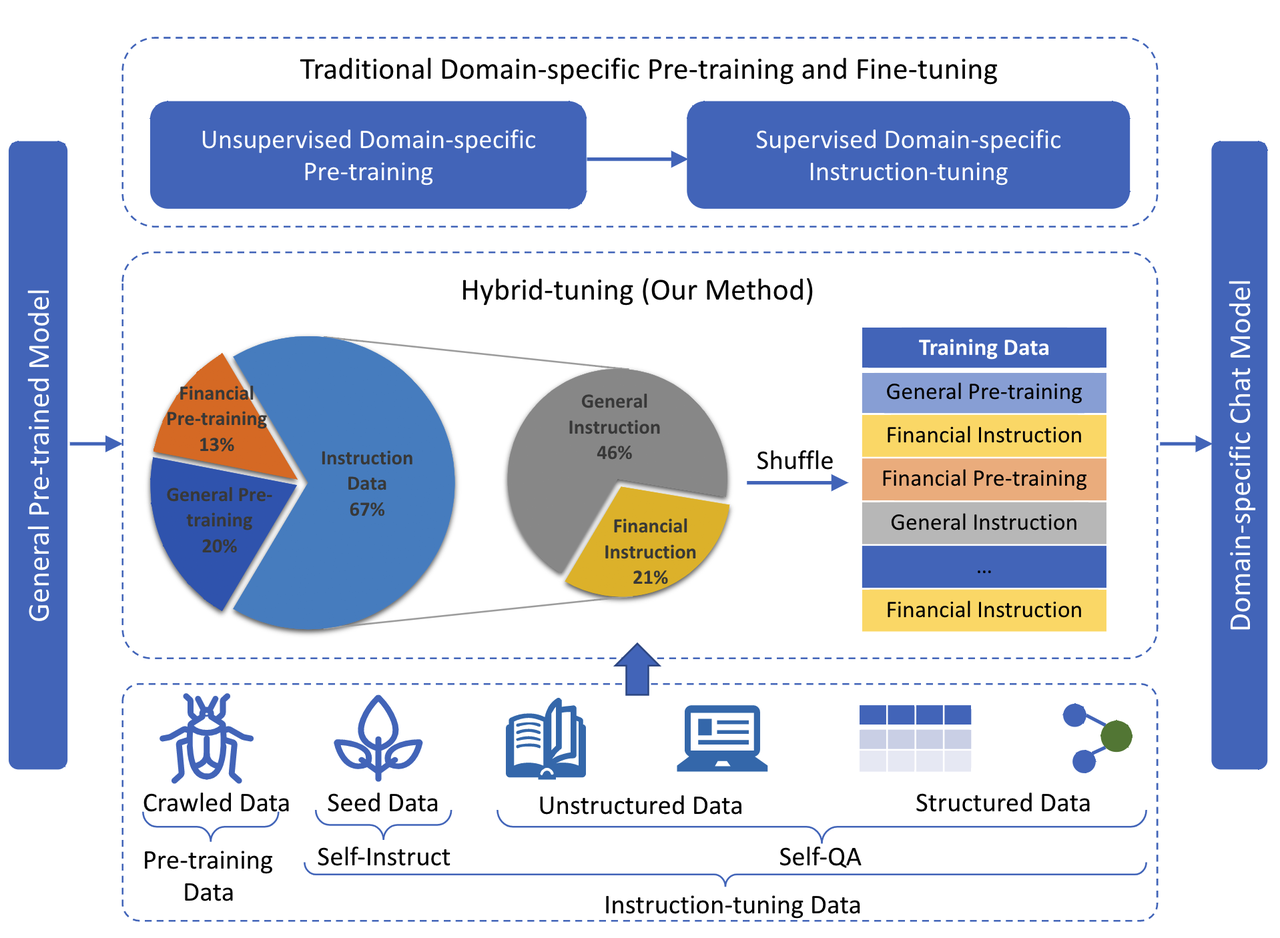
度小满金融大模型:https://github.com/Duxiaoman-DI/XuanYuan
- 基于bloom-176B模型,训练了一个中文金融大模型,提出【混合微调】缓解catastrophic forgetting(灾难性遗忘)问题
- 混合数据微调
- Pretrain data:从网上爬取,清洗过滤。
- Sft data:使用人工编写的种子指令通过 Self-Instruct (Wang et al., 2022) 收集通用数据,并利用金融领域的非结构化和结构化数据通过 Self-QA 收集特定领域的指令数据 (张和杨,2023)。
- 通用sft数据和领域sft数据的比例:如下图
(2)sft数据的质量
- 论文:《Instruction Mining: High-Quality Instruction Data Selection for Large Language Models》
- 核心内容:INSTRUCTMINING是一种线性质量规则和指标,用于评估指令跟随数据的质量,并通过在LLAMA-7B模型上进行广泛的微调实验来估计INSTRUCTMINING的参数。该工作的方法只在单轮指令遵循和大部分由人类撰写的数据集上进行了实验,还没有在多轮和更复杂的对话数据集上进行测试。
(1)当前评估sft数据质量的一些指标:
Length
Rewardscore
Perplexity
MTLD
KNN-i
Unieval-naturalness
Unieval-coherence
Unieval-understandability
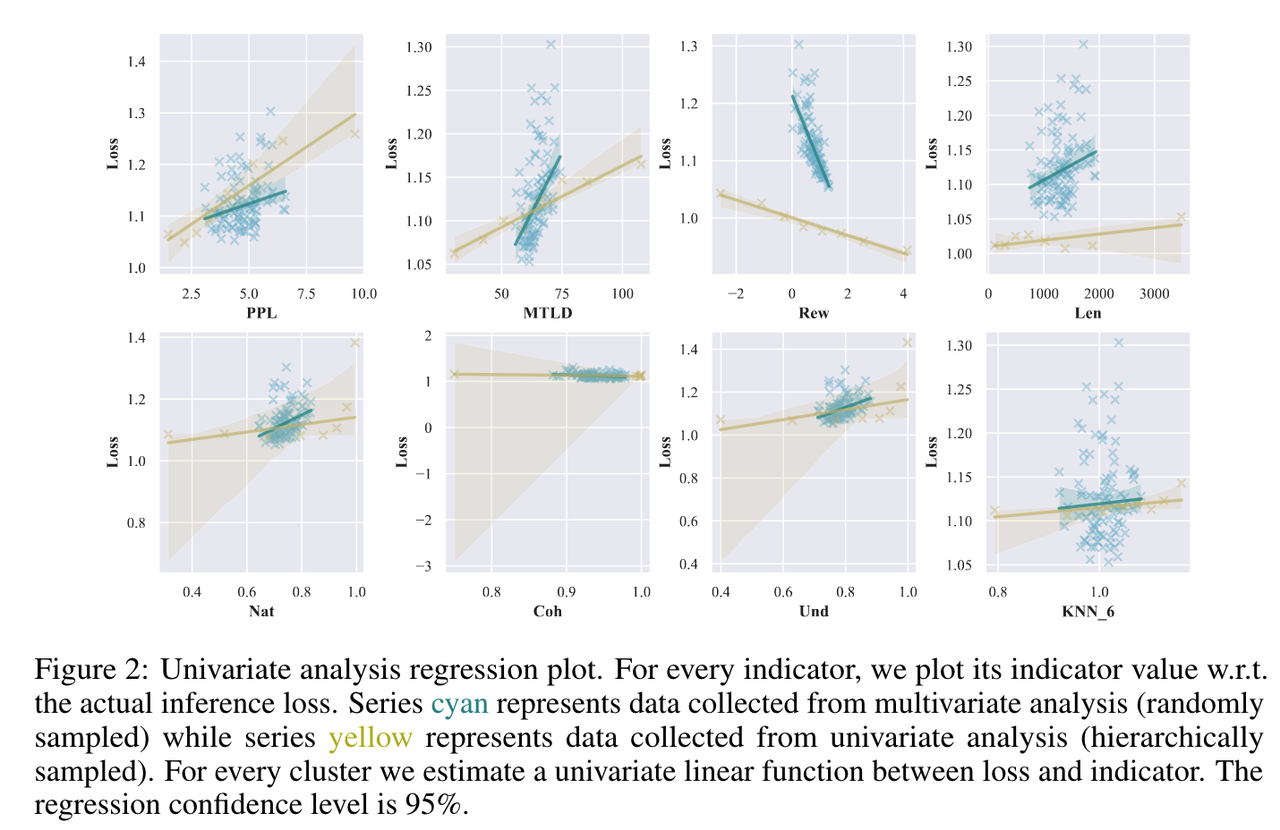
(2)文中定义sft数据质量公式: Q D ∣ M , S ∝ − L ( M ~ , D eval ) Q_{D \mid M, S} \propto-L\left(\tilde{M}, D_{\text {eval }}\right) QD∣M,S∝−L(M~,Deval )
- D eval D_{\text {eval }} Deval :高质量、无偏见的评估数据集
- 设计实验来研究指标与数据集质量之间的多变量和单变量相关性,然后以此挑选微调数据
- 结论:
- PPL、MTLD、Nat和Und与预期评估损失呈正相关,表明这些变量数值增加,evaluation loss更高,所以这些变量越低越好。
- RewardScore、Coh与evaluation loss呈负相关,所以这些变量数值可以适当增大。
二、pretrain数据的筛选策略
内容概要:
- 预训练数据
- 清洗pretrain数据流程
- 评估pretrain数据质量:困惑度(perplexity)、错误L2范数(ErrorL2-Norm)和记忆化(memorization)
2.1 预训练数据
增量pretrain:可适当加入如下的通用语料(下图为常见的pretrain语料)
![[图片]](https://img-blog.csdnimg.cn/7dcb3c5f33d146fab3afb5662d478859.png)
2.2 清洗pretrain数据流程
- 论文:《When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale》
- 方法:
- step1:进行语言识别,以便适当地将数据分配给相应的语言,剔除非目标任务语言
- step2:规则方法
-
丢弃perplexity高的文本数据(过滤一些不自然的文本)

-
删去标点/符号过多、过长过短的句子
-
删除具有某些特定词汇(如html标签、链接、脏话、敏感词)的句子。
-
- step3:通过轻量级模型进行过滤,如通过KenLM语言模型,以避免出现噪声文档。
- step4:进行数据去重,以去除相似或重复的信息。在文档层面进行模糊重复数据删除,例如通过MinHash来删除相似文档,从而减少记忆并提高LLM的泛化效果。
- 包含大量重复词汇或短语的句子可以删掉;
- 重复率(词/n-grams共现)过高的段落可以删掉;
- 删除训练集中可能与测试集相关度过高的内容,这样可以缓解语言模型生成内容重复的问题,避免测试集泄露带来的过拟合问题。
- 开源工具:FastText、CC-Net、MinHashLSH等
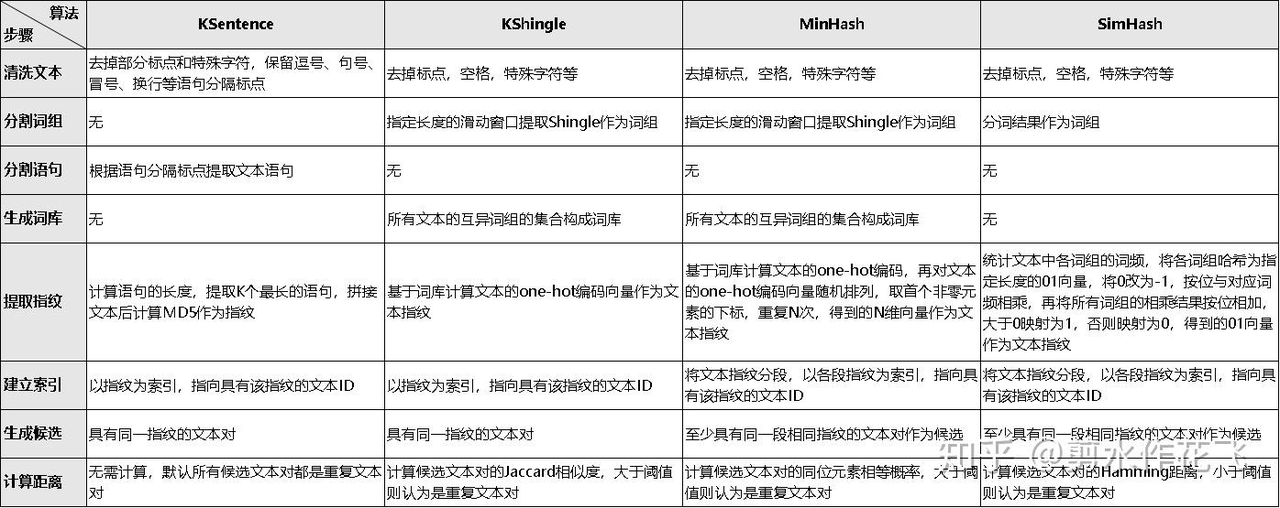
(2)去重算法总结:
(3)参考数据集:CulturaX数据集经过严格的多阶段清理和重复数据删除,以达到最佳的模型训练质量,包括语言识别、基于URL的过滤、基于度量的清理、文档再细化和重复数据删除。
地址:https://arxiv.org/pdf/2309.09400.pdf
数据地址:https://huggingface.co/datasets/uonlp/CulturaX
2.3 评估pretrain数据质量
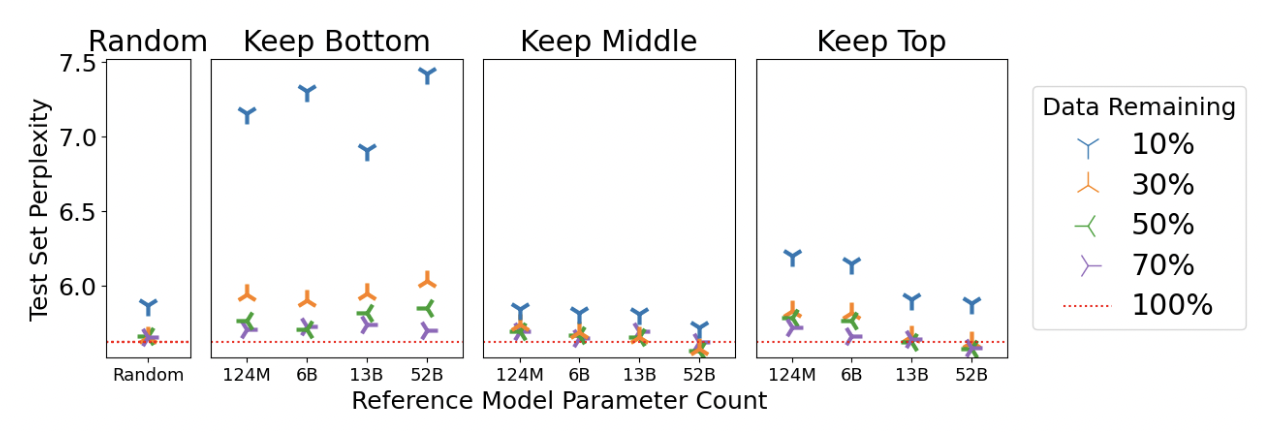
- 论文:《When Less is More: Investigating Data Pruning for Pretraining LLMs at Scale》
- 核心内容:数据剪枝(过滤),主流的方法是基于规则的手工启发式过滤方法,比如写正则表达式,本文使用三个指标评估pretrain质量:困惑度(perplexity)、错误L2范数(ErrorL2-Norm)和记忆化(memorization),提出数据剪枝方法。
- 结论:
- 与使用EL2N和记忆化对50%的数据集进行剪枝的性能最好的模型相比,基于困惑度对50%的数据集进行剪枝的模型分别提高了1.33%和1.77%。
- 与使用EL2N和记忆因子剪枝到30%数据集的性能最好的模型相比,使用困惑度剪枝到30%数据集的模型分别提高了2.1%和1.6%。
实验细节:
- 删除简单实例可提高性能,简单实例比如困惑度低的底层样本、使用EL2N指标低的底层样本、使用memorization指标时记忆最彻底的顶部样本
- 使用较大参考模型的剪枝优势更大
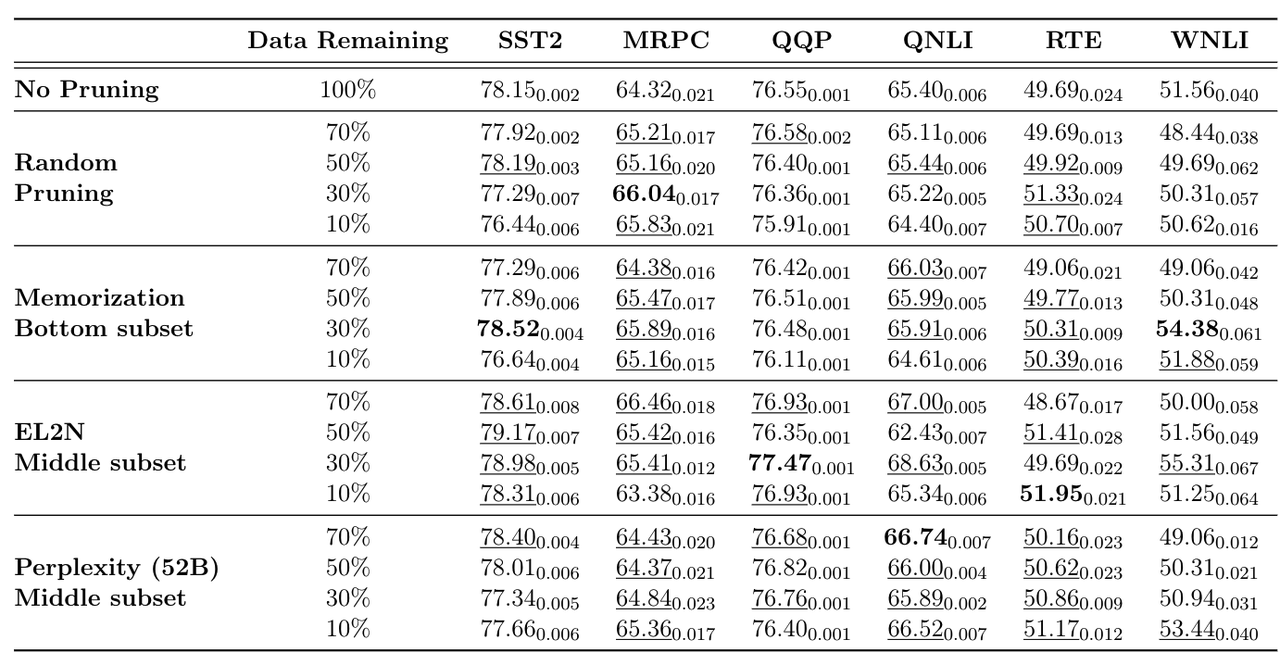
基于剪枝后的数据微调后的模型评测结果(GLUE任务的子集上对模型进行了微调和评估):
Reference
[1] https://github.com/gururise/AlpacaDataCleaned
[2] 大模型如何在指令微调过程中构造或筛选高质量数据.zh
[3] 有被混合后的SFT数据伤到.sft数据混合比例
[4] https://arxiv.org/pdf/2310.05492.pdf
这篇关于【LLM】sft和pretrain数据处理和筛选方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




