sampling专题

FouriDown: Factoring Down-Sampling into Shuffling and Superposing
摘要 https://openreview.net/pdf?id=nCwStXFDQu 空间下采样技术,如步长卷积、高斯下采样和最近邻下采样,在深度神经网络中至关重要。在本文中,我们重新审视了空间下采样家族的工作机制,并分析了先前方法中使用的静态加权策略所引起的偏差效应。为了克服这种偏差限制,我们提出了一种在傅里叶域中的新型下采样范式,简称FouriDown,它统一了现有的下采样技术。受信号采

点云处理中阶 Sampling
目录 一、什么是点云Sampling 二、示例代码 1、下采样 Downsampling 2、均匀采样 3、上采样 4、表面重建 一、什么是点云Sampling 点云处理中的采样(sampling)是指从大量点云数据中选取一部分代表性的数据点,以减少计算复杂度和内存使用,同时保留点云的几何特征和重要信息。常见的点云采样方法有以下几种: 随机采样(Random Samp

Llama模型家族之拒绝抽样(Rejection Sampling)(九) 强化学习之Rejection Sampling
LlaMA 3 系列博客 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三) 基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四) 基于 LlaMA 3

蓄水池采样 Reservoir Sampling
# coding:utf8import random# 从n个数中采样k个数def reservoir_sampling(n, k):# 所有数据pool = [i for i in range(n)]# 前k个数据res = [i for i in range(k)]for i in range(k, n):v = random.randint(0, i)if v < k:res[v] =
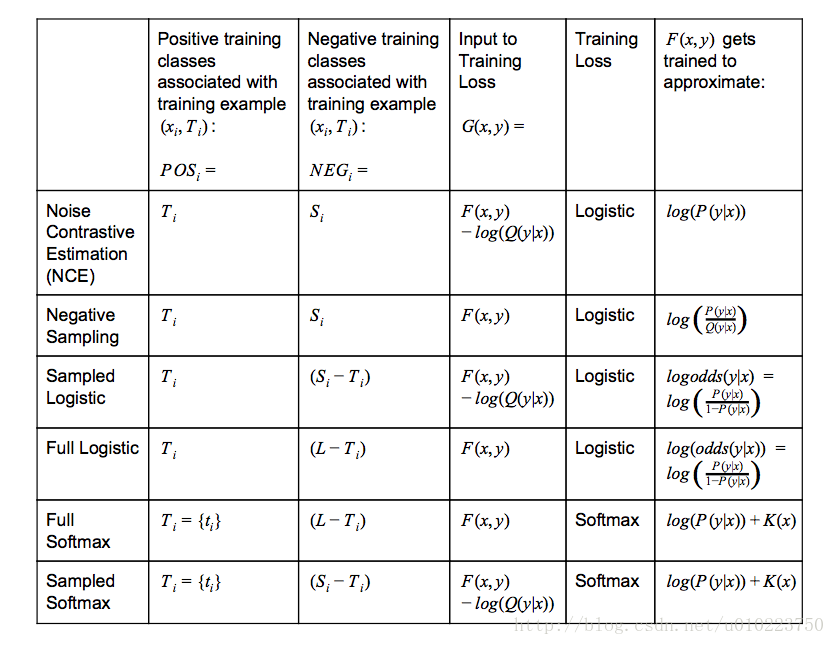
Tensorflow的采样方法:candidate sampling
采样介绍 假如我们有一个多分类任务或者多标签分类任务,给定训练集 (xi,Ti) (x_i,T_i),其中 xi x_i表示上下文, Ti T_i表示目标类别(可能有多个).可以用word2vec中的negtive sampling方法来举例,使用cbow方法,也就是使用上下文 xi x_i来预测中心词(单个target Ti T_i),或者使用skip-gram方法,也就是使用中心词 xi x
![[机器学习与深度学习] - No.1 基于Negative Sampling SKip-Gram Word2vec模型学习总结](https://img-blog.csdnimg.cn/img_convert/8c61d4a1a0606904cba380eaafffa1d7.png)
[机器学习与深度学习] - No.1 基于Negative Sampling SKip-Gram Word2vec模型学习总结
基于Negative Sampling SKip-Gram Word2vec模型学习总结 1. Word2vec简介 Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息。Word2vec的结果是为了获得Word Embeddin
UNDERSTANDING NEGATIVE SAMPLING IN KNOWLEDGE GRAPH EMBEDDING
伯努利采样的改进。Zhang等[45]扩展伯努利抽样,考虑关系替换遵循概率α=r / ((r+e)),这里r为关系个数,e为实体个数。剩余的1-α按伯努利分布分为头部实体替换和尾部实体替换。这种变化增强了KGE模型的关联环节预测能力。 4.1.3. Probabilistic Sampling Kanojia等人[46]提出了概率负抽样来解决知识库中普遍存在的数据偏斜问题。对于数据较少的关系,

Better Sampling
A couple of days ago, I compared the images my ambient occlusion integrator produced with those of Modo using similar settings. I noticed immediately how much ‘cleaner’ the render from Modo was. Clea

Collapsed Gibbs Sampling for Latent Dirichlet Allocation on Spark
摘要 本文针对Spark上广泛使用的潜在Dirichlet分配(LDA)模型,实现了一种折叠Gibbs抽样方法。 Spark是一款面向大规模数据处理的快速内存集群计算框架,成为大数据小镇的领域话题已经有一段时间了。 适用于迭代和交互算法。 该方法将数据集分割成P∗P个分区,使用规则将这些分区洗牌并重组成P个子数据集,避免采样冲突,其中每个P个子数据集只包含P个分区,然后逐个并行处理每个子数
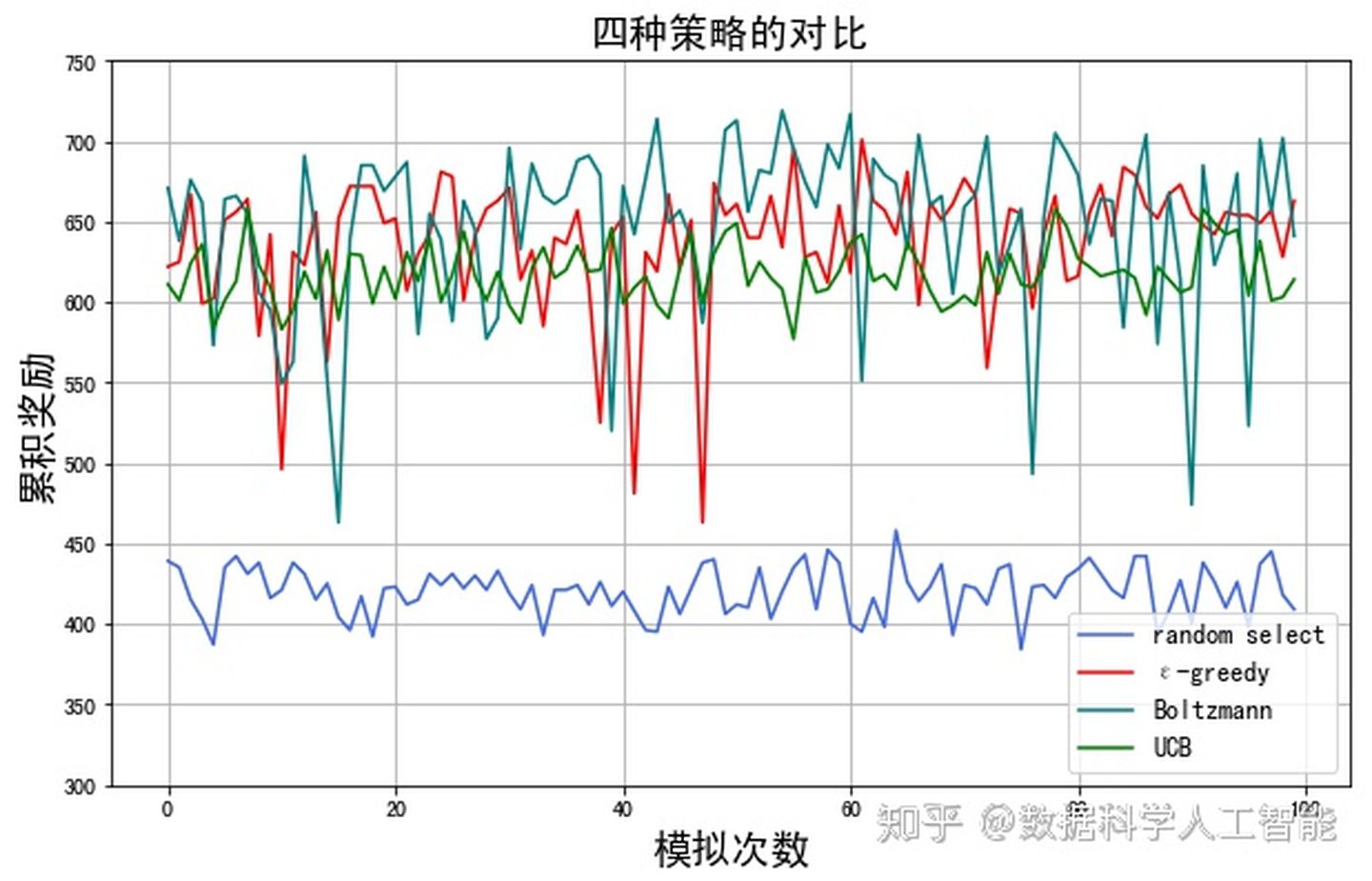
从Thompson Sampling到增强学习, 再谈多臂老虎机问题
老虎机是赌场里最常见的一个设备,一家赌场里有那么多机器,每次摇动都可能后悔或者获得一定额度的奖励,你通过选择不同的老虎机臂最大化自己的利益。这个问题看似非常简单,让很多人都忘了他其实是一个reinforcement learning的问题。 问题描述 (Bernoulli Bandit)假设我们有一个K臂老虎机,每一个臂(action)的回报率(reward_i)都是固定的,但是agent
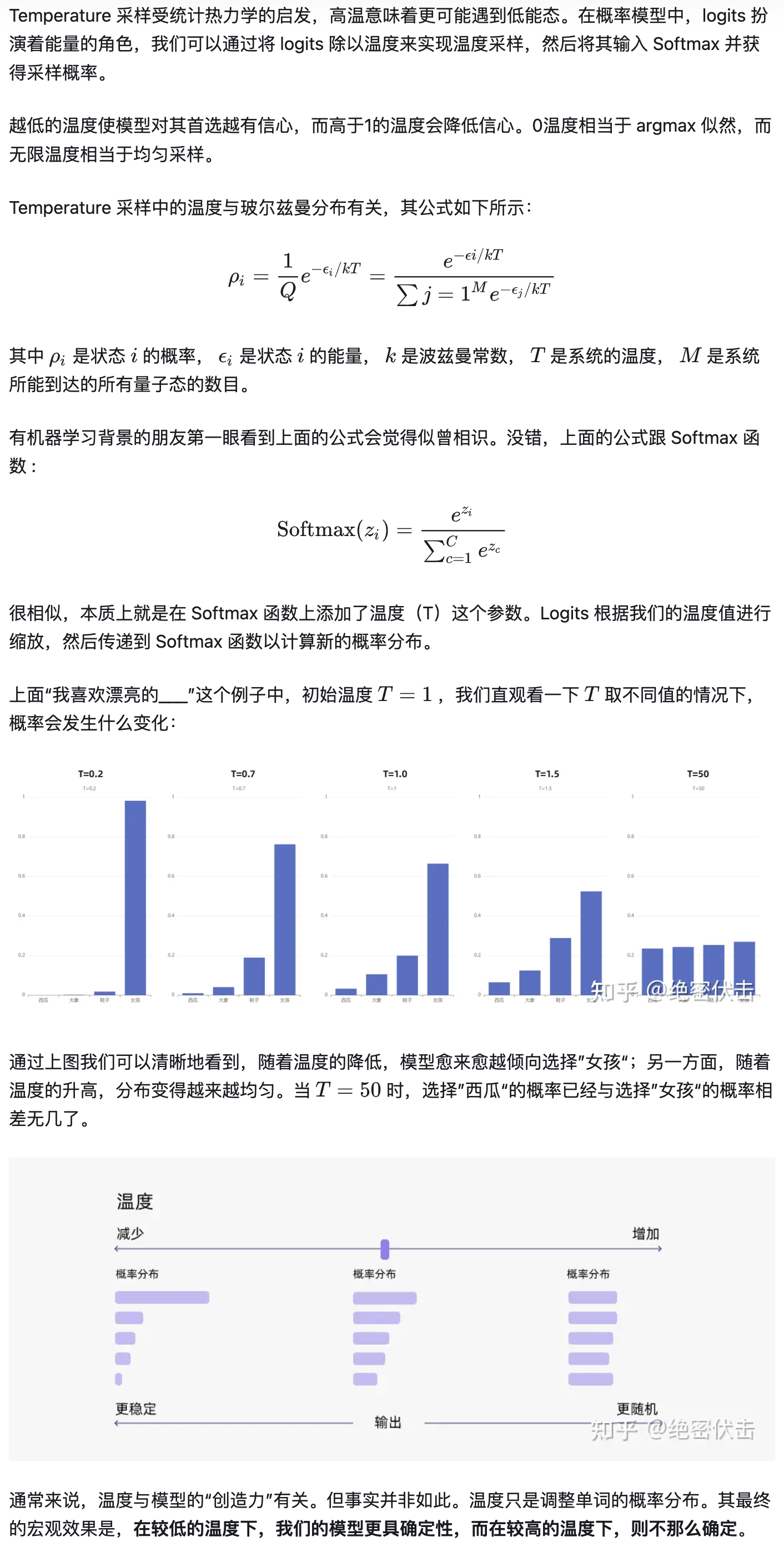
beam search、top-k sampling、nucleus sampling、temperature sampling和联合采样
这几种解码策略在hugging face的GenerationMixin(transformers/generation/utils.py)中均有所实现,在hugging face上的生成式模型都要继承GenerationMixin,以beamsearch为例,下面self就是继承的子类提供的根据w_{0..i-1}给w_{i}打分的language model,这个language model里

Fast Poisson Disk Sampling in Arbitrary Dimensions
转自:https://www.jasondavies.com/poisson-disc/ http://www.cs.ubc.ca/~rbridson/docs/bridson-siggraph07-poissondisk.pdf Robert Bridson University of British Columbia Abstract In many applications in g

correlated double sampling (CDS)相关双采样
目录 原理内部电路和时序使用时注意事项1.内部电路非匹配2.时序要求精确 学习资料 原理 correlated double sampling (CDS)相关双采样,主要用在图像传感器image sensor CMOS和CCD中。 处理流程如下: 采集复位信号采集真正的信号真正的信号-复位信号=实际信号 背后的数学原理 R+N1(R:固定模式噪音和偏置电压, N1: 采样
Gibbs Sampling简单总结
Gibbs Samping 是MCMC中最常用的方法,基本的原理就是通过随机模拟, 采集 期望数量的 目标分布的样本,这些样本构造了一条马尔可夫链,而由这些样本集,基本可以推断出目标分布的参数以及其它的想了解的 后验分布。但通常 如何采集 样本成为关键,应用它的原因是目标分布的分布函数未知,但是 构成目标分布的 变量的 条件分布是知道的,那么就可以用随机模拟的思想,利用贝叶斯公式的特性,从条件概

tf编译pointnet2-master中sampling层
1 .\tf_ops\sampling\文件夹下 打开tf_sampling_compile.sh 修改几个参数 #/bin/bash/usr/local/cuda/bin/nvcc tf_sampling_g.cu -o tf_sampling_g.cu.o -c -O2 -DGOOGLE_CUDA=1 -x cu -Xcompiler -fPICTF_ROOT=./venv/lib
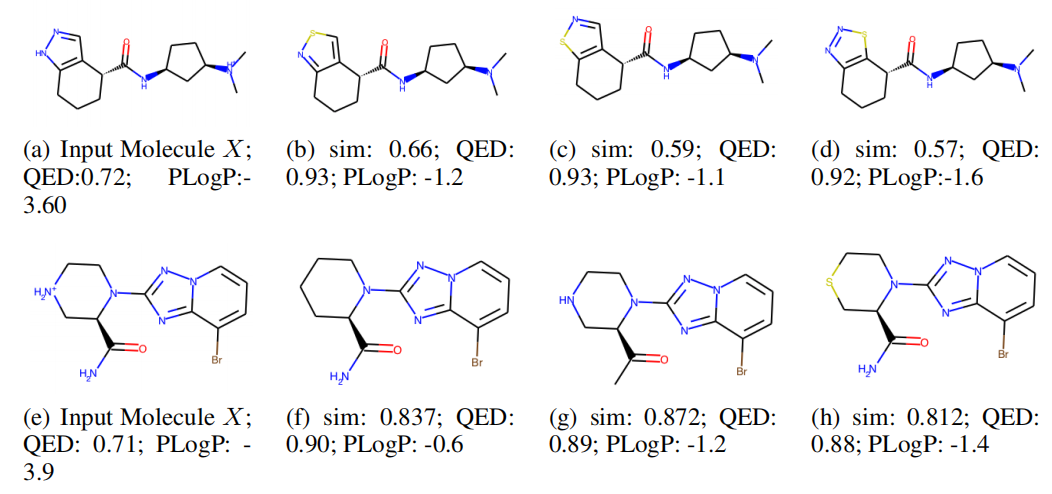
【AAAI 2021】Multi-constraint Molecule Sampling for Molecule Optimization
多限制分子采样分子优化 Multi-constraint Molecule Sampling for Molecule Optimization 摘要 挑战:face difficulties in simultaneously optimizing multiple drug properties. 方法:To address such challenges, we propose

Molecular Simulation:Chain-Molecule Sampling Techniques
转载于:https://www.cnblogs.com/Simulation-Campus/p/8794374.html

word2vec详解(CBOW、SG、hierarchical softmax、negative sampling)
word2vec用来干什么的解释,参见这篇博客一开始也是纯照论文《word2vec Parameter Learning Explained》推公式,到后来理解深了一点,所以后面和前面的公式间有点乱。 python代码:理解不深刻。链接 import argparseimport mathimport structimport sysimport timeimp

对新序列采样(Sampling novel sequences)
来源:Coursera吴恩达深度学习课程 当训练完一个序列模型之后,我们要想了解到这个模型学到了什么,一种非正式的方法就是进行一次新序列采样(have a sample novel sequences),来看看到底应该怎么做。 注意序列模型模拟了任意特定单词序列的概率,我们需要对这些概率分布进行采样(sample)来生成一个新的单词序列。如上图所示: ①第一步:对你想要模型生成的一个词进
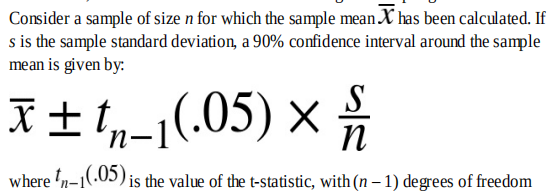
《Practical Statistics for Data Scientists》Chapter 2:Data and Sampling distributions
本章主要总结几个概念性的东西: target shuffle:discern between signal and noiseconfidence intervals | the level of confidenceQQ-plots:利用该图判定数据是否服从正态分布long-tailed distributiont-distributionbinomial distributionpossio
【医学+深度论文:F33】2017Glaucoma detection using entropy sampling and ensemble learning for automatic optic
33 2017 Computerized Medical Imaging and Graphics Glaucoma detection using entropy sampling and ensemble learning for automatic optic cup and disc segmentation Method : 分割 Dataset: DRISHTI-GS Arch

马尔科夫链MCMC采样算法和LDA Gibbs Sampling
本文转载统计之都上的一篇关于lda gibbs采样算法的介绍 http://cos.name/2013/01/lda-math-mcmc-and-gibbs-sampling/ 马氏链及其平稳分布 马氏链的数学定义很简单 P(Xt+1=x|Xt,Xt−1,⋯)=P(Xt+1=x|Xt) 也就是状态转移的概率只依赖于前一个状态。 我们先来看马氏链的一个具体的

数字图像处理笔记——频域滤波、采样和频谱混叠( Frequency domain filtering; sampling and aliasing)
频域滤波 频域滤波就是将信号先做傅里叶变换再与滤波器频域响应相乘,最后再做傅里叶反变换得到 低通滤波器 让我们先来看看理想低通滤波器,理想低通滤波器的频率响应是一个中间是1,周围是0的正方形或圆形,而在时域上是sinc函数,,我们看经过低通滤波器后的图像变得模糊了,但是会发现图中多了很多波纹,原因就是理想低通滤波器在时域上的图像并不是理想的,而是有旁瓣。我们知道频域缩窄对于时域展宽,因此
![[论文翻译][2015][28]Bayesian Estimation of the DINA Model With Gibbs Sampling(基于Gibbs采样的DINA模型贝叶斯参数估计方法)](https://img-blog.csdnimg.cn/20200702164752399.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L21hZXJkeW0=,size_16,color_FFFFFF,t_70#pic_center)
[论文翻译][2015][28]Bayesian Estimation of the DINA Model With Gibbs Sampling(基于Gibbs采样的DINA模型贝叶斯参数估计方法)
Bayesian Estimation of the DINA Model With Gibbs Sampling 下载论文摘要引言DINA模型贝叶斯参数估计优势基于贝叶斯的DINA模型参数估计方法贝叶斯模型表达式全条件分布 蒙特卡洛仿真研究应用:空时可视化测试讨论参考文献 下载论文 摘要 基于已经提出的DINA模型的贝叶斯表达公式,可以使用Gibbs采样通过联合后延分布来拟合
累计概率分布、概率分布函数(概率质量函数、概率密度函数)、度量空间、负采样(Negative Sampling)
这里写自定义目录标题 机器学习的基础知识累计概率分布概率分布函数度量空间负采样(Negative Sampling)基于分布的负采样(Distribution-based Negative Sampling):基于近邻的负采样(Neighbor-based Negative Sampling): 机器学习的基础知识 累计概率分布、概率分布函数(概率质量函数、概率密度函数)、度
![27[NLP训练营]collapsed gibbs sampling](https://img-blog.csdnimg.cn/20200405195431228.png)
27[NLP训练营]collapsed gibbs sampling
文章目录 回顾第一步第二步 看分子第一项第二项联合第一、第二项 第二步 看分母分子分母同时看化简小栗子 小结 公式输入请参考: 在线Latex公式 回顾 下图是LDA生成的过程。 为了更好描述collapsed gibbs sampling。把里面的标识换一下,问题的描述变成: 计算 P ( Z t s ∣ Z − t s , w , α , β ) P(Z_{ts}|Z