本文主要是介绍[机器学习与深度学习] - No.1 基于Negative Sampling SKip-Gram Word2vec模型学习总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于Negative Sampling SKip-Gram Word2vec模型学习总结
1. Word2vec简介
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息。Word2vec的结果是为了获得Word Embedding,我们又称为词嵌入。Word Embedding就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。
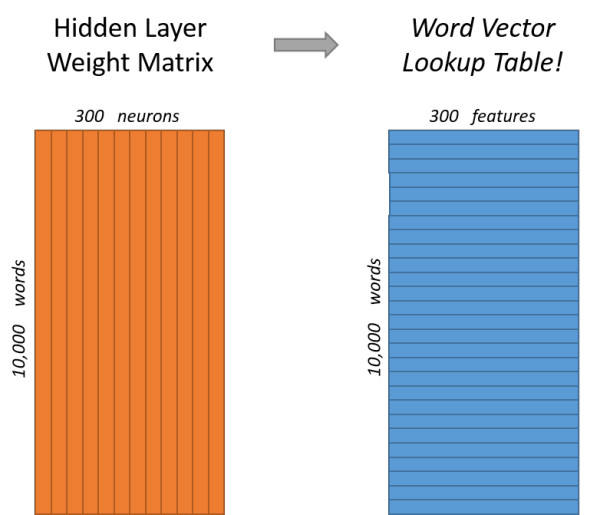
如果之前了解过RNN 语言模型,会了解到,如果我们的词典中一共有10000个不同的词,那么我们每个词将会使用10000维的***one-hot***编码来表示。如果我们希望使用300维的特征向量代表每个词,我们设置模型的隐藏层节点为300维。输入层-隐藏层的权重矩阵为:10000X300维。那么权重矩阵的每一行即代表我们最后所需的word embedding
Word2vec模型结构:
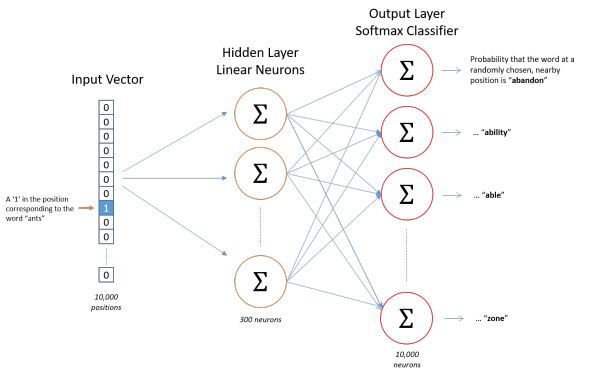
输入层-隐藏层权重矩阵:
2. Skip-Gram
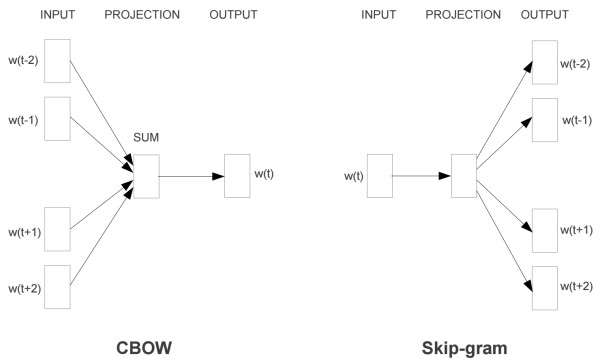
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,。Skip-Gram是给定中心词来预测上下文,CBOW是给定上下文,来预测中心词
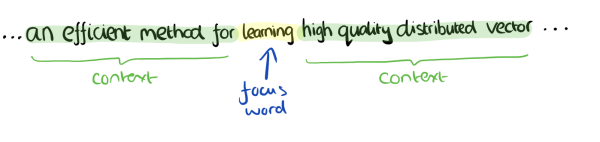
如上图所示,蓝色是我们给定的中心词,上下两边绿色的字体表示我们中心词的上下文
1. 输入形式
Word2vec的输入形式为one-hot编码。假设从我们的训练文档中抽取出10000个唯一不重复的单词组成词汇表。我们对这10000个单词进行one-hot编码,得到的每个单词都是一个10000维的向量,向量每个维度的值只有0或者1,假如单词ants在词汇表中的出现位置为第3个,那么ants的向量就是一个第三维度取值为1,其他维都为0的10000维的向量(ants=[0, 0, 1, 0, …, 0])。
模型的输入如果为一个10000维的向量,那么输出也是一个10000维度(词汇表的大小)的向量,它包含了10000个概率,每一个概率代表着当前词是输入样本中output word的概率大小。
2. 样本形式
假设我们有一句话“The quick brown fox jumps over the lazy dog.”
- 我们假设中间词为
fox - 接下来,我们设置中心词
fox的上下文范围。我们使用skip_window来表示我们从中心词的左右两侧选取的词的数量,num_skips表示我们在中心词的上下文中选取作为输出词的数量。例如:当skip_window=2,num_skips = 2,中心词为fox时 ,我们获得fox的上下文窗口为['quick','brown','jumps','over']。我们随机从窗口中选取两个词作为输出,那么我们的样本元组应该如同:('fox','brown'),('fox','over')

如上图,列出了中心词所有的训练样本。在代码的实现过程中,我们会使用随机数来随机选取窗口中的输出词。
3. Negative Sampling
训练一个神经网络意味着要输入训练样本并且不断调整神经元的权重,从而不断提高对目标的准确预测。每当神经网络经过一个训练样本的训练,它的权重就会进行一次调整。语料词典的大小决定了我们的Skip-Gram神经网络将会拥有大规模的权重矩阵,所有的这些权重需要通过我们数以亿计的训练样本来进行调整,这是非常消耗计算资源的,并且实际中训练起来会非常慢。
1. 负采样简介
**负采样(negative sampling)**解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
假如我们训练样本('fox','brown'),由于我们使用的是one-hot编码来表示词,我们期望对应“brown”单词的那个输出神经元输出1,其他剩余的所有输出神经元输出0,我们称所有输出为1的输出神经元对应的词为"positive"词,所有输出为0的神经元对应的词为"negative"词
使用负采样的方法,我们不对所有输出神经元对应的权值进行更新,只是随机选取几个"negative"词,更新他们对应的权重。当然,我们也会更新"positive"的对应权值。
如上面所述,加入我们有10000个单词,每个单词用300维表示,那么我们的权重矩阵为***10000x300***维的矩阵。我们每次更新需要更新3000000个值。如果我们只更新随机选取的5个"negative"单词和一个"positive"的权重,那么我们只需要更新1800个值,相当于之前0.06%的计算量。
2. 负采样点选取
本质上来说,一个单词备选做为"negative word"的概率和他出现的频率有关,出现频次越高的单词越容易备选做"negative word"。这就是我们对采样过程的一个大致要求,本质上是一个带权采样的问题。
我们使用一个比较通俗的描述来解释一下带权采样:
设词典D中的每个词 ω \omega ω 对应一个线段 l ( ω ) l(\omega) l(ω) ,长度为:
l e n ( ω ) = c o u n t e r ( ω ) ∑ u ∈ D c o u n t e r ( u ) len(\omega) = \frac{counter(\omega)}{\sum_{u\in D} counter(u)} len(ω)=∑u∈Dcounter(u)counter(ω)
这里的counter()表示一个词在语料中出现的次数。现在将这些线段首位连接在一起,形成一个长度为1的单位线段,如果在线段上随机的打点,那么长度长(频率大)的线段被打中的概率就大
所以,根据 { l e n ( ) j } j = 0 N \{len()_j\}_{j=0}^N {len()j}j=0N 可以得到区间[0,1]上的一个非等距剖分,共有N个剖分区间
接着,我们引入区间[0,1]上的一个等距离剖分,剖分解点为 { m j } j = 0 M \{m_j\}^M_{j=0} {mj}j=0M ,其中M >> N, 如下图所示
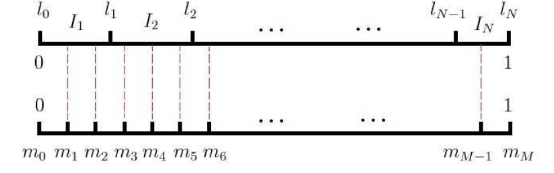
如上图所示,采样就简单了。我们生成一个[1,M-1]之间的随机整数r,然后查看该整数r落在了哪个词对应的线段内,那么该单词就是采样点。如果碰巧遇到了’'positive word",那么就跳过重新选取。
在word2vec的C语言实现中,使用了下面的公式来计算单词被选做负样本的概率。每个单词被选为“negative words”的概率计算公式与其出现的频次有关。
P ( ω j ) = f ( ω j ) 3 4 ∑ j = 0 n ( f ( ω j ) 3 4 ) P(\omega_j) = \frac{{f(\omega_j)}^{\frac{3}{4}}}{\sum^n_{j=0} {(f(\omega_j)^{\frac{3}{4}})}} P(ωj)=∑j=0n(f(ωj)43)f(ωj)43
其中 f ( ω j ) f(\omega_j) f(ωj) 代表词 ω j {\omega_j} ωj 的在整个语料中出现的频次
####4. 参考文章:
http://blog.csdn.net/itplus/article/details/37998797
https://www.leiphone.com/news/201706/eV8j3Nu8SMqGBnQB.html
http://www.thushv.com/natural_language_processing/word2vec-part-1-nlp-with-deep-learning-with-tensorflow-skip-gram/
http://mccormickml.com/2017/01/11/word2vec-tutorial-part-2-negative-sampling/
这篇关于[机器学习与深度学习] - No.1 基于Negative Sampling SKip-Gram Word2vec模型学习总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




