skip专题

python+selenium2学习笔记unittest-04装饰器skip用法
在运行测试用例时,有时需跳过或判断用例时,可以用装饰器来实现 主要的几个方法就是下面的这几种 import unittestclass test(unittest.TestCase):def setUp(self):pass@unittest.skip('跳过')def test_01(self):print("直接跳过")@unittest.skipIf(3>2,'当条件为TRUE跳过')

word2vec 两个模型,两个加速方法 负采样加速Skip-gram模型 层序Softmax加速CBOW模型 item2vec 双塔模型 (DSSM双塔模型)
推荐领域(DSSM双塔模型): https://www.cnblogs.com/wilson0068/p/12881258.html word2vec word2vec笔记和实现 理解 Word2Vec 之 Skip-Gram 模型 上面这两个链接能让你彻底明白word2vec,不要搞什么公式,看完也是不知所云,也没说到本质. 目前用的比较多的都是Skip-gram模型 Go
每天一个数据分析题(五百一十七)- Skip-Gram模型
Skip-Gram模型的基础形式非常简单,为了更清楚地解释模型,我们先从最一般的基础模型来看Word2Vec。Skip-Gram模型不包含以下哪一项? A. 输入层 B. 池化层 C. 输出层 D. 隐藏层 数据分析认证考试介绍:点击进入 题目来源于CDA模拟题库 点击此处获取答案 数据分析专项练习题库 内容涵盖Python,SQL,统计学,数据分析理论,深度学习,可视化,机器学

Word2Vec之Skip-Gram与CBOW模型
Word2Vec之Skip-Gram与CBOW模型 word2vec是一个开源的nlp工具,它可以将所有的词向量化。至于什么是词向量,最开始是我们熟悉的one-hot编码,但是这种表示方法孤立了每个词,不能表示词之间的关系,当然也有维度过大的原因。后面发展出一种方法,术语是词嵌入。 [1.词嵌入] 词嵌入(Word Embedding)是NL

【mongoDB实战】limit,skip,sort
在mongo中最常用的查询选项就是限制返回结果的数量,忽略一定数量的结果并排序.所有这些选项一定要在查询被派发到服务器之前添加.在这里需要用到的就是limit,skip,sort这三个函数了.这三个函数都可以达到限制返回结果数量的目的,但是他们之间还有区别. 1.limit 要限制结果数量,可以在find后使用limit函数.这个函数类似分页的每页多少条数据,例如,如果每页是2
异常处理——skip
在一个step中,不管reader还是process,还是write,出现了指定的错误都可以跳过,继续执行后面的数据。 @Beanpublic Step chunkStep(){return stepBuilderFactory.get("chunkStep1").chunk(3) .reader(fil
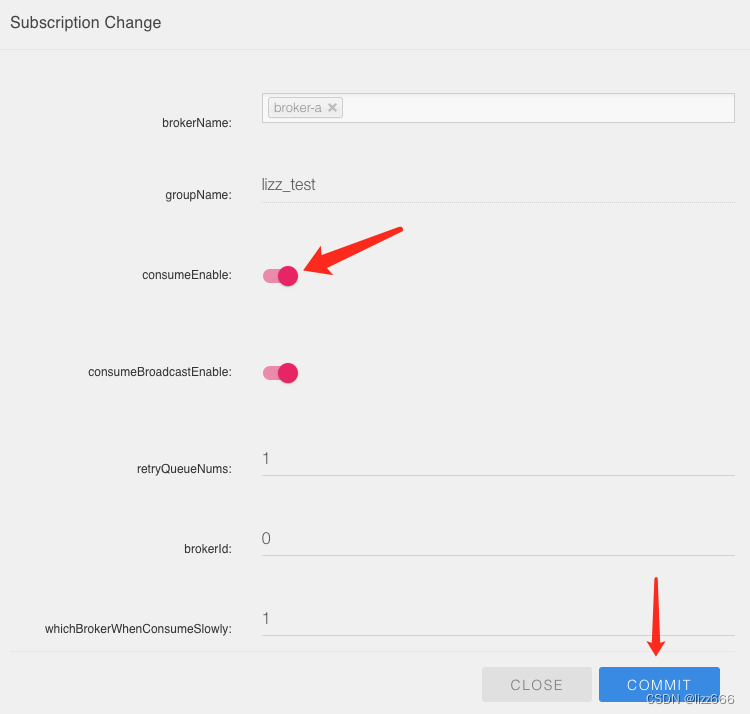
RocketMQ:新增consumer消费组group从最新消息开始消费skip last offset message
场景 想创建一个新的consumer去消费一个已经再使用的topic时,默认情况下会从topic中的第一条消息开始消费,大多数情况是需要从最新的消息开始。然后再使用CONSUME_FROM_LAST_OFFSET设置时并不会对新的consumer生效,它只是在停用consumer重新启用时,如果之前订阅OFFSET消息已经不存在了(默认rocketmq中存放的消息是72小时)就会
文本处理——Word2Vec之 Skip-Gram 模型(三)
博文地址: https://zhuanlan.zhihu.com/p/27234078 原文英文文档请参考链接:- Word2Vec Tutorial - The Skip-Gram Model - Word2Vec (Part 1): NLP With Deep Learning with Tensorflow (Skip-gram) 什么是Word2Vec和Embeddings?

How to skip “Loose Object” popup when running ‘git gui‘
随时随地技术实战干货,获取项目源码、学习资料,请关注源代码社区公众号(ydmsq666) 转自:https://stackoverflow.com/questions/1106529/how-to-skip-loose-object-popup-when-running-git-gui 123down voteaccepted Since nobody had yet an answe
unittest详解(二) 跳过用例的执行(skip)
在执行测试用例时,有时候有些用例是不需要执行的,那我们怎么办呢?难道删除这些用例?那下次执行时如果又需要执行这些用例时,又把它补回来?这样操作就太麻烦了。 unittest提供了一些跳过指定用例的方法@unittest.skip(reason):强制跳转。reason是跳转原因@unittest.skipIf(condition, reason):condition为True的时候跳转@unit

Just Skip The Problem
Y_UME has just found a number xx in his right pocket. The number is a non-negative integer ranging from 00 to 2n−12n−1 inclusively. You want to know the exact value of this number. Y_UME has super pow
![[机器学习与深度学习] - No.1 基于Negative Sampling SKip-Gram Word2vec模型学习总结](https://img-blog.csdnimg.cn/img_convert/8c61d4a1a0606904cba380eaafffa1d7.png)
[机器学习与深度学习] - No.1 基于Negative Sampling SKip-Gram Word2vec模型学习总结
基于Negative Sampling SKip-Gram Word2vec模型学习总结 1. Word2vec简介 Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息。Word2vec的结果是为了获得Word Embeddin

skip-name-resolve
远程连接MySQL数据库时如果需要等待很长时间,可以在my.ini中加入skip-name-resolve参数,禁止反向域名解析。同时在设置用户的主机是,不能使用localhost之类,必须使用IP地址,如果使用了IP地址仍无法连接,使用ping localhost查看是否转换为了IPv6,如果转为了IPv6,在设置数据库用户的时候,主机应该是::1。

跳表 (Skip List) C++ 实现
跳表 (Skip List) C++ 实现 跳表原理 跳表 c++ 实现 SkipNode SkipList 随机层数 结点最大层数 基本操作 打印 主函数 输出结果 在学习 C++ 中的过程中,找个算法作为练习。 仅供参考。 跳表原理 跳表原理讲解请参考 https://lotabout.me/2018/skip-list/ 为了节约时间,这里只是简单说明,原文如上。 跳表(skip
python-pytorch实现skip-gram 0.5.001
python-pytorch实现skip-gram 0.5.000 数据加载、切词准备训练数据准备模型和参数训练保存模型加载模型简单预测获取词向量画一个词向量的分布图使用词向量计算相似度参考 数据加载、切词 按照链接https://blog.csdn.net/m0_60688978/article/details/137538274操作后,可以获得的数据如下 wordList
python-pytorch实现skip-gram 0.5.000【直接可运行】
python-pytorch实现skip-gram 0.5.000【直接可运行】 参考导入包加载数据和切词获取wordList、raw_text获取vocab、vocab_sizeword_to_idx、idx_to_word准备训练数据准备模型和参数训练模型保存模型简单预测获取训练后的词向量画图看下分布利用词向量计算相似度余弦点积 参考 https://blog.csdn.

MongoDB的skip,limit,sort执行顺序
先sort再skip,最后limit 所有数据都是不一样的。 先看 skip和limit, 当两者一起使用的时候, 不管其位置顺序,默认先skip,再limit。 如下图: 再看sort ,【6】语句,我的数据已经排序。之后三条数据无论怎么变换都是一样的排序结果。(这里未列出所有可能。将skip和limit位置变化后跟sort组合,但是结果仍然相同) 由结果可以得出,当sort
TagSupport.SKIP_BODY,SKIP_PAGE,EVAL_BODY_INCLUDE,EVAL_BODY_AGAIN
SKIP_BODY,SKIP_PAGE,EVAL_BODY_INCLUDE,EVAL_BODY_AGAIN返回值的各个含义 SKIP_BODY 隐含0:跳过了开始和结束标签之间的代码。 EVAL_BODY_INCLUDE隐含1:将body的内容输出到存在的输出流中 SKIP_PAGE 隐含5:忽略剩下的页面。 E
Skip Index 学习
列存中的 skip index 是什么概念 列存数据库(Columnar database)中的 skip index 是一种优化查询性能的索引方法。在列存数据库中,数据是按列而不是按行存储的,这使得针对特定列的查询可以非常迅速。然而,即使是在列存数据库中,如果查询的数据量很大,那么性能也可能受到影响。这时,skip index 就能发挥作用。 Skip index 通常用在列存数据库中
Word2vec之skip-gram训练词向量
参考自哈工大车万翔等老师编写的《自然语言处理-基于预训练模型的方法》 # coding: utf-8# Name: tesst2# Author: dell# Data: 2021/10/12# 基于负采样的skip-garm模型import torchimport torch.nn.functional as Fimport torch.nn as nn
RxJava2 / RxAndroid2操作符skip
顾名思义,skip跳过,例如: package zhangphil.app;import android.os.Bundle;import android.support.annotation.Nullable;import android.support.v7.app.AppCompatActivity;import android.util.Log;import io.reactive

idea中执行mvn命令报错Unknown lifecycle phase “.test.skip=true“
idea中执行maven命令总是报错,解决办法: 1.先检查一下maven的配置问题 2.把终端改成cmd

读懂Word2Vec之Skip-Gram
本教程将介绍Word2Vec的skip gram神经网络体系结构。我这篇文章的目的是跳过对Word2Vec的一般的介绍和抽象见解,并深入了解其细节。具体来说,我正在深入skipgram神经网络模型。 模型介绍 skip-gram神经网络模型其最基本的形式实际上是惊人的简单; Word2Vec使用了一个你可能在机器学习中看到过的技巧。我们将训练一个带有单个隐藏层的简单的神经网络来完成某个任务,但是

2.java8流的使用 stream的筛选与切片filter,limit,skip,distinct
1.代码 准备的bean类 /*** 创建日期:2021/10/29 14:01** @author tony.sun* 类说明:*/public class Employee {private String name;private int age;private double salary;public Employee(String name, int age, double salar

使用xShell部署项目,通过执行maven命令,将项目打成war包: mvn clean package -Dmaven.test.skip=true,有问题,打不成war包,报下面错误
使用xShell部署项目,通过执行maven命令,将项目打成war包: mvn clean package -Dmaven.test.skip=true,有问题,打不成war包,报下面错误 原因:要把maven的setting中的镜像,本地的或者私服,换成阿里云的才可以
ERROR: Failed to set up Chromium r901912! Set “PUPPETEER_SKIP_DOWNLOAD“ env variable to skip downloa
报错原因 npm install puppeteer的时候报下面这个提示 ERROR: Failed to set up Chromium r901912! Set "PUPPETEER_SKIP_DOWNLOAD" env variable to skip download.{ Error: read ETIMEDOUTat TLSWrap.onStreamRead (internal/s