本文主要是介绍beam search、top-k sampling、nucleus sampling、temperature sampling和联合采样,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这几种解码策略在hugging face的GenerationMixin(transformers/generation/utils.py)中均有所实现,在hugging face上的生成式模型都要继承GenerationMixin,以beamsearch为例,下面self就是继承的子类提供的根据w_{0..i-1}给w_{i}打分的language model,这个language model里当然要实现例如kv_cache等策略:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)outputs = self(**model_inputs,return_dict=True,output_attentions=output_attentions,output_hidden_states=output_hidden_states,)假设一个搜索任务
假设现在有一个简化版的中文翻译英文任务,输入和输出如下,为了方便描述搜索算法,限制输出词典只有{"I", "H", "U"} 这3个候选词,限制1个时间步长翻译1个汉字,1个汉字对应1个英文单词,这里总共3个汉字,所以只有3个时间步长。
中文输入:"我" "恨" "你"
英文输出:"I" "H" "U"
目标:得到最优的翻译序列 I-H-U
exhaustive search(穷举搜索)
最直观的方法就是穷举所有可能的输出序列,3个时间步长,每个步长3种选择,共计 种排列组合。
I-I-I
I-I-H
I-I-U
I-H-I
I-H-H
I-H-U
I-U-I
I-U-H
I-U-UH-I-I
H-I-H
H-I-U
H-H-I
H-H-H
H-H-U
H-U-I
H-U-H
H-U-UU-I-I
U-I-H
U-I-U
U-H-I
U-H-H
U-H-U
U-U-I
U-U-H
U-U-U从所有的排列组合中找到输出条件概率最大的序列。穷举搜索能保证全局最优,但计算复杂度太高,当输出词典稍微大一点根本无法使用。
greedy search(贪心搜索)
贪心算法在翻译每个字的时候,直接选择条件概率最大的候选值作为当前最优。如下图所以,
- 第1个时间步长:首先翻译"我",发现候选"I"的条件概率最大为0.6,所以第一个步长直接翻译成了"I"。
- 第2个时间步长:翻译"我恨",发现II概率0.2,IH概率0.7,IU概率0.1,所以选择IH作为当前步长最优翻译结果。
- 第3个时间步长:翻译"我恨你",发现IHI概率0.05,IHH概率0.05,IHU概率0.9,所以选择IHU作为最终的翻译结果。
PS:图中的概率如何得来的?不同的模型有不同的算法,我自己随便填的。

greedy search
贪心算法每一步选择中都采取在当前状态下最好或最优的选择,通过这种局部最优策略期望产生全局最优解。但是期望是好的,能不能实现是另外一回事了。贪心算法本质上没有从整体最优上加以考虑,并不能保证最终的结果一定是全局最优的。但是相对穷举搜索,搜索效率大大提升。
beam search(束搜索)
beam search是对greedy search的一个改进算法。相对greedy search扩大了搜索空间,但远远不及穷举搜索指数级的搜索空间,是二者的一个折中方案。
beam search有一个超参数beam size(束宽),设为k。第一个时间步长,选取当前条件概率最大的k个词,当做候选输出序列的第一个词。之后的每个时间步长,基于上个步长的输出序列,挑选出所有组合中条件概率最大的k个,作为该时间步长下的候选输出序列。始终保持k个候选。最后从k个候选中挑出最优的。
还是以上面的任务为例,假设k=2,我们走一遍这个搜索流程。
- 第一个时间步长:如下图所示,I和H的概率是top2,所以第一个时间步长的输出的候选是I和H,将I和H加入到候选输出序列中。

beam search 第一个时间步长
- 第2个时间步长:如下图所示,以I开头有三种候选{II, IH, IU},以H开头有三种候选{HI, HH, HU}。从这6个候选中挑出条件概率最大的2个,即IH和HI,作为候选输出序列。

beam search 第二个时间步长
- 第3个时间步长:同理,以IH开头有三种候选{IHI, IHH, IHU},以HI开头有三种候选{HII, HIH, HIU}。从这6个候选中挑出条件概率最大的2个,即IHH和HIU,作为候选输出序列。因为3个步长就结束了,直接从IHH和IHU中挑选出最优值IHU作为最终的输出序列。

beam search 第三个时间步长
- beam search不保证全局最优,但是比greedy search搜索空间更大,一般结果比greedy search要好。
- greedy search 可以看做是 beam size = 1时的 beam search。
Top-K sampling
简单说beam search的缺点是high quality human language does not follow a distribution of high probability next words,需要一定的随机性,所以有了采样。这就是top-k sampling:在解码的每个时间步从前k个概率最大的词中按它们的概率进行采样。但top-k sampling中k的选择是个难题,选大了可能会采样出长尾词,导致语句不通顺,选小了又退化成了Beam Search。
Nucleus sampling(top-p sampling)
简单说就是把上面top-k sampling里top k个词换成了top p的概率分布,在每个时间步,头部的几个词的出现概率已经占据了绝大部分概率空间,把这部分核心词叫做nucleus,这个名字起得有点唬人,叫Core Sampling可能更直观些 (但不fancy)
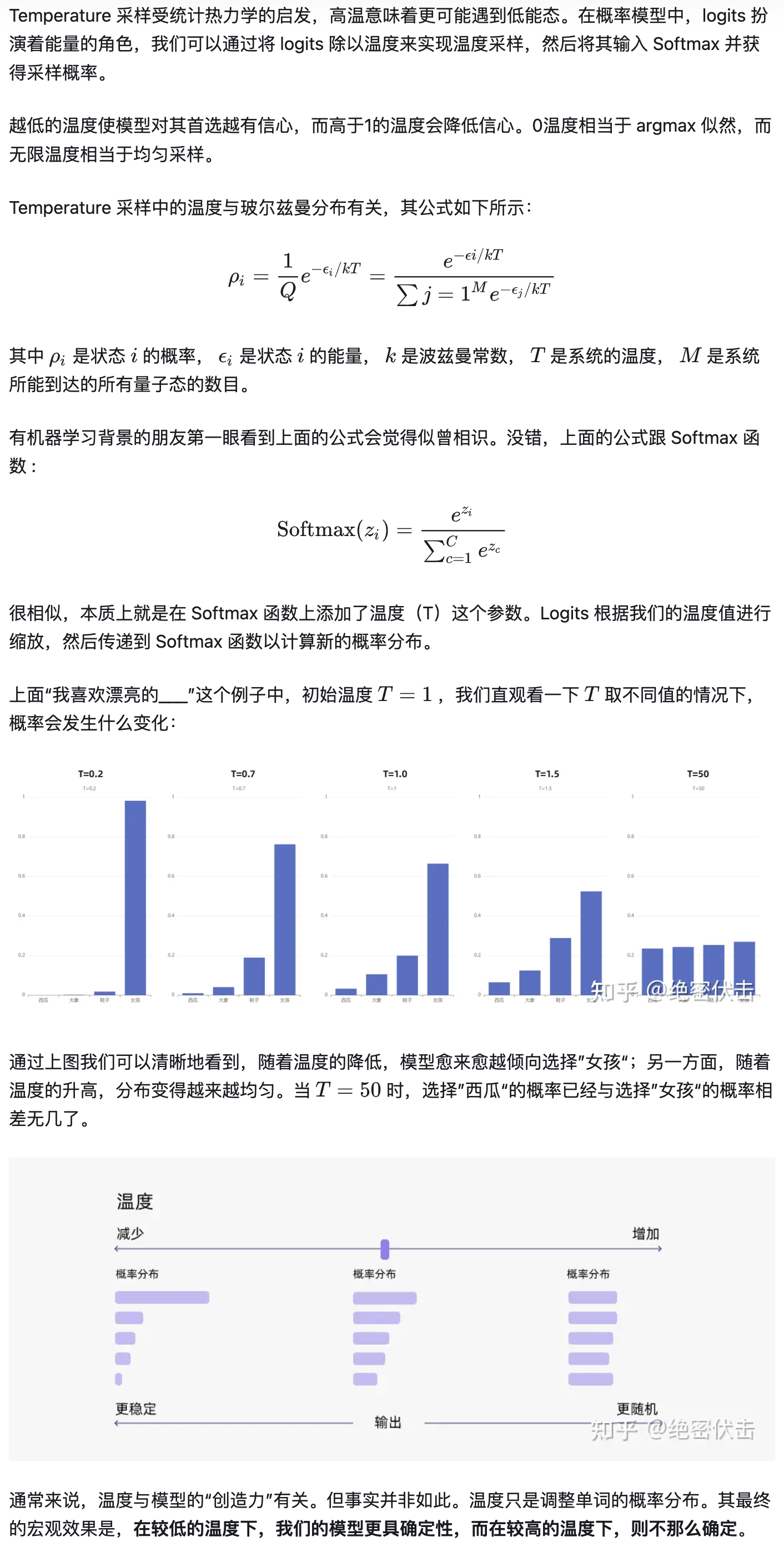
Temperature sampling
本质上就是在 Softmax 函数上添加了温度(T)这个参数,以下截图自 大模型文本生成——解码策略(Top-k & Top-p & Temperature) - 知乎
联合采样(top-k & top-p & Temperature)
通常我们是将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。
我们还是以前面的例子为例。
首先我们设置 top-k = 3,表示保留概率最高的3个 token。这样就会保留女孩、鞋子、大象这3个 token。
- 女孩:0.664
- 鞋子:0.199
- 大象:0.105
接下来,我们可以使用 top-p 的方法,保留概率的累计和达到 0.8 的单词,也就是选取女孩和鞋子这两个 token。接着我们使用 Temperature = 0.7 进行归一化,变成:
- 女孩:0.660
- 鞋子:0.340
接着,我们可以从上述分布中进行随机采样,选取一个单词作为最终的生成结果。
部分转载自:
1. Nucleus Sampling与不同解码策略简介 - 知乎
2. 来自hugging face的博客,比较长但是说的比较细:How to generate text: using different decoding methods for language generation with Transformers3. 大模型文本生成——解码策略(Top-k & Top-p & Temperature) - 知乎
这篇关于beam search、top-k sampling、nucleus sampling、temperature sampling和联合采样的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!