本文主要是介绍27[NLP训练营]collapsed gibbs sampling,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 回顾
- 第一步
- 第二步 看分子
- 第一项
- 第二项
- 联合第一、第二项
- 第二步 看分母
- 分子分母同时看
- 化简
- 小栗子
- 小结
公式输入请参考: 在线Latex公式
回顾
下图是LDA生成的过程。
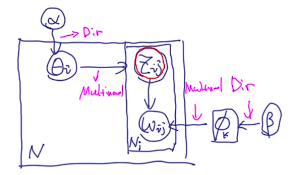
为了更好描述collapsed gibbs sampling。把里面的标识换一下,问题的描述变成:
计算 P ( Z t s ∣ Z − t s , w , α , β ) P(Z_{ts}|Z_{-ts},w,\alpha,\beta) P(Zts∣Z−ts,w,α,β)
t t t代表第 t t t个文档
s s s代表第 t t t个文档的第 s s s个单词
假设有一个集合
x = { x 1 , x 2 , . . . x n } x=\{x_1,x_2,...x_n\} x={x1,x2,...xn}
那么它可以表示为:
x = x i ∪ x − i x=x_i\cup x_{-i} x=xi∪x−i
同样的,问题描述中的 Z = Z t s ∪ Z − t s Z=Z_{ts}\cup Z_{-ts} Z=Zts∪Z−ts
第一步
可以看到,问题描述中是没有 ϕ , θ \phi,\theta ϕ,θ的,我们就是要用collapsed 的方式把这两个变量进行边缘化,
P ( Z t s ∣ Z − t s , w , α , β ) = P ( Z , w ∣ α , β ) P ( Z − t s , w ∣ α , β ) P(Z_{ts}|Z_{-ts},w,\alpha,\beta)=\cfrac{P(Z,w|\alpha,\beta)}{P(Z_{-ts},w|\alpha,\beta)} P(Zts∣Z−ts,w,α,β)=P(Z−ts,w∣α,β)P(Z,w∣α,β)
变成这个形式是有点原因的, w w w是观测到的结果,把它挪到概率的前面部分,就相对于利用观测值来推断参数,可以走likelihood的套路。
上面的式子为什么会相等呢?
P ( Z , w ∣ α , β ) P ( Z − t s , w ∣ α , β ) ∗ P ( α , β ) P ( α , β ) = P ( Z , w , α , β ) P ( Z − t s , w , α , β ) (1) \begin{aligned}&\cfrac{P(Z,w|\alpha,\beta)}{P(Z_{-ts},w|\alpha,\beta)}*\cfrac{P(\alpha,\beta)}{P(\alpha,\beta)}\\ &=\cfrac{P(Z,w,\alpha,\beta)}{P(Z_{-ts},w,\alpha,\beta)}\tag1\end{aligned} P(Z−ts,w∣α,β)P(Z,w∣α,β)∗P(α,β)P(α,β)=P(Z−ts,w,α,β)P(Z,w,α,β)(1)
P ( Z t s ∣ Z − t s , w , α , β ) × P ( Z − t s , w , α , β ) = P ( Z t s , Z − t s , w , α , β ) = P ( Z , w , α , β ) (2) \begin{aligned}&P(Z_{ts}|Z_{-ts},w,\alpha,\beta)\times P(Z_{-ts},w,\alpha,\beta)\\ &=P(Z_{ts},Z_{-ts},w,\alpha,\beta)\\&=P(Z,w,\alpha,\beta)\tag2\end{aligned} P(Zts∣Z−ts,w,α,β)×P(Z−ts,w,α,β)=P(Zts,Z−ts,w,α,β)=P(Z,w,α,β)(2)
把公式2代入1就得到上面的等式了。
第二步 看分子
把第一步中的分子分母分开看,先看分子
P ( Z , w ∣ α , β ) P(Z,w|\alpha,\beta) P(Z,w∣α,β)
如果要把 ϕ , θ \phi,\theta ϕ,θ边缘化就是要写成下面的积分:
P ( Z , w ∣ α , β ) = P ( Z ∣ α ) ⋅ P ( w ∣ Z , β ) = ∫ P ( Z ∣ θ ) ⋅ P ( θ ∣ α ) d θ ∫ P ( w ∣ Z , ϕ ) ⋅ P ( ϕ ∣ β ) d ϕ \begin{aligned}P(Z,w|\alpha,\beta)&=P(Z|\alpha)\cdot P(w|Z,\beta)\\ &=\int P(Z|\theta)\cdot P(\theta|\alpha)d\theta\int P(w|Z,\phi)\cdot P(\phi|\beta)d\phi\end{aligned} P(Z,w∣α,β)=P(Z∣α)⋅P(w∣Z,β)=∫P(Z∣θ)⋅P(θ∣α)dθ∫P(w∣Z,ϕ)⋅P(ϕ∣β)dϕ
上面第一个等号实际上是根据LDA那个图进行拆分了一下,用依赖关系把联合概率拆分成对应的条件概率。上面的联合概率是有条件的,就是已知的超参数 α , β \alpha,\beta α,β

按上面的图本来第一个等号后面应该是写: P ( Z ∣ θ ) ⋅ P ( w ∣ Z , ϕ ) P(Z|\theta)\cdot P(w|Z,\phi) P(Z∣θ)⋅P(w∣Z,ϕ),但是为了要把 θ , ϕ \theta,\phi θ,ϕ进行边缘化,我们就把这个路径直接取到 α , β \alpha,\beta α,β那里了。
所以就写成了: P ( Z ∣ α ) ⋅ P ( w ∣ Z , β ) P(Z|\alpha)\cdot P(w|Z,\beta) P(Z∣α)⋅P(w∣Z,β)
分别看上面的两项积分:
第一项
第一项中 P ( Z ∣ θ ) P(Z|\theta) P(Z∣θ)相当于multinomial分布, P ( θ ∣ α ) P(\theta|\alpha) P(θ∣α)相当于狄利克雷分布,因此根据分布的性质可以展开(上面用ts来代表新下标,这里又回到原来的ij了。。。):
∫ P ( Z ∣ θ ) ⋅ P ( θ ∣ α ) d θ = ∫ ∏ i = 1 N ∏ j = 1 N i ∏ k = 1 K θ i k I ( Z i j = k ) ⋅ ∏ i = 1 N 1 B ( α ) ∏ k = 1 K θ i k α k − 1 d θ k = ∏ i = 1 N ∫ ∏ j = 1 N i ∏ k = 1 K θ i k I ( Z i j = k ) ⋅ 1 B ( α ) ∏ k = 1 K θ i k α k − 1 d θ k \begin{aligned}&\int P(Z|\theta)\cdot P(\theta|\alpha)d\theta\\&=\int\prod_{i=1}^N\prod_{j=1}^{N_i}\prod_{k=1}^K\theta^{I(Z_{ij}=k)}_{ik}\cdot\prod_{i=1}^N\cfrac{1}{\Beta(\alpha)}\prod_{k=1}^K\theta_{ik}^{\alpha_{k}-1}d\theta_k\\ &=\prod_{i=1}^N\int\prod_{j=1}^{N_i}\prod_{k=1}^K\theta^{I(Z_{ij}=k)}_{ik}\cdot\cfrac{1}{\Beta(\alpha)}\prod_{k=1}^K\theta_{ik}^{\alpha_{k}-1}d\theta_k\end{aligned} ∫P(Z∣θ)⋅P(θ∣α)dθ=∫i=1∏Nj=1∏Nik=1∏KθikI(Zij=k)⋅i=1∏NB(α)1k=1∏Kθikαk−1dθk=i=1∏N∫j=1∏Nik=1∏KθikI(Zij=k)⋅B(α)1k=1∏Kθikαk−1dθk
先解释一下第一个等号的第一项: ∏ i = 1 N ∏ j = 1 N i \prod_{i=1}^N\prod_{j=1}^{N_i} ∏i=1N∏j=1Ni表示两层循环,每个文章,每个文章中的单词,第三个虽然是连乘,但是由于indicator函数的存在,每次只会有一个 θ i k \theta_{ik} θik出现。
第二项是把所有文档的主题分布拆分单个文档主题分布的累加,所以第一个 ∏ i = 1 N \prod_{i=1}^N ∏i=1N表示所有文章的狄利克雷分布的累加。
这里把连乘 ∏ j = 1 N i \prod_{j=1}^{N_i} ∏j=1Ni放到指数变成累加 ∑ j = 1 N i \sum_{j=1}^{N_i} ∑j=1Ni,然后和后面的 θ i k α k − 1 \theta_{ik}^{\alpha_{k}-1} θikαk−1的指数进行相加,上式变为:
= ∏ i = 1 N 1 B ( α ) ∫ ∏ k = 1 K θ i k ∑ j = 1 N i I ( Z i j = k ) + α k − 1 d θ k (3) =\prod_{i=1}^N\cfrac{1}{\Beta(\alpha)}\int\prod_{k=1}^K\theta^{\sum_{j=1}^{N_i}I(Z_{ij}=k)+\alpha_{k}-1}_{ik}d\theta_k\tag3 =i=1∏NB(α)1∫k=1∏Kθik∑j=1NiI(Zij=k)+αk−1dθk(3)
根据狄利克雷分布的概念:
D i r ( θ ∣ α ) = 1 B ( α ) ∏ k = 1 K θ i k α k − 1 Dir(\theta|\alpha)=\cfrac{1}{\Beta(\alpha)}\prod_{k=1}^K\theta_{ik}^{\alpha_{k}-1} Dir(θ∣α)=B(α)1k=1∏Kθikαk−1
可以看到公式3积分那个部分其实可以凑成狄利克雷分布,最后变成:
( 3 ) = ∏ i = 1 N B ( α + ∑ j = 1 N i I k ( Z i j ) ) B ( α ) (4) (3)=\prod_{i=1}^N\cfrac{\Beta(\alpha+\sum_{j=1}^{N_i}I_k(Z_{ij}))}{\Beta(\alpha)}\tag4 (3)=i=1∏NB(α)B(α+∑j=1NiIk(Zij))(4)
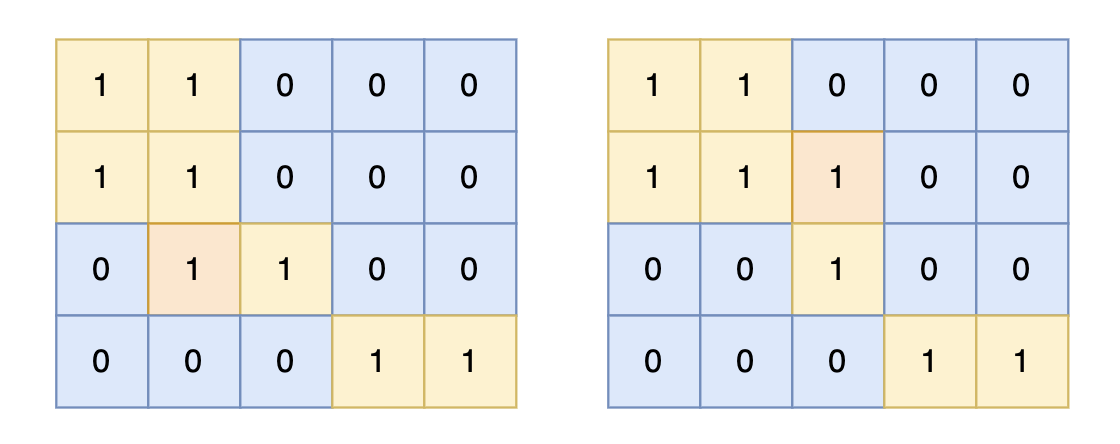
这里给个例子看看 ∑ j = 1 N i I k ( Z i j ) \sum_{j=1}^{N_i}I_k(Z_{ij}) ∑j=1NiIk(Zij)是怎么算(i是文章编号,j是第i篇文章中的单词编号),例如一个文档里面有六个词,每个词对应的主题 Z i j Z_{ij} Zij如下
| w i 1 w_{i1} wi1 | w i 2 w_{i2} wi2 | w i 3 w_{i3} wi3 | w i 4 w_{i4} wi4 | w i 5 w_{i5} wi5 | w i 6 w_{i6} wi6 |
|---|---|---|---|---|---|
| z i 1 z_{i1} zi1 | z i 2 z_{i2} zi2 | z i 3 z_{i3} zi3 | z i 4 z_{i4} zi4 | z i 5 z_{i5} zi5 | z i 6 z_{i6} zi6 |
| 1 | 1 | 2 | 3 | 2 | 2 |
也就是主题为1的有2个词,为2的有3个词,为3的有1个词,因此 ∑ j = 1 N i I k ( Z i j ) = ( 2 , 3 , 1 ) \sum_{j=1}^{N_i}I_k(Z_{ij})=(2,3,1) ∑j=1NiIk(Zij)=(2,3,1)
公式4中 α \alpha α通常是一个向量,可以写作: ( α 1 , α 2 , α 3 , . . . ) (\alpha_1,\alpha_2,\alpha_3,...) (α1,α2,α3,...)
因此, 公式4中的分子就变成了 B ( α 1 + 2 , α 2 + 3 , α 3 + 1 ) \Beta(\alpha_1+2,\alpha_2+3,\alpha_3+1) B(α1+2,α2+3,α3+1),分母变成了 B ( α 1 , α 2 , α 3 ) \Beta(\alpha_1,\alpha_2,\alpha_3) B(α1,α2,α3)
通俗理解就是有一个初始的 α \alpha α,然后根据主题词的个数对 α \alpha α进行调整,这里其实和上面的吉布斯采样中的 θ i \theta_i θi的采样结果一样样的。
第二项
∫ P ( w ∣ Z , ϕ ) ⋅ P ( ϕ ∣ β ) d ϕ \int P(w|Z,\phi)\cdot P(\phi|\beta)d\phi ∫P(w∣Z,ϕ)⋅P(ϕ∣β)dϕ
跟第一项类似的,是一个multinomial和dirichlet分布相乘,经过上面的证明我们知道这两个东西相乘结果还是一个dirichlet分布。上式:
= ∫ ∏ k = 1 K ∏ i : Z i = k ∏ v = 1 V ϕ k , v I ( w i = v ) ⋅ ∏ k = 1 K 1 B ( β ) ∏ v = 1 V ϕ k , v β v − 1 d ϕ k =\int\prod_{k=1}^K\prod_{i:Z_i=k}\prod_{v=1}^V\phi_{k,v}^{I(w_i=v)}\cdot\prod_{k=1}^K\cfrac{1}{\Beta(\beta)}\prod_{v=1}^V\phi_{k,v}^{\beta_v-1}d\phi_k =∫k=1∏Ki:Zi=k∏v=1∏Vϕk,vI(wi=v)⋅k=1∏KB(β)1v=1∏Vϕk,vβv−1dϕk
P ( ϕ ∣ β ) P(\phi|\beta) P(ϕ∣β)对应上面的第二项,第二项的第一个连乘 ∏ k = 1 K \prod_{k=1}^K ∏k=1K意思是 P ( ϕ ∣ β ) P(\phi|\beta) P(ϕ∣β)有K个主题,每个主题都是从狄利克雷分布采样得来的。第二个连乘代表这个主题下的单词,由于考虑所有单词的情况,因此其单词数量记为 V V V。
为了和第一项一样的思路,这里要把 P ( w ∣ Z , ϕ ) P(w|Z,\phi) P(w∣Z,ϕ)也要凑出来主题和所有单词的嵌套连乘,那么就从主题的角度来考虑,每个单词必定是属于某个主题的,因此先循环所有主题: ∏ k = 1 K \prod_{k=1}^K ∏k=1K
这里的 i : Z i = k i:Z_i=k i:Zi=k意思是所有的单词i是属于主题k的(相当于,从所有单词里面把满足 Z i = k Z_i=k Zi=k这个条件的单词i,取出来),另外也可以把连乘变成指数上的累加:
= ∏ k = 1 K 1 B ( β ) ∫ ∏ v = 1 V ϕ k , v ∑ i : Z i = k I ( w i = v ) + β v − 1 d ϕ k = ∏ k = 1 K B ( β + ∑ i : Z i = k I v ( w i ) ) B ( β ) \begin{aligned}&=\prod_{k=1}^K\cfrac{1}{\Beta(\beta)}\int\prod_{v=1}^V\phi_{k,v}^{\sum_{i:Z_i=k}I(w_i=v)+\beta_v-1}d\phi_k\\ &=\prod_{k=1}^K\cfrac{\Beta(\beta+\sum_{i:Z_i=k}I_v(w_i))}{\Beta(\beta)}\end{aligned} =k=1∏KB(β)1∫v=1∏Vϕk,v∑i:Zi=kI(wi=v)+βv−1dϕk=k=1∏KB(β)B(β+∑i:Zi=kIv(wi))
联合第一、第二项
P ( Z , w ∣ α , β ) = 第 一 项 ⋅ 第 二 项 = ∏ i = 1 N B ( α + ∑ j = 1 N i I k ( Z i j ) ) B ( α ) ⋅ ∏ k = 1 K B ( β + ∑ i : Z i = k I v ( w i ) ) B ( β ) \begin{aligned}P(Z,w|\alpha,\beta)&=第一项\cdot 第二项\\ &=\prod_{i=1}^N\cfrac{\Beta(\alpha+\sum_{j=1}^{N_i}I_k(Z_{ij}))}{\Beta(\alpha)}\cdot \prod_{k=1}^K\cfrac{\Beta(\beta+\sum_{i:Z_i=k}I_v(w_i))}{\Beta(\beta)}\end{aligned} P(Z,w∣α,β)=第一项⋅第二项=i=1∏NB(α)B(α+∑j=1NiIk(Zij))⋅k=1∏KB(β)B(β+∑i:Zi=kIv(wi))
第二步 看分母
P ( Z − t s , w ∣ α , β ) P(Z_{-ts},w|\alpha,\beta) P(Z−ts,w∣α,β)
也就是不考虑 Z t s Z_{ts} Zts
P ( Z − t s , w ∣ α , β ) = ∏ i = 1 N B ( α + ∑ j = 1 , δ j ≠ ( t , s ) N i I k ( Z i j ) ) B ( α ) ⋅ ∏ k = 1 K B ( β + ∑ i : Z i = k , δ j ≠ ( t , s ) I v ( w i ) ) B ( β ) \begin{aligned}&P(Z_{-ts},w|\alpha,\beta)\\&=\prod_{i=1}^N\cfrac{\Beta(\alpha+\sum_{j=1,\delta_j\neq(t,s)}^{N_i}I_k(Z_{ij}))}{\Beta(\alpha)}\cdot \prod_{k=1}^K\cfrac{\Beta(\beta+\sum_{i:Z_i=k,\delta_j\neq(t,s)}I_v(w_i))}{\Beta(\beta)}\end{aligned} P(Z−ts,w∣α,β)=i=1∏NB(α)B(α+∑j=1,δj=(t,s)NiIk(Zij))⋅k=1∏KB(β)B(β+∑i:Zi=k,δj=(t,s)Iv(wi))
δ j \delta_j δj代表当前单词所在的位置
分子分母同时看
P ( Z t s ∣ Z − t s , w , α , β ) = 分 子 分 母 P(Z_{ts}|Z_{-ts},w,\alpha,\beta)=\cfrac{分子}{分母} P(Zts∣Z−ts,w,α,β)=分母分子
可以看到分子和分母除了第t个文档,其他项是一样的,由于最外面是连乘,所以可以都消掉(这里的下标又把i换成了t,有点乱。。。):
P ( Z t s ∣ Z − t s , w , α , β ) = B ( α + ∑ j = 1 N t I k ( Z t j ) ) B ( α + ∑ j = 1 , j ≠ s N t I k ( Z t j ) ) B ( β + ∑ i : Z i = k I v ( w i ) ) B ( β + ∑ i : Z i = k , δ j ≠ ( t , s ) I v ( w i ) ) P(Z_{ts}|Z_{-ts},w,\alpha,\beta)=\cfrac{\Beta(\alpha+\sum_{j=1}^{N_t}I_k(Z_{tj}))}{\Beta(\alpha+\sum_{j=1,j\neq s}^{N_t}I_k(Z_{tj}))}\cfrac{\Beta(\beta+\sum_{i:Z_i=k}I_v(w_i))}{\Beta(\beta+\sum_{i:Z_i=k,\delta_j\neq(t,s)}I_v(w_i))} P(Zts∣Z−ts,w,α,β)=B(α+∑j=1,j=sNtIk(Ztj))B(α+∑j=1NtIk(Ztj))B(β+∑i:Zi=k,δj=(t,s)Iv(wi))B(β+∑i:Zi=kIv(wi))
下面就是利用 B \Beta B函数来进行简化。
化简
用例子来看上面的
B ( α + ∑ j = 1 N i I k ( Z i j ) ) B ( α + ∑ j = 1 , j ≠ s N i I k ( Z i j ) ) \cfrac{\Beta(\alpha+\sum_{j=1}^{N_i}I_k(Z_{ij}))}{\Beta(\alpha+\sum_{j=1,j\neq s}^{N_i}I_k(Z_{ij}))} B(α+∑j=1,j=sNiIk(Zij))B(α+∑j=1NiIk(Zij))
的分子和分母
先看分子 ∑ j = 1 N i I k ( Z i j ) \sum_{j=1}^{N_i}I_k(Z_{ij}) ∑j=1NiIk(Zij)是怎么算,这个在上节有讲过,这里再详细写下,例如一个文档里面有六个词,每个词对应的主题 Z i j Z_{ij} Zij如下
| w i 1 w_{i1} wi1 | w i 2 w_{i2} wi2 | w i 3 w_{i3} wi3 | w i 4 w_{i4} wi4 | w i 5 w_{i5} wi5 | w i 6 w_{i6} wi6 |
|---|---|---|---|---|---|
| z i 1 z_{i1} zi1 | z i 2 z_{i2} zi2 | z i 3 z_{i3} zi3 | z i 4 z_{i4} zi4 | z i 5 z_{i5} zi5 | z i 6 z_{i6} zi6 |
| 1 | 1 | 1 | 2 | 3 | 2 |
也就是主题为1的有3个词,为2的有2个词,为3的有1个词,因此 ∑ j = 1 N i I k ( Z i j ) = ( 3 , 2 , 1 ) \sum_{j=1}^{N_i}I_k(Z_{ij})=(3,2,1) ∑j=1NiIk(Zij)=(3,2,1)
上式中 α \alpha α通常是一个向量,可以写作: ( α 1 , α 2 , α 3 , . . . , α k ) (\alpha_1,\alpha_2,\alpha_3,...,\alpha_k) (α1,α2,α3,...,αk)
因此上式的分子就变成了 B ( α 1 + 3 , α 2 + 2 , α 3 + 1 ) \Beta(\alpha_1+3,\alpha_2+2,\alpha_3+1) B(α1+3,α2+2,α3+1)。
由于分母不包含当前词的主题,当当前词是 w i 1 w_{i1} wi1的时候,分母变成了 B ( α 1 + 2 , α 2 + 2 , α 3 + 1 ) \Beta(\alpha_1+2,\alpha_2+2,\alpha_3+1) B(α1+2,α2+2,α3+1)
因此:
B ( α + ∑ j = 1 N i I k ( Z i j ) ) B ( α + ∑ j = 1 , j ≠ s N i I k ( Z i j ) ) = B ( α 1 + n t 1 , α 2 + n t 2 + . . . + α k + n k t 1 ) B ( α 1 + n t 1 ′ , α 2 + n t 2 ′ + . . . + α k + n k t 1 ′ ) (5) \cfrac{\Beta(\alpha+\sum_{j=1}^{N_i}I_k(Z_{ij}))}{\Beta(\alpha+\sum_{j=1,j\neq s}^{N_i}I_k(Z_{ij}))}=\cfrac{\Beta(\alpha_1+n_{t1},\alpha_2+n_{t2}+...+\alpha_k+n_{kt1})}{\Beta(\alpha_1+n'_{t1},\alpha_2+n'_{t2}+...+\alpha_k+n'_{kt1})}\tag5 B(α+∑j=1,j=sNiIk(Zij))B(α+∑j=1NiIk(Zij))=B(α1+nt1′,α2+nt2′+...+αk+nkt1′)B(α1+nt1,α2+nt2+...+αk+nkt1)(5)
n t i n_{ti} nti表示第 t t t个文档有多少单词被分配主题 i i i
n t i ′ n'_{ti} nti′表示去掉 Z t s Z_{ts} Zts后,第 t t t个文档有多少单词被分配主题 i i i
这里的分子分母都有 k k k项,而且只有一项不一样。
继续化简前先给出 B \Beta B函数的形式:

因此: B ( α 1 , α 2 , α 3 , . . . , α k ) = ∏ k = 1 K ( Γ ( α k ) Γ ( ∑ k = 1 K α k ) \Beta(\alpha_1,\alpha_2,\alpha_3,...,\alpha_k)=\cfrac{\prod_{k=1}^K(\Gamma(\alpha_k)}{\Gamma(\sum_{k=1}^K\alpha_k)} B(α1,α2,α3,...,αk)=Γ(∑k=1Kαk)∏k=1K(Γ(αk)
( 5 ) = ∏ k = 1 K ( Γ ( α k + n t k ) ) Γ ( ∑ k = 1 K ( α k + n t k ) ) ⋅ Γ ( ∑ k = 1 K ( α k + n t k ′ ) ) ∏ k = 1 K ( Γ ( α k + n t k ′ ) ) (5)=\cfrac{\prod_{k=1}^K(\Gamma(\alpha_k+n_{tk}))}{\Gamma(\sum_{k=1}^K(\alpha_k+n_{tk}))}\cdot\cfrac{\Gamma(\sum_{k=1}^K(\alpha_k+n'_{tk}))}{\prod_{k=1}^K(\Gamma(\alpha_k+n'_{tk}))} (5)=Γ(∑k=1K(αk+ntk))∏k=1K(Γ(αk+ntk))⋅∏k=1K(Γ(αk+ntk′))Γ(∑k=1K(αk+ntk′))
伽玛函数: Γ ( n ) = ( n − 1 ) ! \Gamma(n)=(n-1)! Γ(n)=(n−1)!,而且上面提到过 α k + n t k \alpha_k+n_{tk} αk+ntk和 α k + n t k ′ \alpha_k+n'_{tk} αk+ntk′都有k项,而且只有一项不一样,且不一样的项相差1。例如:
当 Z t s = 2 Z_{ts}=2 Zts=2,则 n t 2 − n t 2 ′ = 1 n_{t2}-n'_{t2}=1 nt2−nt2′=1且 n t i = n t i ′ , i ≠ 2 n_{ti}=n'_{ti},i\neq2 nti=nti′,i=2,因此:
( 5 ) = ∏ k = 1 K ( Γ ( α k + n t k ) ) ∏ k = 1 K ( Γ ( α k + n t k ′ ) ) ⋅ Γ ( ∑ k = 1 K ( α k + n t k ′ ) ) Γ ( ∑ k = 1 K ( α k + n t k ) ) = α k + n t u n e w ∑ k = 1 K α k + n t n e w ⋅ β w i + n u w i n e w ∑ v = 1 V β v + n u n e w (5)=\cfrac{\prod_{k=1}^K(\Gamma(\alpha_k+n_{tk}))}{\prod_{k=1}^K(\Gamma(\alpha_k+n'_{tk}))}\cdot\cfrac{\Gamma(\sum_{k=1}^K(\alpha_k+n'_{tk}))}{\Gamma(\sum_{k=1}^K(\alpha_k+n_{tk}))}\\ =\cfrac{\alpha_k+n_{tu}^{new}}{\sum_{k=1}^K\alpha_k+n_t^{new}}\cdot \cfrac{\beta_{w_i}+n_{uw_i}^{new}}{\sum_{v=1}^V\beta_v+n_u^{new}} (5)=∏k=1K(Γ(αk+ntk′))∏k=1K(Γ(αk+ntk))⋅Γ(∑k=1K(αk+ntk))Γ(∑k=1K(αk+ntk′))=∑k=1Kαk+ntnewαk+ntunew⋅∑v=1Vβv+nunewβwi+nuwinew
n t u n e w n_{tu}^{new} ntunew表示当前第t个文档有多少个单词被分配到主题u(丢掉 Z t s Z_{ts} Zts,不考虑当前词)
n t n e w n_t^{new} ntnew表示当前第t个文档的单词数量(丢掉 Z t s Z_{ts} Zts,不考虑当前词)
n u w i n e w n_{uw_i}^{new} nuwinew表示对于单词 w i w_i wi有多少次被分配到了主题u(丢掉 Z t s Z_{ts} Zts,不考虑当前词)
n u n e w n_u^{new} nunew表示所有文档中有多少单词分配到了主题u(丢掉 Z t s Z_{ts} Zts,不考虑当前词)
小栗子
假设有两个文档:

主题数量k为3,词库大小为4.
先随机初始化每个单词的主题。

超参数 α = ( 0.1 , 0.1 , 0.1 ) , β = ( 0.1 , 0.1 , 0.1 , 0.1 ) \alpha=(0.1,0.1,0.1),\beta=(0.1,0.1,0.1,0.1) α=(0.1,0.1,0.1),β=(0.1,0.1,0.1,0.1)
下面按化简后的公式来进行计算第一个文档的第一个单词:

这个时候把第一个单词【今天】从文档1中去掉,可以看到 n 1 , 1 n e w = 2 n_{1,1}^{new}=2 n1,1new=2(就是还有2个单词分配到主题1), n 1 n e w = 6 n_1^{new}=6 n1new=6(还剩下6个单词)
因为每一个单词在不同文档可以有不同的主题,也就是有不同的主题概率分布,因此:把第一个单词【今天】从文档1中去掉,没有【今天】分配到主题1,因此 n 1 , w 1 n e w = 0 n_{1,w_1}^{new}=0 n1,w1new=0,但是除了第一个单词【今天】外,分配到主题1的单词有3个,因此 n 1 n e w = 3 n_1^{new}=3 n1new=3
P ( Z 1 , 1 = 1 ∣ Z − ( 1 , 1 ) , w , α , β ) = 0.1 + 2 0.1 + 0.1 + 0.1 + 6 ⋅ 0.1 + 0 0.1 + 0.1 + 0.1 + 0.1 + 3 P(Z_{1,1}=1|Z_{-(1,1)},w,\alpha,\beta)=\cfrac{0.1+2}{0.1+0.1+0.1+6}\cdot \cfrac{0.1+0}{0.1+0.1+0.1+0.1+3} P(Z1,1=1∣Z−(1,1),w,α,β)=0.1+0.1+0.1+60.1+2⋅0.1+0.1+0.1+0.1+30.1+0
同理:
P ( Z 1 , 1 = 2 ∣ Z − ( 1 , 1 ) , w , α , β ) = 0.1 + 2 0.1 + 0.1 + 0.1 + 6 ⋅ 0.1 + 1 0.1 + 0.1 + 0.1 + 0.1 + 5 P(Z_{1,1}=2|Z_{-(1,1)},w,\alpha,\beta)=\cfrac{0.1+2}{0.1+0.1+0.1+6}\cdot \cfrac{0.1+1}{0.1+0.1+0.1+0.1+5} P(Z1,1=2∣Z−(1,1),w,α,β)=0.1+0.1+0.1+60.1+2⋅0.1+0.1+0.1+0.1+50.1+1
P ( Z 1 , 1 = 3 ∣ Z − ( 1 , 1 ) , w , α , β ) = 0.1 + 2 0.1 + 0.1 + 0.1 + 6 ⋅ 0.1 + 2 0.1 + 0.1 + 0.1 + 0.1 + 4 P(Z_{1,1}=3|Z_{-(1,1)},w,\alpha,\beta)=\cfrac{0.1+2}{0.1+0.1+0.1+6}\cdot \cfrac{0.1+2}{0.1+0.1+0.1+0.1+4} P(Z1,1=3∣Z−(1,1),w,α,β)=0.1+0.1+0.1+60.1+2⋅0.1+0.1+0.1+0.1+40.1+2
计算完毕后,进行归一化得到(使得累加等于1):
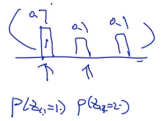
然后就可以进行multinomial采样。
小结
P ( Z t s ∣ Z − t s , w , α , β ) = α k + n t u n e w ∑ k = 1 K α k + n t n e w ⋅ β w i + n u w i n e w ∑ v = 1 V β v + n u n e w P(Z_{ts}|Z_{-ts},w,\alpha,\beta)=\cfrac{\alpha_k+n_{tu}^{new}}{\sum_{k=1}^K\alpha_k+n_t^{new}}\cdot \cfrac{\beta_{w_i}+n_{uw_i}^{new}}{\sum_{v=1}^V\beta_v+n_u^{new}} P(Zts∣Z−ts,w,α,β)=∑k=1Kαk+ntnewαk+ntunew⋅∑v=1Vβv+nunewβwi+nuwinew
右边的第一项代表一个文档中的单词的主题分类,当一个文档中的单词分类越集中,主题也越集中,例如一个文档中的有10个单词,前面9个都是主题1,那么第十个单词也会倾向于采样为第1个主题。
第二项是所有文档中某个单词的主题分类影响,例如所有文章中某个单词出现100次,80次是主题1,那么该单词被抽样为主题1的概率越大。
这篇关于27[NLP训练营]collapsed gibbs sampling的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!