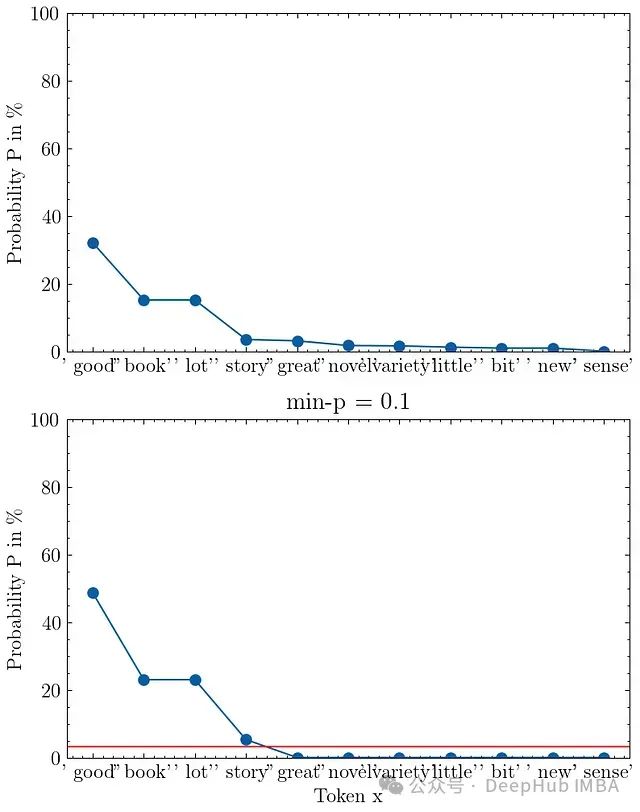
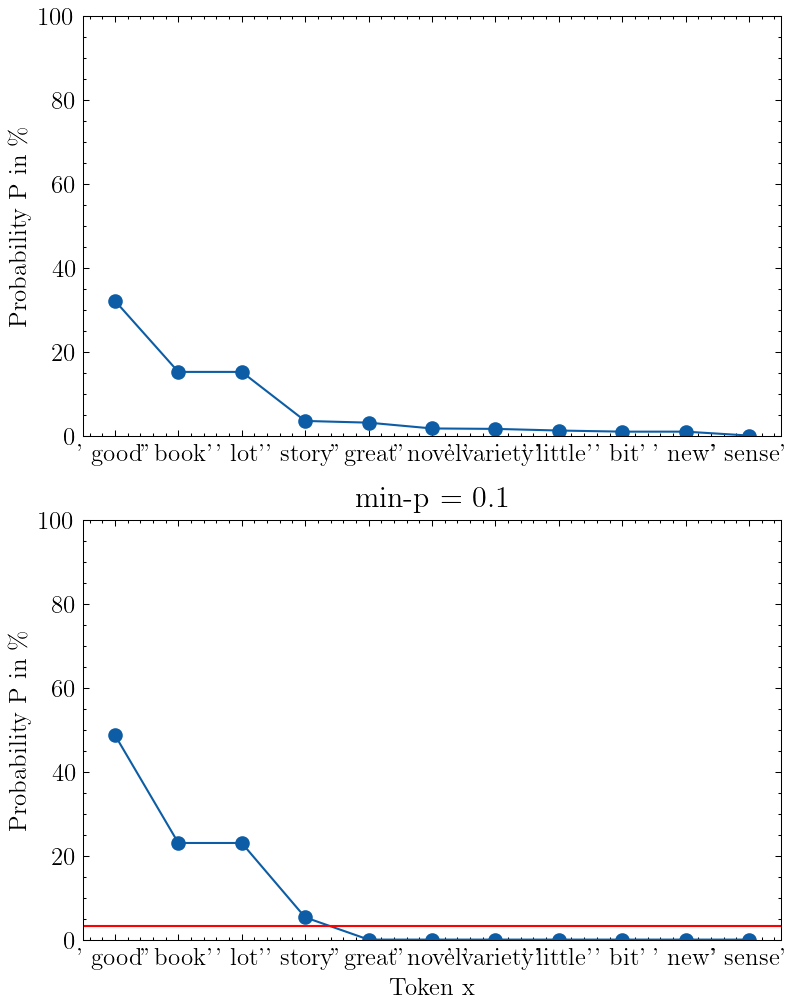
本文主要是介绍蓄水池采样 Reservoir Sampling,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
# coding:utf8
import random# 从n个数中采样k个数
def reservoir_sampling(n, k):# 所有数据pool = [i for i in range(n)]# 前k个数据res = [i for i in range(k)]for i in range(k, n):v = random.randint(0, i)if v < k:res[v] = ireturn res
先选中第1到k个元素,作为被选中的元素。然后依次对第k+1至第N个元素做如下操作:
x是元素的序号,每个元素都有k/x的概率被选中,然后等概率的(1/k)替换掉被选中的元素。
这篇关于蓄水池采样 Reservoir Sampling的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!