本文主要是介绍Collapsed Gibbs Sampling for Latent Dirichlet Allocation on Spark,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
本文针对Spark上广泛使用的潜在Dirichlet分配(LDA)模型,实现了一种折叠Gibbs抽样方法。 Spark是一款面向大规模数据处理的快速内存集群计算框架,成为大数据小镇的领域话题已经有一段时间了。 适用于迭代和交互算法。 该方法将数据集分割成P∗P个分区,使用规则将这些分区洗牌并重组成P个子数据集,避免采样冲突,其中每个P个子数据集只包含P个分区,然后逐个并行处理每个子数据集。 尽管增加了迭代次数,但该方法减少了数据通信开销,充分利用了Spark的高效迭代执行,并在我们的实验中对大规模数据集产生了显著的加速比。
1.介绍
潜在狄利克雷分配(LDA)模型是由Blee等人首先提出的一般概率框架。 LDA模型的主要思想是基于这样的假设,即每个文档都可以被视为各种主题的混合,其中一个主题表示为单词上的多项式概率分布。 学习各种文档主题和主题词分布的混合系数是一个贝叶斯推理问题。(2003)发展了变分贝叶斯算法来近似后验分布; Griffiths和Steyvers(2004)随后提出了一种使用 collapsed Gibbs抽样从数据中学习模型的替代推断方法。 这两种方法各有优缺点:变分方法计算速度较快,但可能导致不准确的推断和有偏学习;折叠Gibbs抽样方法虽然原则上更精确,但其计算复杂度很高,这使得它在大数据集上效率低下。
随着大数据时代的到来,我们世界的数据量呈爆炸式增长,分析大数据集成为许多领域的关键。 以折叠Gibbs抽样算法为代表的LDA模型目前已广泛应用于机器学习和数据挖掘中,特别是在分类、推荐和Web搜索等对精度和速度都有很高要求的领域。 已经探索了一些基于变分贝叶斯的适应大数据的改进,如 collapsed 变分贝叶斯(CVB)算法已在Mahout和Win等人中实现。 (2013)将GPU和Hadoop相结合进行了改进。 CVB比 collapsed Gibbs采样收敛速度更快,但后者在足够样本的情况下最终获得了更好的解。 因此,加速LDA模型的Collapsed Gibbs抽样有着重要的动机。
在此背景下,我们介绍了我们的并行 collapsed Gibbs采样算法,并演示了如何在Zaharia等人提出的一个新的内存集群计算框架Spark上实现该算法(2010、2012)。 我们算法的关键思想是减少通信和同步所需的时间。 通信时只需并行传递部分全局参数,同步时不需要复杂的计算。
然而,我们的算法的一个 缺点是迭代次数显著增加。 为了克服这个问题,我们采用了非常适合迭代和交互算法的Spark来实现我们的方法。
2.相关工作
为了加快LDA模型的速度,人们探索了各种实现和改进方法。 相关的collapsed Gibbs 抽样方法如下:
- Newman (2007,2009)提出了两种版本的LDA,其中数据和参数分布在不同的处理器上:近似分布式LDA模型(AD-LDA)和分层分布式LDA模型(HD-LDA)。 在AD-LDA中,他们简单地在每个处理器上实现LDA,并在局部Gibbs采样迭代后更新全局参数。 HD-LDA可以看作是P-LDA的混合模型,它优化了正确的后验概率,但是实现起来比较复杂,运行速度也比较慢。
- Porteous (2008)提出了一种新的抽样方案,它产生与标准抽样方案完全相同的结果,但速度更快。
- (2008)异步分布式版本的LDA(Async-LDA)是由Asuncon等人介绍的。 在异步LDA中,每个处理器执行局部collapsed 的Gibbs采样步骤,然后是与另一个随机处理器通信的步骤,以获得异步计算的好处。(2010)Low等人提出的基于图的并行机器学习框架GraphLab对Async-LDA进行了改进。
- 严等 (2009)提出了基于图形处理单元(GPU)的LDA模型的collapsed Gibbs采样和collapsed 变分贝叶斯并行算法,GPU具有大量的内置共享内存的并行处理器。 他们提出了一种新颖的数据分区方案来克服共享内存的限制。
- Wang(2009)在MPI和MapReduce上实现了collapsed Gibbs采样,称为PLDA,然后Liu(2011)加强了实施,并将新方法称为PLDA+。
- 肖和Stibor(2010)提出了一种新的动态采样策略来显着提高collapsed Gibbs采样的效率,并提出了一种直接并行化来进一步提高效率。
- Ihler和Newman(2012)提出了一种改进的并行Gibbs采样器,它获得了与AD-LDA相同的加速比,但与顺序采样器相比,它提供了近似质量的在线度量。
在这些工作中,首次提出并分别在GraphLab、GPU、MPI和MapReduce上实现了并行LDA。 所有这些都能以较高的提速比和并行效率运行。 与他们的工作不同,我们改进了折叠的Gibbs抽样方法,并在Spark上实现了它,Spark是一种旨在提高数据分析速度的新集群计算模型。
3.预先知识
(1)LDA
(2)Spark
Spark是一个用于大规模数据处理的快速通用引擎,在内存中运行程序的速度比Hadoop MapReduce快100倍,在磁盘上快10倍。 该项目始于2009年加州大学伯克利分校AMPLab的一个研究项目,并于2010年初开源。 发布后,Spark在GitHub上发展了一个开发者社区,并于2013年进入apache作为其永久住所。 现在有广泛的贡献者开发该项目(来自25家公司的120多名开发人员)spa。
与Hadoop相比,Spark被设计为运行更复杂的多遍算法,例如机器学习和图形处理中常见的迭代算法;或者执行更具交互性的特别查询来探索数据。 这些应用程序的核心问题是,多通道应用程序和交互式应用程序都需要跨多个MapReduce步骤共享数据。 不幸的是,在 MapReduce的并行操作之间共享数据的唯一方法是写入分布式文件系统,这会由于数据复制和磁盘I/O而增加大量开销。事实上,人们已经发现,这种开销可能占据在Hadoop上实现的常见机器学习算法运行时间的90%以上。 Spark通过提供称为弹性分布式数据集(RDD)的新存储原语克服了这一问题,该原语表示跨一组计算机分区的对象的只读集合,并通过跟踪如何计算以前RDDS中丢失的数据来提供容错,而无需复制。 RDD是Spark中的关键抽象。 用户可以在跨机器的内存或磁盘中显式缓存RDD,并在多个并行操作中重用它。
Spark包括MLlib,这是一个针对大数据的机器学习算法库,包括分类、回归、聚类、协作过滤、降维以及底层优化原语。 然而,到目前为止还没有添加主题模型算法。
4.基于Spark的LDA分布式学习
现在,我们介绍我们的分布式LDA版本,其中数据和参数分布在Spark上的不同处理器上(我们称之为Spark-LDA)。 表1显示了本文中使用的与Spark-LDA相关的符号。 我们首先简单地将Nd和Nw分布在P个处理机上,每个处理机上  ,然后展示了如何将数据集X拆分、洗牌和重组为具有P个分区的P个子数据集Xp。
,然后展示了如何将数据集X拆分、洗牌和重组为具有P个分区的P个子数据集Xp。

为了避免在Nd和Nw上潜在的读/写冲突,必须确认子数据集中的 每个分区不能包含相同的文档和单词。 Ihler和Newman(2012)提出了一种数据分区方案来满足这一要求。 但是,该方案需要高效的共享内存,因为每个处理器都需要访问所有分区。 显然,它不适用于集群计算框架,所以我们对其进行了一些修改,将其应用于Spark。 首先将数据集X分成P个部分(P∗P),将行和列划分为P个部分,将Nd和Nw分别放入对应的X的 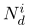 和
和 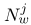 中;然后从X中选择P个分区,每个分区包含不同的文档和单词,重新组合为一个子数据集。 图2显示了上述过程的一个简单示例,我们将在下面描述详细信息。
中;然后从X中选择P个分区,每个分区包含不同的文档和单词,重新组合为一个子数据集。 图2显示了上述过程的一个简单示例,我们将在下面描述详细信息。

为了确保通信过程中的网络负载均衡, 每个分区与  关联的列数必须相等。 此外,我们必须保证每个分区中的字数彼此接近,以便在每个子数据集的采样过程中均衡每个处理器的负载。 事实上,我们只需要确保数值在最大值和最小值之间是最小的。
关联的列数必须相等。 此外,我们必须保证每个分区中的字数彼此接近,以便在每个子数据集的采样过程中均衡每个处理器的负载。 事实上,我们只需要确保数值在最大值和最小值之间是最小的。
我们采取以下步骤来满足上述要求:
- 我们首先将数据集X放到P个分区中,通过将列划分为相等的P个部分;然后交换列,以使每个分区中的字数更接近。 之后,我们划分对应于X的Nw列。
- 然后我们将行划分为P个部分,现在数据集X已经被拆分成P∗P分区;并且使每个分区中属于同一个子数据集的重组后的字数更接近。 虽然行数不一定相等,但仍然很难找到有效的方法来解决这个问题。 在这里,我们使用一种简单的随机化方法来交换行,并计算属于相同子数据集的每个分区中最大和最小字数之间的差异。 差异越小,分区越好。 我们可以多次运行此方法,并通过调用RDDS缓存方法来选择最好的方法,以告诉Spark尝试将数据集保存在内存中。 它速度很快,因为数据集在内存中,可以并行计算。 在我们的实验中,它工作得很好。
- 最后,我们选择P个无冲突的分区,并将它们重新组合成子数据集。 重复这一过程,最终得到P个子数据集。
考虑对子数据集的采样过程。 每个子数据集包含P个非冲突分区,可以将其分配给P个处理器;回想一下,Nid和Njw也已分配。 因此,我们可以混洗对应于分区的Nid和Njw,并让它们在一个处理器上包含相同的文档和单词。 然后在每个处理器上执行标准折叠Gibbs采样算法,同时更新Nid和Njw。 在完成子数据集中所有分区的采样后,我们通过跟踪 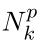 变化的
变化的 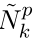 计算Nk,然后将Nk广播给所有处理器并存储为
计算Nk,然后将Nk广播给所有处理器并存储为 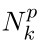 。 图3通过一个简单的示例给出了上述过程。因此,我们已经对子数据集完成了采样过程,然后需要对剩余子数据集重复此过程。 在对所有子数据集进行采样之后,我们已经完成了全局数据集的迭代。
。 图3通过一个简单的示例给出了上述过程。因此,我们已经对子数据集完成了采样过程,然后需要对剩余子数据集重复此过程。 在对所有子数据集进行采样之后,我们已经完成了全局数据集的迭代。
图3.一个简单的采样过程示例。 虚线表示同一台机器上的变速器,实线表示不同机器之间的转换。

要在Spark上实现算法1,必须解决两个问题。 一种是要求在采样过程中操作三个RDDS,即Xp、Nd和Nw。 但是, 默认情况下,Spark不擅长操作两个以上的RDDS。 我们采取以下步骤来解决这个问题。 首先,我们将Xp、Nd和Nw组合成一个RDD并开始采样;采样后,我们将RDD拆分成三个RDD。
另一个问题是RDD的分区方式。 默认情况下,Spark将哈希码计算为分区ID,并且它通过确定RDD的范围提供了另一种对RDD进行分区的方法。 这两种方法都不能满足我们的要求,所以我们实现了一个新的分区方法, 它使用我们指定的id作为分区id。 完成后,我们实现了一个位置函数来确定X和Nd的分区是否按照算法的要求放置。
显然,这种并行方法大大增加了迭代次数;但是,所有操作都在内存中执行,并且Spark具有高效的压缩以减少网络中的数据传输大小,因此速度非常快。
5.讨论与总结
在本文中,我们描述了我们的分布式方法的细节。 实验结果表明,该算法在保证准确率的同时,获得了令人印象深刻的加速比。 但是,还有两个问题需要解决。 一个是每个分区中字太少导致的加速比较低;另一个是在数据集足够大的情况下如何使加速比接近完美 。 它们都需要同时操作多个RDDS。 限于星火的地位,这两个问题很难解决。 Spark毕竟还处于高速发展期,在众多开发者的贡献下,必将走向成熟。 我们将继续专注于Spark,并在未来优化我们的算法。
这篇关于Collapsed Gibbs Sampling for Latent Dirichlet Allocation on Spark的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





