dpo专题

RLHF PPO DPO
生成式大模型的RLHF技术(一):基础 DPO: Direct Preference Optimization 论文解读及代码实践 深入对比 DPO 和 RLHF 深入理解DPO(Direct Preference Optimization)算法

强化学习-优化策略算法(DPO和PPO)
DPO(Direct Preference Optimization)和 PPO(Proximal Policy Optimization)虽然都是用于优化策略的算法,但它们在理论基础、优化目标和应用场景上存在显著区别。 优化目标 • PPO: • PPO 是一种基于策略梯度的优化算法,其目标是通过最大化累积奖励来优化策略。PPO 通过限制策略更新的幅度(剪切损失函数),确保训练过程中的策略更

深入理解DPO(Direct Preference Optimization)算法
目录 1. 什么是DPO?2. Bradley-Terry模型2.1 奖励模型的训练 3. 从PPO到DPO4. DPO的简单实现5. 梯度分析Ref 1. 什么是DPO? 直接偏好优化(Direct Preference Optimization, DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的强化学习算法,DPO 可以通过与有监督微调(SFT)相似的复杂度实现模型对

大模型对齐:DPO vs PPO
现在这些大型语言模型(LLMs),可真是火得不行,各行各业都离不开它们了。它们能处理和写出跟我们差不多的文本,这让自然语言处理、写东西、还有客服这些领域都焕然一新。不过呢,这技术进步的同时也带来了一个大问题,就是怎么让这些模型跟我们人类的想法和价值观保持一致。要是没搞定这个对齐问题,这些模型搞不好就会写出一些伤人的、有偏见的或者让人误解的内容来。 咱们来聊聊怎么让这些大型语言模型更好地符合我们人

大模型学习笔记 - LLM 对齐优化算法 DPO
LLM - DPO LLM - DPO DPO 概述DPO 目标函数推导DPO 目标函数梯度的推导 DPO 概述 大模型预训练是从大量语料中进行无监督学习,语料库内容混杂,训练的目标是语言模型损失,任务是next token prediction,生成的token 不可控,为了让大模型能生成符合人类偏好的答案(无毒无害等)一般都会进行微调和人类对齐,通常采用的方法是 基于人类反馈的强化学习

LLM 直接偏好优化(DPO)的一些研究
今天我们来聊聊大型语言模型(LLMs)吧。要让这些聪明的家伙和咱们人类的价值观还有喜好对上号,这事儿可不简单。以前咱们用的方法,比如基于人类反馈的强化学习(RLHF),虽然管用,但是它太复杂了,得用上好多计算资源和数据处理的力气。现在,直接偏好优化(Direct Preference Optimization, DPO)来了,它就像是一股清流,给咱们提供了一个既简单又高效的新选择。DPO简化了优化
使用DPO微调大模型Qwen2详解
简介 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。但传统的RLHF比较复杂,且还需要奖励模型,故DPO方法被提出,其将现有方法使用的基于强化学习的目标转换为可以通过简单的二元交叉熵损失直
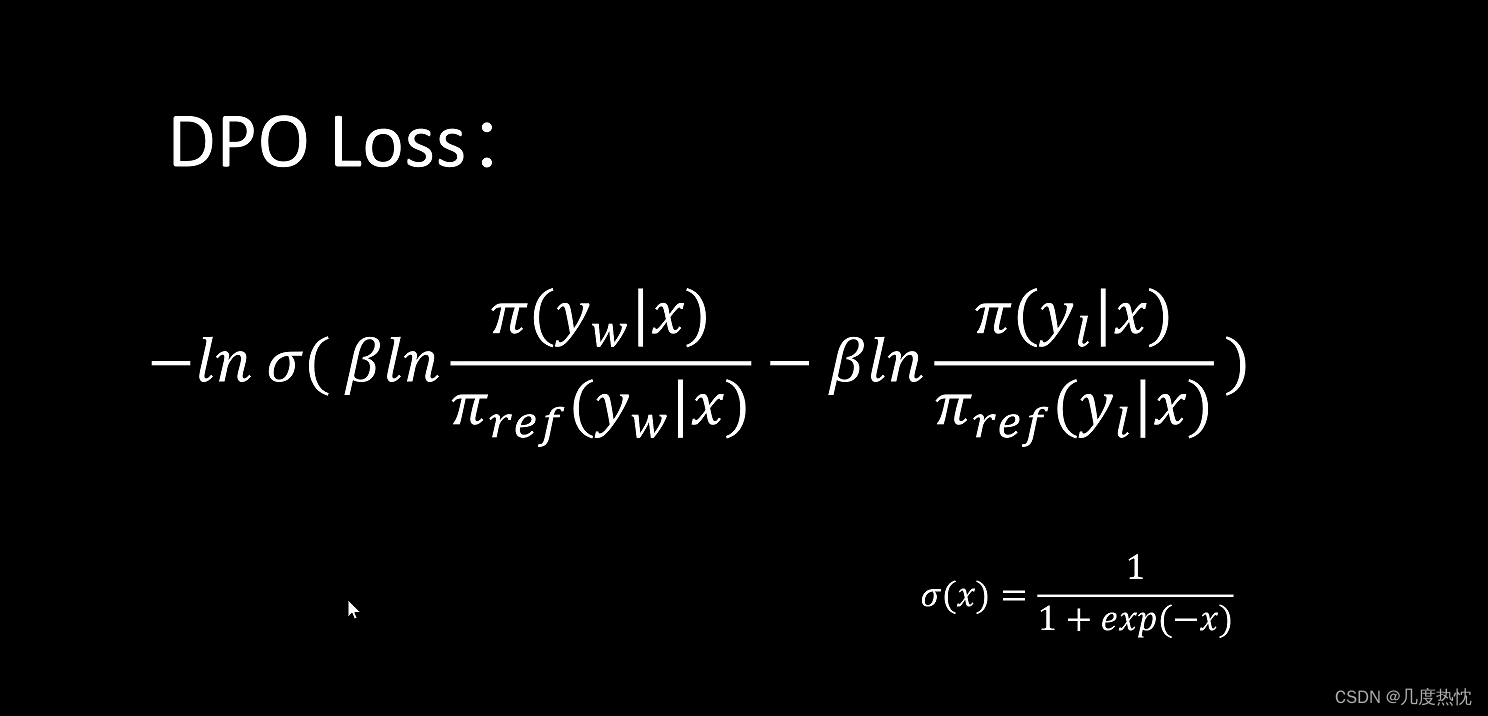
【强化学习】DPO(Direct Preference Optimization)算法学习笔记
【强化学习】DPO(Direct Preference Optimization)算法学习笔记 RLHF与DPO的关系KL散度Bradley-Terry模型DPO算法流程参考文献 RLHF与DPO的关系 DPO(Direct Preference Optimization)和RLHF(Reinforcement Learning from Human Feedback)都是用于训
【极速前进】20240415-20240421:TR-DPO、压缩与智能的线性关系、模拟伪代码改善算术能力、Many-shot、合成数据综述
一、TR-DPO:更新reference模型能实现更好的对齐 论文地址:https://arxiv.org/pdf/2404.09656.pdf 语言模型对齐的训练目标是: max π θ E x ∼ D , y ∼ π θ ( y ∣ x ) [ r ϕ ( x , y ) ] − β D KL [ π θ ( x , y ) ∥ π ref ( x , y ) ] (1) \ma

EXIN DPO 数据保护官来啦
大数据时代,在充分挖掘和发挥大数据价值的同时,解决好数据安全与个人信息保护等问题刻不容缓。根据GDPR要求,核心活动涉及处理或存储大量的欧盟公民数据、处理或存储特殊类别的个人数据(健康记录、犯罪记录)的组织必须指定数据保护官DPO。DPO主要负责就GDPR规定提供咨询意见,向最高管理层报告。未来设立DPO职位也将会在国际化企业和政府部门内成为趋势。 DPO发展前景 欧美国家早在2000年开始
RLAIF(0)—— DPO(Direct Preference Optimization) 原理与代码解读
之前的系列文章:介绍了 RLHF 里用到 Reward Model、PPO 算法。 但是这种传统的 RLHF 算法存在以下问题:流程复杂,需要多个中间模型对超参数很敏感,导致模型训练的结果不稳定。 斯坦福大学提出了 DPO 算法,尝试解决上面的问题,DPO 算法的思想也被后面 RLAIF(AI反馈强化学习)的算法借鉴,这个系列会从 DPO 开始,介绍 SPIN、self-reward model

微调实操四:直接偏好优化方法-DPO
在《微调实操三:人类反馈对语言模型进行强化学习(RLHF)》中提到过第三阶段有2个方法,一种是是RLHF, 另外一种就是今天的DPO方法, DPO通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好,DPO相较于RLHF更容易实现且易于训练,效果更好. 1、DPO VS RLHF DPO 是一种自动微调方法,它通过最大化预训练模型在特定任务上的奖
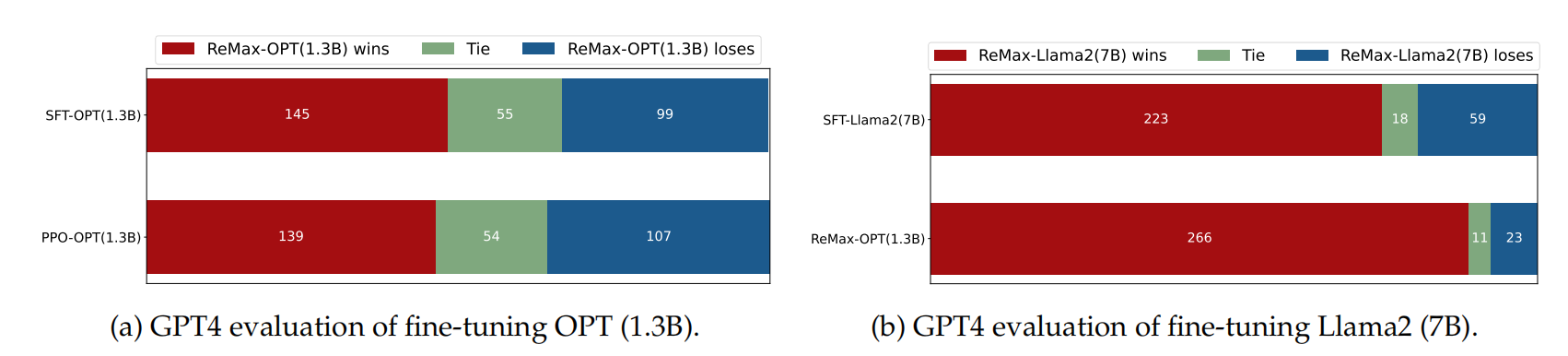
【LLM】大模型之RLHF和替代方法(DPO、RAILF、ReST等)
note SFT使用交叉熵损失函数,目标是调整参数使模型输出与标准答案一致,不能从整体把控output质量,RLHF(分为奖励模型训练、近端策略优化两个步骤)则是将output作为一个整体考虑,优化目标是使模型生成高质量回复。 启发1:像可以用6b、66b依次得到差一点、好一点的target构造排序数据集,进行DPO直接偏好学习或者其他RLHF替代方法(RAILF、ReST等),比直接RLHF更
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)。 MedicalGPT: Training Your Own Medical GPT Model with ChatGPT Training Pipeline. 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化
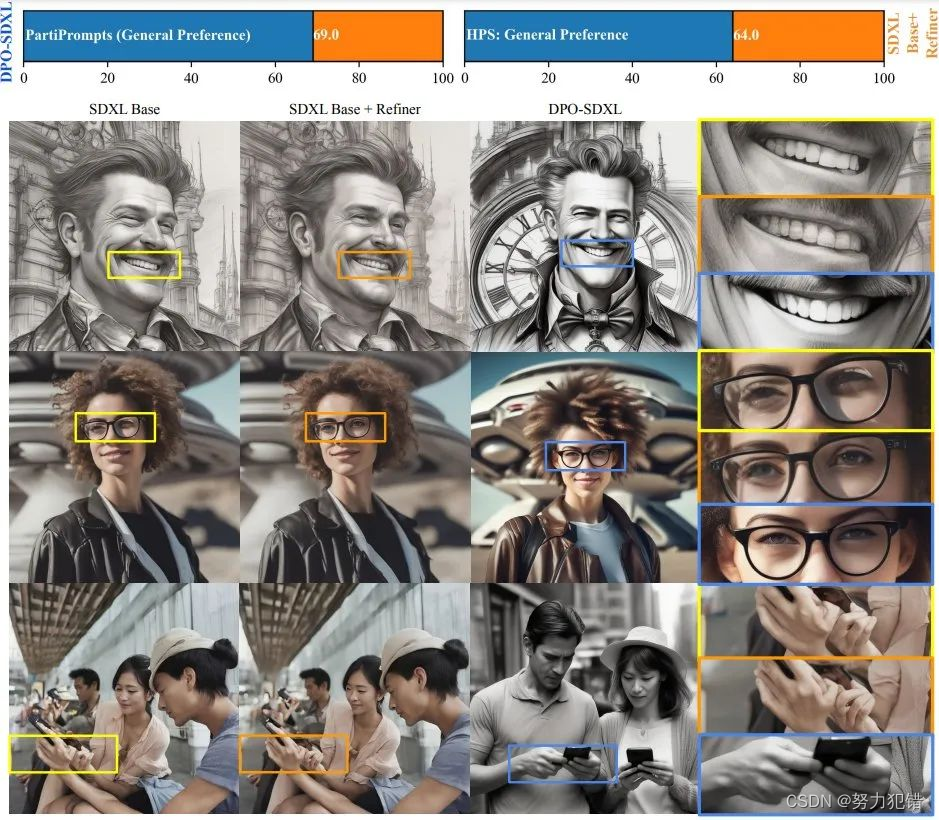
人类偏好导向:DPO技术重塑SDXL-1.0图像生成
引言 在AI领域,适应和理解人类偏好一直是技术发展的重要方向。斯坦福大学研究团队最近提出的Diffusion-DPO方法,旨在将这一理念应用于图像生成模型,特别是在文本到图像的转换领域。 Huggingface模型下载: https://huggingface.co/mhdang/ AI快站模型免费加速下载: https://aifasthub.com/models/mhdang/
![[NLP] LLM---<训练中文LLama2(五)>对SFT后的LLama2进行DPO训练](https://img-blog.csdnimg.cn/51e0f89539834e8ca494b4d047d0a18c.png)
[NLP] LLM---<训练中文LLama2(五)>对SFT后的LLama2进行DPO训练
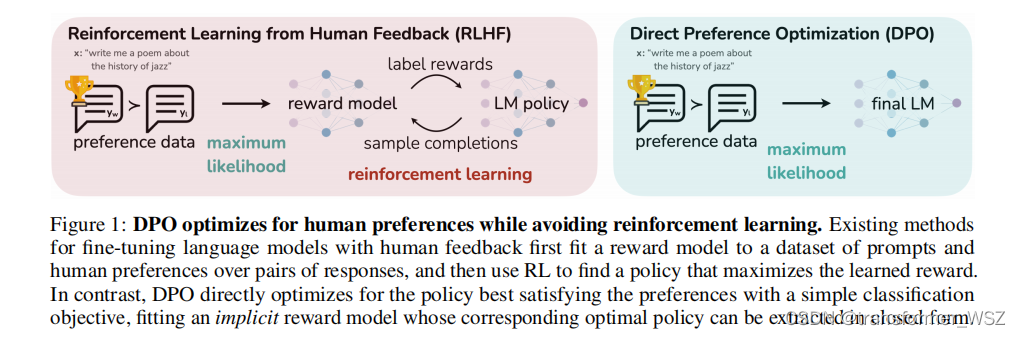
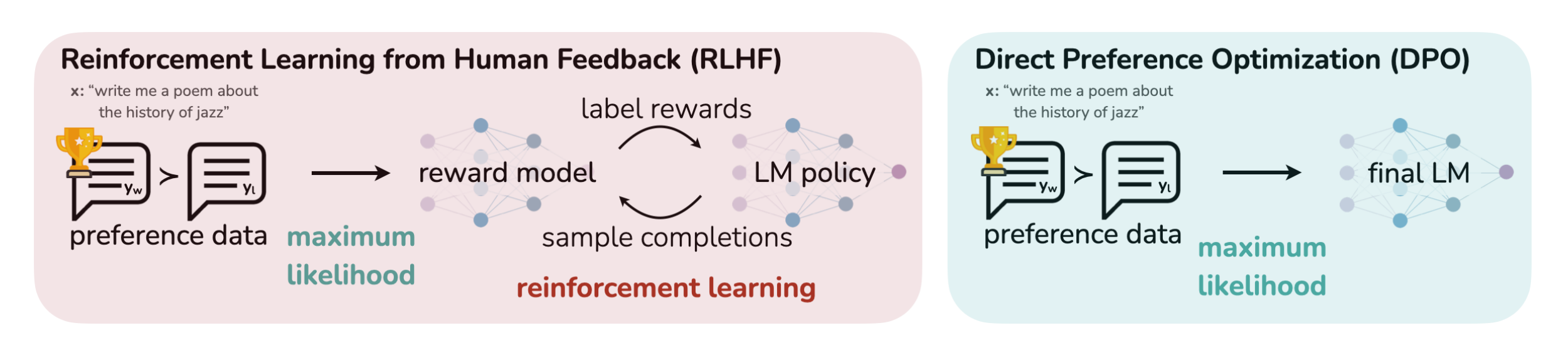
当前关于LLM的共识 大型语言模型(LLM)使 NLP 中微调模型的过程变得更加复杂。最初,当 ChatGPT 等模型首次出现时,最主要的方法是先训练奖励模型,然后优化 LLM 策略。从人类反馈中强化学习(RLHF)极大地推动了NLP的发展,并将NLP中许多长期面临的挑战抛在了一边。基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,R
RLHF的替代算法之DPO原理解析:从Zephyr的DPO到Claude的RAILF
前言 本文的成就是一个点顺着一个点而来的,成文过程颇有意思 首先,如上文所说,我司正在做三大LLM项目,其中一个是论文审稿GPT第二版,在模型选型的时候,关注到了Mistral 7B(其背后的公司Mistral AI号称欧洲的OpenAI,当然 你权且一听,切勿过于当真)而由Mistral 7B顺带关注到了基于其微调的Zephyr 7B,而一了解Zephyr 7B的论文,发现它还挺有意思的,即

对话跨国消费品牌DPO:数据安全合规从何做起?8.11直播见
2020年,某商业服务商“删库跑路”事件导致股价大跌,市值蒸发超30亿港币; 2022年,某知名出行服务商因数据安全问题被处80.26亿人民币罚款; 前日,某银行上海分行因存在信息安全和员工行为管理严重违反审慎经营规则,被罚款50万元,相关责任人被禁止从事银行业工作10年。 在巨额罚款的“反面教材”之外,海内外近年来还有成百上千个“责令改进”的案例。 当警钟频频响起,这一刻,企业主心里究竟