本文主要是介绍LLM 直接偏好优化(DPO)的一些研究,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我们来聊聊大型语言模型(LLMs)吧。要让这些聪明的家伙和咱们人类的价值观还有喜好对上号,这事儿可不简单。以前咱们用的方法,比如基于人类反馈的强化学习(RLHF),虽然管用,但是它太复杂了,得用上好多计算资源和数据处理的力气。现在,直接偏好优化(Direct Preference Optimization, DPO)来了,它就像是一股清流,给咱们提供了一个既简单又高效的新选择。DPO简化了优化的过程,不仅减轻了计算的负担,还让模型能更快地适应咱们的喜好。
咱们这篇文章,就是要深入挖掘DPO的精髓,从基础理论到实际怎么操作,再到它在现实世界中的应用,咱们都会一一细说。
偏好对齐的必要性
在我们开始深入了解DPO之前,得先弄明白为啥得让大型语言模型(LLMs)跟咱们人类的喜好挂上钩。虽然这些模型经过大量数据训练后挺厉害的,但有时候它们给出的结果可能跟咱们的价值观不太搭,或者有点偏见,甚至完全不搭边。这种情况可能表现为:
-
弄出些不安全或者有害的东西来;
-
给出的信息不太准确,或者会误导人;
-
反映了训练数据里的一些偏见。
为了解决这些问题,研究人员就搞出了一些用人类反馈来微调LLMs的技术。在这些方法里,RLHF算是最显眼的一个。
聊聊RLHF:DPO的前辈
咱们得先了解下RLHF,也就是基于人类反馈的强化学习,这可是让大型语言模型(LLMs)和人类喜好对上号的首选法宝。咱们来一步步拆解RLHF的过程,看看它都复杂在哪儿:
-
监督式微调(SFT):咱们先拿一个已经学了不少东西的LLM,然后用一堆质量上乘的回应数据来调教它。这样,它在面对特定任务时,就能生成更靠谱、更有条理的输出了。
-
奖励建模:接下来,咱们得训练一个独立的奖励模型来预测人类会喜欢啥。这个过程包括:
-
给定一些提示,生成一堆回应的选项。
-
让真人来评价,看他们更喜欢哪个回应。
-
再训练一个模型,让它学会预测这种喜好。
-
-
强化学习:有了奖励模型后,咱们就可以用强化学习来进一步打磨LLM了。奖励模型会给反馈,帮助LLM学会生成更符合人类喜好的回应。
不过,虽然RLHF挺有效的,但它也有自己的短板:
-
得训练和维护好几个模型,比如SFT模型、奖励模型还有强化学习模型。
-
强化学习的过程可能不太稳定,对那些需要调整的参数特别敏感。
-
计算成本高,需要反复在模型里做前向和后向的计算。
就是因为这些限制,人们开始寻找更简单、更高效的替代方案,于是直接偏好优化(DPO)就应运而生了。
直接偏好优化:核心概念
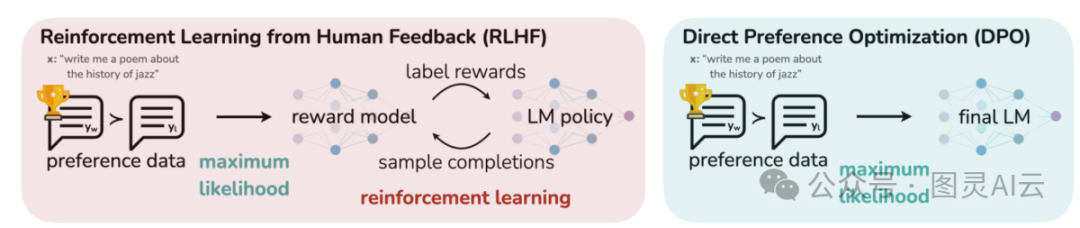
这张图片展示了两种不同的方法来使大型语言模型(LLM)的输出与人类的偏好保持一致:一种是基于人类反馈的强化学习(RLHF),另一种是直接偏好优化(DPO)。RLHF需要一个奖励模型,通过反复的反馈循环来指导语言模型的策略;而DPO则直接对模型输出进行优化,以确保它们与人类偏好的响应相匹配,这是通过使用偏好数据来实现的。这种对比突出了每种方法的优势和可能的应用场景,为未来LLM的训练提供了有价值的见解,帮助我们训练出更能满足人类期望的模型。
DPO背后的几个关键思想包括:
a) 隐式奖励建模:DPO不使用单独的奖励模型,而是将语言模型本身作为隐式的奖励函数来处理。
b) 基于策略的公式:与优化奖励函数不同,DPO直接对策略(也就是语言模型)进行优化,以提高产生符合偏好响应的概率。
c) 封闭形式解:DPO利用数学上的洞察,允许我们以封闭形式求解最优策略,这样就不需要通过迭代的RL更新过程。
更多详细信息和数学原理,可以查看发表在arXiv上的论文《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》(https://arxiv.org/abs/2305.18290)。
实现DPO:实践代码演示
好的,来聊聊这段代码是干嘛的。想象一下,我们有个聪明的语言模型,我们想让它输出的内容更符合人类的喜好。为了做到这一点,我们用PyTorch这个工具来写了一个叫做dpo_loss的函数。

这个函数就像是个指导老师,它告诉模型:"嘿,这里有些规则要遵守哦"。它接收几个重要的信息:
-
pi_logps:这是模型自己认为的每个选项有多靠谱的概率。 -
ref_logps:这是另一个模型,也就是参考模型,认为的选项靠谱程度。 -
yw_idxs和yl_idxs:这两个是告诉模型,哪些选项是人类喜欢的(偏好),哪些是人类不喜欢的(不偏好)。 -
beta:这个参数就像是调整规则严格程度的旋钮。
接下来,函数会做几件事情:
-
它先从模型里拿出人类喜欢和不喜欢的选项的对数概率。
-
然后,它会计算这两个概率的差异,这个差异很重要,因为它决定了模型需要往哪个方向调整。
-
通过
logsigmoid这个函数,我们能得到一个损失值,这个值告诉我们模型现在的输出和人类喜好之间差距有多大。 -
最后,我们还会计算一个奖励值,这个奖励值是基于模型的输出和参考模型的差异,乘以
beta这个旋钮的值来决定的。
总的来说,这个dpo_loss函数就是帮助我们的模型学习如何更好地适应人类的喜好,让它的输出更加精准。
让我们深入研究DPO背后的数学原理,以理解它如何实现这些目标。
DPO的数学原理
DPO是对偏好学习问题的巧妙重新表述,咱们一步步来理解它:
a) 起点:KL约束下的奖励最大化。原始的RLHF目标可以表示为:
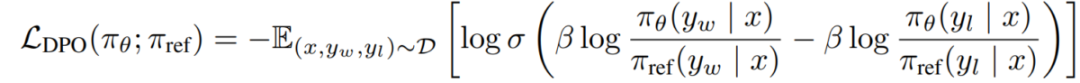
咱们要优化的策略,也就是语言模型πθ,目标是最大化奖励函数r(x,y),同时保持与参考策略πref的KL散度在β控制的约束范围内。
b) 最优策略:数学上可以证明,最优策略的形式是π_r(y|x) = 1/Z(x) * πref(y|x) * exp(1/β * r(x,y))。这里的Z(x)是个归一化常数,用来确保所有选项的概率加起来等于1。
c) 奖励-策略对偶性:DPO的洞见在于,用最优策略来表示奖励函数,即r(x,y) = β * log(π_r(y|x) / πref(y|x)) + β * log(Z(x))。
d) 偏好模型:如果咱们假设偏好遵循Bradley-Terry模型,那么在给定x的情况下,偏好y1而不是y2的概率可以表示为p*(y1 ≻ y2 | x) = σ(r*(x,y1) - r*(x,y2)),这里的σ是逻辑函数。
e) DPO目标:将奖励-策略对偶性放入偏好模型中,咱们得到了DPO的目标公式:L_DPO(πθ; πref) = -E_(x,y_w,y_l)~D [log σ(β * log(πθ(y_w|x) / πref(y_w|x)) - β * log(πθ(y_l|x) / πref(y_l|x)))]。这个目标可以通过标准的梯度下降技术来优化,不需要用到RL算法。
简单来说,DPO就是用一种新的方式来调整语言模型,让它的输出更符合人类的偏好,而且这个过程比传统的强化学习方法更简单、更直接。
实现DPO
现在我们理解了DPO背后的理论,让我们看看如何在实践中实现它。我们将使用Python和PyTorch作为示例:
import torch
import torch.nn.functional as F
class DPOTrainer:def __init__(self, model, ref_model, beta=0.1, lr=1e-5):self.model = modelself.ref_model = ref_modelself.beta = betaself.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):"""pi_logps: policy logprobs, shape (B,)ref_logps: reference model logprobs, shape (B,)yw_idxs: preferred completion indices in [0, B-1], shape (T,)yl_idxs: dispreferred completion indices in [0, B-1], shape (T,)beta: temperature controlling strength of KL penaltyEach pair of (yw_idxs[i], yl_idxs[i]) represents the indices of a single preference pair."""# Extract log probabilities for the preferred and dispreferred completionspi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]# Calculate log-ratiospi_logratios = pi_yw_logps - pi_yl_logpsref_logratios = ref_yw_logps - ref_yl_logps# Compute DPO losslosses = -F.logsigmoid(self.beta * (pi_logratios - ref_logratios))rewards = self.beta * (pi_logps - ref_logps).detach()return losses.mean(), rewardsdef train_step(self, batch):x, yw_idxs, yl_idxs = batchself.optimizer.zero_grad()# Compute log probabilities for the model and the reference modelpi_logps = self.model(x).log_softmax(-1)ref_logps = self.ref_model(x).log_softmax(-1)# Compute the lossloss, _ = self.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)loss.backward()self.optimizer.step()return loss.item()
# Usage
model = YourLanguageModel() # Initialize your model
ref_model = YourLanguageModel() # Load pre-trained reference model
trainer = DPOTrainer(model, ref_model)
for batch in dataloader:loss = trainer.train_step(batch)print(f"Loss: {loss}")
挑战与未来方向
DPO虽然比传统的基于人类反馈的强化学习(RLHF)方法有它的优势,但咱们还是得承认,它面前也有不少难题,需要进一步的研究和开发:
a) 扩大到更大的模型:想想看,现在的语言模型越来越大,参数动不动就是数千亿。要把DPO用在这样的大家伙上,现在还是个难题。不过,研究人员也没闲着,他们正在琢磨一些技术,比如:
-
高效的微调方法:像是LoRA(低秩调整)或者调整模型的前缀,这样可以让模型更快地学习。
-
分布式训练优化:把训练任务分散到多个设备上,大家一起干,效率更高。
-
梯度检查点和混合精度训练:保存一些中间的梯度结果,然后用不同的数值精度来训练,这样可以减少计算资源的消耗。
总之,DPO是个好工具,但要让它在更大的舞台上发挥作用,咱们还得继续努力。
下面来看下使用LoRA与DPO的示例:
from peft import LoraConfig, get_peft_model
class DPOTrainerWithLoRA(DPOTrainer):def __init__(self, model, ref_model, beta=0.1, lr=1e-5, lora_rank=8):lora_config = LoraConfig(r=lora_rank,lora_alpha=32,target_modules=["q_proj", "v_proj"],lora_dropout=0.05,bias="none",task_type="CAUSAL_LM")self.model = get_peft_model(model, lora_config)self.ref_model = ref_modelself.beta = betaself.optimizer = torch.optim.AdamW(self.model.parameters(), lr=lr)
# Usage
base_model = YourLargeLanguageModel()
dpo_trainer = DPOTrainerWithLoRA(base_model, ref_model
)DPO技术虽然强大,但要让它迅速适应新任务或者在只有少量偏好数据的情况下还能表现出色,这可是个技术活。研究人员正在积极探索几种新方法来解决这个问题:
b) 多任务和少样本适应:想象一下,咱们得让DPO技术学会同时处理好几个不同的任务,或者在只有很少的样本数据时也能快速上手。这就需要一些特别的技巧了:
-
元学习框架:这就像是给DPO上一堂速成课,让它能够快速学会新任务。
-
基于提示的DPO微调:通过给DPO一些提示或者线索,帮助它更好地理解和适应新任务。
-
迁移学习:这就好比是让DPO先学习一些通用的偏好,然后再把这些知识应用到特定的领域中去。
这些方法都在尝试让DPO变得更加灵活和强大,无论是面对多样的任务还是只有少量数据的挑战,都能游刃有余。
在现实世界中,人们的偏好往往不是那么明确,有时候甚至是相互矛盾的。这对DPO来说是个挑战,因为它需要能够处理这种模糊或冲突的数据。为了让DPO更健壮,研究人员正在考虑一些解决方案:
c) 处理模糊或冲突的偏好:要让DPO更好地应对现实世界中的复杂情况,研究人员正在探索以下几个方向:
-
概率偏好建模:这种方法不再把偏好看作是非黑即白的,而是给每个偏好赋予一个概率值,这样就能更好地表达不确定性。
-
主动学习以解决模糊性:通过主动寻求额外的信息或数据,来帮助模型解决那些不明确的偏好。
-
多智能体偏好聚合:在多个人或多个模型有不同的偏好时,这种方法可以帮助整合这些不同的偏好,形成一个统一的视角。
举个例子,概率偏好建模可能看起来像这样:假设我们有两个选项A和B,用户对它们的偏好不是绝对的,而是有一定的概率性。在这种情况下,我们可以建立一个模型,不是简单地说用户喜欢A或B,而是说用户喜欢A的概率是70%,喜欢B的概率是30%。这样,DPO就可以在优化过程中考虑到这种概率性,从而更好地适应用户的不确定性。
下面来看个概率偏好建模的示例:
class ProbabilisticDPOTrainer(DPOTrainer):def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob):# Compute log ratiospi_yw_logps, pi_yl_logps = pi_logps[yw_idxs], pi_logps[yl_idxs]ref_yw_logps, ref_yl_logps = ref_logps[yw_idxs], ref_logps[yl_idxs]log_ratio_diff = pi_yw_logps.sum(-1) - pi_yl_logps.sum(-1)loss = -(preference_prob * F.logsigmoid(self.beta * log_ratio_diff) +(1 - preference_prob) * F.logsigmoid(-self.beta * log_ratio_diff))return loss.mean()
# Usage
trainer = ProbabilisticDPOTrainer(model, ref_model)
loss = trainer.compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs, preference_prob=0.8) # 80% confidence in preference-
先从
pi_logps和ref_logps中提取出偏好和不偏好的对数概率。 -
计算这两个对数概率的差值的和。
-
然后,用这个差值和偏好概率来计算损失值。这里用了
logsigmoid函数,它可以帮助我们处理概率相关的计算。 -
最后,损失值取个平均,就得到了我们最终的损失。
使用的时候,我们先创建一个ProbabilisticDPOTrainer的实例,然后把模型、参考模型和其他必要的数据传进去。接着,调用compute_loss方法,传入所有需要的数据和80%的偏好概率,就可以得到损失值了。
这个损失值反映了模型输出和我们偏好之间的差距,训练的时候就是要让这个损失值尽可能小,这样模型就能更好地学习我们的偏好了。
DPO如果和其他的技术结合起来,可能会让我们的系统更强大、更全面。比如说:
d) 结合DPO和其他对齐技术:把DPO和其他一些让模型更符合人类期望的方法结合起来,可能会让我们得到一个既健壮又聪明的系统。这些方法包括:
-
宪法AI原则:就像是给AI设定一套基本法则,确保它在任何情况下都能遵守这些规则。
-
辩论和递归奖励建模:通过辩论来挖掘出更深层次的偏好,然后用这些信息来构建奖励模型。
-
逆强化学习:尝试从观察到的行为中推断出背后的奖励机制,这样可以帮助我们更好地理解模型是如何做决策的。
举个例子,如果我们想要把DPO和宪法AI结合起来,可能会写出类似这样的代码:
class ConstitutionalDPOTrainer(DPOTrainer):def __init__(self, model, ref_model, beta=0.1, lr=1e-5, constraints=None):super().__init__(model, ref_model, beta, lr)self.constraints = constraints or []def compute_loss(self, pi_logps, ref_logps, yw_idxs, yl_idxs):base_loss = super().compute_loss(pi_logps, ref_logps, yw_idxs, yl_idxs)constraint_loss = 0for constraint in self.constraints:constraint_loss += constraint(self.model, pi_logps, ref_logps, yw_idxs, yl_idxs)return base_loss + constraint_loss
# 使用方法
def safety_constraint(model, pi_logps, ref_logps, yw_idxs, yl_idxs):# 在这里实现安全检查逻辑unsafe_score = compute_unsafe_score(model, pi_logps, ref_logps)return torch.relu(unsafe_score - 0.5) # 如果不安全分数超过0.5,就进行惩罚constraints = [safety_constraint]
trainer = ConstitutionalDPOTrainer(model, ref_model, constraints=constraints)
在这个例子中,我们创建了一个ConstitutionalDPOTrainer类,它在原有的DPO训练基础上增加了对宪法AI原则的约束。通过在损失函数中加入这些约束,可以确保模型在训练过程中不会违反我们设定的安全规则。
当我们要把DPO用在现实世界的应用中时,有几个关键点需要注意,这样我们才能确保模型的效果最佳:
a) 数据质量:咱们得保证用来训练的偏好数据是高质量的。这意味着:
-
数据集要广泛,涵盖多种输入和我们期望的行为。
-
注释要一致可靠,确保每次的偏好标记都是准确可信的。
-
要平衡好不同类型的偏好,比如准确性、安全性和风格等。
b) 超参数调整:虽然DPO的超参数没有RLHF那么多,但调整它们还是挺重要的:
-
β(beta):这个参数决定了咱们在满足偏好和保持模型不偏离原始状态之间如何取舍。一般从0.1到0.5开始尝试。 -
学习率:要比通常的微调学习率低一些,大概在1e-6到1e-5之间。
-
批量大小:用大一点的批量,比如32到128,这样通常更适合偏好学习。
c) 迭代细化:DPO可以用迭代的方式来不断优化:
-
首先,用DPO来训练一个初始的模型。
-
然后,用这个训练好的模型来生成新的响应。
-
接下来,在这些新生成的响应上收集更多的偏好数据。
-
最后,用这些新数据来重新训练模型,让模型学习得更好。
通过这种方式,我们可以不断地反馈和优化模型,让它更好地适应我们的需要。
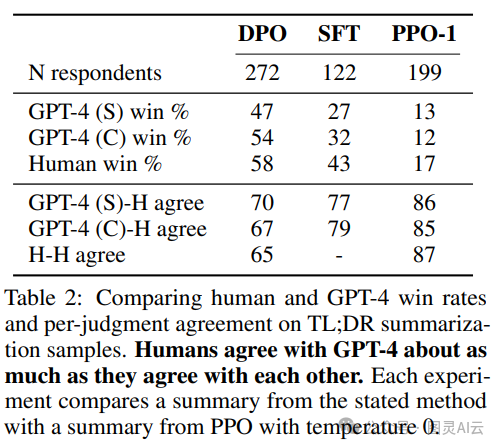
直接偏好优化(DPO)的性能表现真是让人眼前一亮。最近的研究对比了几种不同的训练技术,包括DPO、监督式微调(SFT)和近端策略优化(PPO),来看看它们如何影响大型语言模型(LLM)的性能,尤其是像GPT-4这样的模型。
结果表明,在所有这些训练方法中,GPT-4的表现越来越贴近人类的偏好,特别是在做摘要任务的时候。这个表格里头的数据显示,GPT-4生成的内容和人类评审者的评价之间的一致性越来越高,说明这个模型现在能够制作出那些不仅符合人类期望,而且几乎和人类自己创作的内容一样自然的东西。
简单来说,就是GPT-4通过DPO这样的训练,学会了怎么更好地理解人类想要什么样的内容,并且在实际生成文本的时候,能够更准确地满足这些期望。这对于提高LLM的实用性和可靠性来说,是个巨大的进步。
案例研究和实际应用
DPO的实用性在很多真实世界的例子中都得到了证明,而且还有一些基于DPO的变体也挺有意思的:
-
迭代DPO:Snorkel团队在2023年开发了这个版本,它把拒绝采样和DPO结合起来,让训练数据的选择过程更加精细。通过多轮的偏好采样迭代,模型能够更好地泛化,不会过度拟合到那些嘈杂或者有偏见的数据上。
-
IPO(迭代偏好优化):Azar他们团队在2023年提出了这个概念,IPO在优化过程中加了个正则化项,这有助于防止过度拟合,因为这是偏好优化时常见的问题。这个改进让模型能够在遵循偏好和保持泛化能力之间找到平衡。
-
KTO(知识转移优化):Ethayarajh团队在2023年提出了这个更新的版本,KTO放弃了传统的二元偏好,转而专注于把知识从参考模型转移到策略模型上,这样可以让模型与人类的价值观更加平滑和一致地对齐。
-
跨领域多模态DPO:Xu等人在2024年的研究中,展示了DPO在不同模态——比如文本、图像和音频——上的应用。这证明了DPO在使模型与人类偏好对齐方面的多样性,并且适用于多种类型的数据。这项研究凸显了DPO在构建能够处理复杂多模态任务的全面AI系统方面的潜力。
这些案例和变体展示了DPO不仅在理论上很吸引人,而且在实际应用中也非常有价值。通过这些方法,我们可以训练出更智能、更符合人类期望的AI模型。
结语
直接偏好优化(DPO)真是个突破性的进展,它让语言模型能更好地和咱们人类的喜好对上号。这玩意儿简单、效率高,而且还特别有效,简直就是搞研究的和实际应用者的超级利器。
用上DPO,咱们就能打造出两种都牛气的语言模型:一种是能力超群的,另一种是和人类的价值观、意图紧密结合的。这样的模型,不仅聪明,还懂得咱们想要啥,能更好地服务于咱们的需求。

这篇关于LLM 直接偏好优化(DPO)的一些研究的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





