偏好专题

通过因子分析识别消费者偏好的潜在因素的案例
因子分析是一种统计方法,用于研究变量之间的潜在关系。它是一种降维技术,通过识别较少数量的因子(或称为维度、成分)来解释多个观测变量之间的相关性。这些因子是不可观测的潜在变量,它们被认为是原始变量的潜在原因。 因子分析的主要步骤包括: 数据收集:收集相关变量的数据,这些变量之间可能存在某种程度的相关性。 数据标准化:由于原始数据可能具有不同的量纲和数值范围,通常需要对数据进行标准化处理。

LLM 直接偏好优化(DPO)的一些研究
今天我们来聊聊大型语言模型(LLMs)吧。要让这些聪明的家伙和咱们人类的价值观还有喜好对上号,这事儿可不简单。以前咱们用的方法,比如基于人类反馈的强化学习(RLHF),虽然管用,但是它太复杂了,得用上好多计算资源和数据处理的力气。现在,直接偏好优化(Direct Preference Optimization, DPO)来了,它就像是一股清流,给咱们提供了一个既简单又高效的新选择。DPO简化了优化

基于偏好启发的权重共生进化算法
论文信息 原始英文题目:Preference-inspired co-evolutionary algorithms using weight vectors 英文关键词:Evolutionary algorithms, Multi-objective optimisation, Many-objective, Co-evolution, Weights 中文题目:基于偏好启发的权重共生进化算法

深入NSUserDefaults:Objective-C中的用户偏好存储
标题:深入NSUserDefaults:Objective-C中的用户偏好存储 在Objective-C中,NSUserDefaults是一个用于存储用户偏好和应用设置的类。它提供了一种简单的方式来保存和检索用户的配置信息,如界面布局、最近使用的文件列表等。本文将详细探讨NSUserDefaults的使用方法、如何安全地存储和检索数据,并通过代码示例来展示其在实际编程中的应用。 1. NSUs

【报告分享】90后新消费者的茶饮口味喜好及消费偏好(附下载)
今天给大家分享的是商派:90后新消费者的茶饮口味喜好及消费偏好 90后新消费者的茶饮口味喜好及消费偏好 以下是关于本篇报告的部分内容,由于篇幅有限,若需获取原报告(PDF)及更多报告,可关注“行业报告智库”,在菜单栏处获取报告 关于行业报告智库 圈子从事收集行业报告多年,希望通过收集和整理报告帮助有需要的人更快更精准了解最新各行业各领域动态,目前已收集报
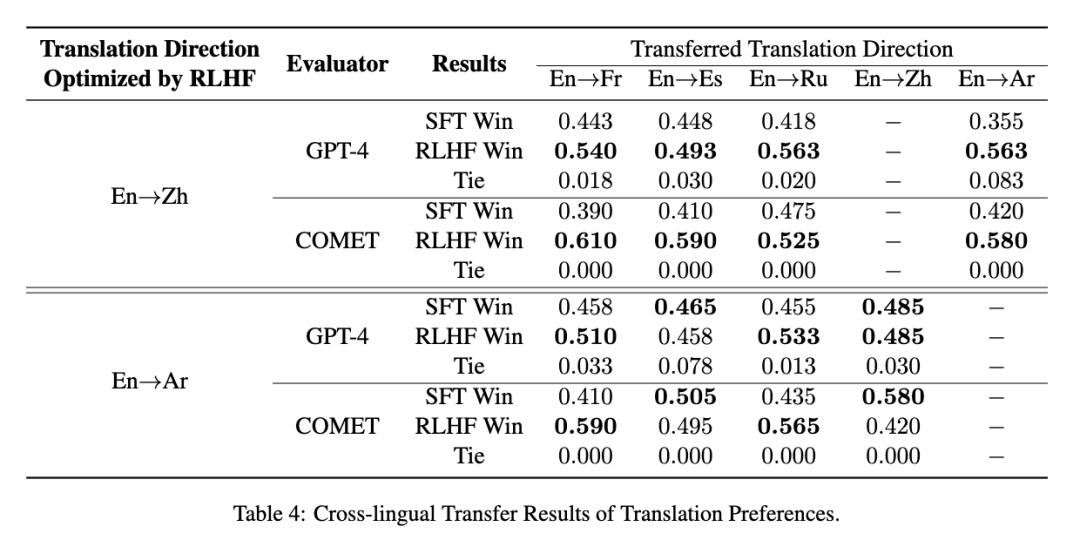
使用RLHF推动翻译偏好建模:低成本实现“信达雅”
在机器翻译领域,“忠实度(信)”、“表现力(达)”、“优雅性(雅)”一直是研究者们不懈追求的目标。然而,传统的评估指标如BLEU并不能完全符合人类对翻译质量的偏好。为了解决这一挑战,复旦大学自然语言处理实验室与复旦大学外文学院携手合作,共同探索了利用基于人类反馈的强化学习(RLHF)来提升翻译质量的可能途径。 我们提出一种代价高效的偏好学习策略,只需少量专业翻译即可让模型对齐人类的“信、达、雅”

使用 Jetpack Compose 实现 Android 偏好设置分类界面
使用 Jetpack Compose 实现 Android 偏好设置分类界面 Jetpack Compose 提供了一种现代且声明式的构建 Android 用户界面的方法,使其非常适合实现偏好设置分类界面。以下是如何实现的逐步指南: 1. 定义数据模型: 首先,定义数据模型来表示您的应用程序的偏好设置类别和偏好设置。创建名为 PreferenceCategory 和 Preferenc

短视频用户偏好:成都科成博通文化传媒公司
短视频用户偏好:揭秘当代观众的心头好 在数字时代,短视频以其短小精悍、内容丰富的特点,迅速占领了用户的碎片化时间。然而,随着短视频平台的不断涌现和内容的日益丰富,用户对于短视频的偏好也在悄然发生变化。成都科成博通文化传媒公司将深入探讨当代短视频用户的偏好,以及这些偏好背后的原因。 一、娱乐与消遣:短视频的初衷 短视频最初以娱乐和消遣为主要目的,满足了用户在快节奏生活中寻找轻松、
【用户画像】用户偏好购物模型BP
一、前言 用户购物偏好模型BP(Buyer Preferences Model)旨在通过对用户购物行为的深入分析和建模,以量化用户对不同商品或服务的偏好程度。该模型对于电商平台、零售商以及其他涉及消费者决策的商业实体来说,具有重要的应用价值。 二、推荐系统 概述 推荐系统是一种利用电子商务网站、社交媒体平台等向用户提供个性化商品、内容或服务建议的系统。它通过分析用户的行为、兴趣、历
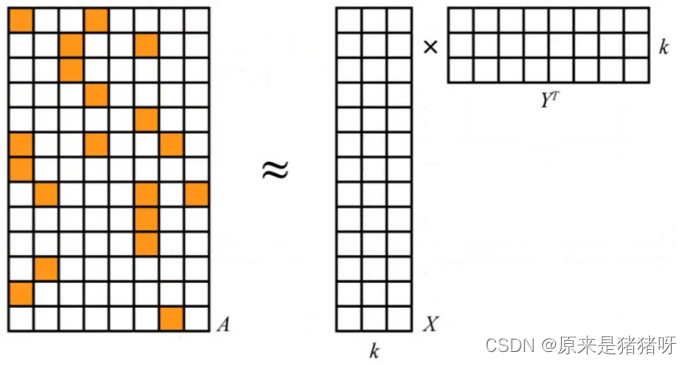
番外篇-用户购物偏好标签BP-推荐算法ALS
引言 推荐系统式信息过载所采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品。 推荐系统是自动化的通过分析用户对历史行为数据,完成用户的个性化建模,从而主动给用户推荐能够满足他们兴趣和需求的软件系统。 数据仓库(Data Warehouse) -> 用户画像(User Profile) -> 推荐系统(Recommend System) 用户购物偏好模型:依据用户浏览行为
偏好设置 SharedPreferences
对于Android 的存储方式一般用到的是五种: 1 .使用偏好设置 SharePreferences 来保存键值对的数据 2. 流文件存储 3.使用ContentProcider存储数据 4.网络存储数据 5.数据库保存结构化数据 下面是对SharePreferences的存储方式的使用 1. 使用Context.getSharedPreferences
sharepreference(偏好参数保存)
sharepreference专门用于保存用户的偏好设置参数,它是一个轻量级的存储类,特别适合用于保存软件配置参数 SharedPreferences保存数据其背后是用xml文件存放数据,文件存放在/data/data/<package name>/shared_prefs/xxx.xml目录下 布局: <LinearLayout xmlns:android="http://
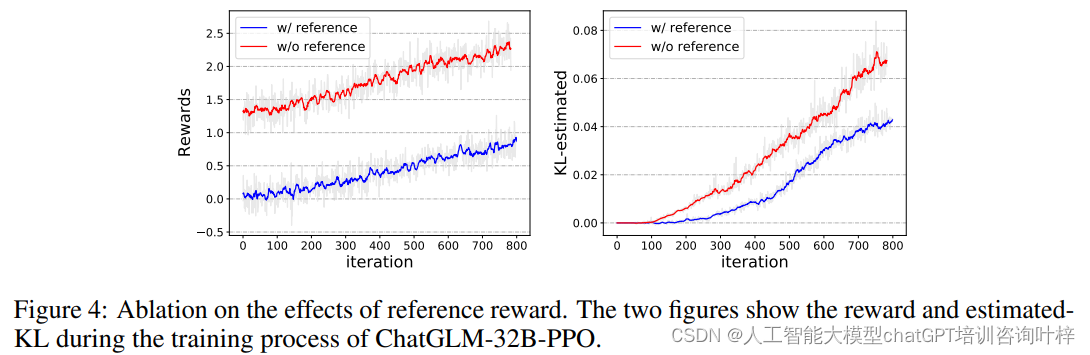
清华团队推出免费AI服务:与人类偏好对齐的大型语言模型
在人工智能领域,大型语言模型(LLMs)的迅猛发展极大地推动了机器在语言理解和生成方面的能力。然而,如何让这些模型更好地与人类偏好和价值观对齐,成为了一个重要而紧迫的课题。为此清华团队推出一项免费服务ChatGLM-RLHF,一个基于人类反馈的强化学习系统,旨在解决大型语言模型(LLMs)与人类偏好对齐的问题。该系统通过收集人类对模型生成文本的偏好反馈,训练一个奖励模型来评估响应质量,并以此指导策
沙盒路径下存储和读取数据 缓存文件、偏好设置文件、plist文件
1、plist存储 // 获取应用文件夹路径 NSString *homePath = NSHomeDirectory(); //获取document文件夹的路径 //函数的作用:在某个范围内搜索一个文件夹的路径 //directory:获取哪个文件夹 //NSUserDomainMask:在用户的范围内查找 //expandTilde:YES:展开 。N
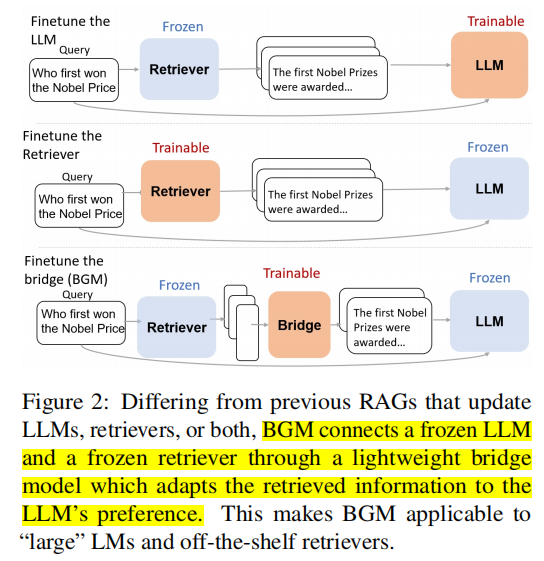
【RAG 论文】BGM:为 LLM 和 Retriever 的偏好 gap 搭建一个 Bridge
论文:Bridging the Preference Gap between Retrievers and LLMs ⭐⭐⭐ Google Research, arXiv:2401.06954 论文速读 LLM 与 Retriever 之间存在一个 preference gap:大多数 retriever 被设计为 human-friendly,但是 LLM 的偏好与人类的却不一致:

mac改成类似微软键盘偏好设置
以前我做过笔记,但是好像印象还不是很深刻,因为我自己还是忘记了, 我又写了一篇 首先是蛋疼的切换输入法问题,中文输入法和英文输入法的问题真不习惯。 切换输入法改正方法 进入系统偏好设置-键盘-快捷键-输入法-选择上一个输入法,勾选,发现右边 ^空格键,也就是 window的c t r l+空格键了, 双击可以进行修改,这样切换中文英文久方便了,我这篇文章就是用mac系统写的,有点蛋疼,切换大小写

复旦发布层次性奖励学习框架,增强大模型人类偏好对齐
在人工智能领域,强化学习(Reinforcement Learning, RL)一直是实现智能体自主学习的关键技术之一。通过与环境的交互,智能体能够自我优化其行为策略,以获得更多的奖励。然而,当涉及到复杂的人类偏好时,传统的强化学习方法面临着挑战。这些挑战主要源于人类监督信号的不一致性和稀疏性,这使得智能体难以准确地对齐人类的期望。 为了解决这一问题,研究者们提出了从人类反馈中学习的强化学习(R

JAVA实战开源项目:音乐偏好度推荐系统(Vue+SpringBoot)
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、系统设计2.1 功能模块设计2.1.1 音乐档案模块2.1.2 我的喜好模块2.1.3 每日推荐模块2.1.4 通知公告模块 2.2 用例图设计2.3 实体类设计2.4 数据库设计 三、系统展示3.1 登录注册3.2 音乐档案模块3.3 音乐每日推荐模块3.4 通知公告模块3.5 系统基础模块 四、样例代码4.1 修改单条歌曲喜爱配置4

Nara模仿神经元网络设计推荐算法,根据人的偏好与品味推荐餐馆
骁骑 • 1小时前 Nara模仿神经元网络设计推荐算法,根据人的偏好与品味推荐餐馆 我们可以模仿神经元的运作方式去设计算法,MIT 的几位科学家建立团队把这套原理应用到商业中去,建立了初创公司Nara。 Nara 正是基于神经元的网络结构设计了一套推荐算法,根据人们的偏好与品味去推荐餐馆。现在,北美已经有一百多万家餐馆纳入了 Nara 的神经元网络。而且,像人的大脑一样,Nar

微调实操四:直接偏好优化方法-DPO
在《微调实操三:人类反馈对语言模型进行强化学习(RLHF)》中提到过第三阶段有2个方法,一种是是RLHF, 另外一种就是今天的DPO方法, DPO通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好,DPO相较于RLHF更容易实现且易于训练,效果更好. 1、DPO VS RLHF DPO 是一种自动微调方法,它通过最大化预训练模型在特定任务上的奖

旅行前要查一堆攻略太麻烦?“智游啦”想根据个人偏好标签,帮用户在移动端上快速规划出游线路
旅行前要查一堆攻略太麻烦?“智游啦”想根据个人偏好标签,帮用户在移动端上快速规划出游线路 做行程规划这事,从 PC 到移动端上,不能再像以前那么麻烦了。尤其是在五一、端午小长假来临之前,可能很多人都还被工作压榨,几乎没有充分时间来查一堆攻略,再依据大量信息做出出行决策。所以“智游啦”(iOS)就想针对这样的用户场景,帮用户在几分钟内规划好出行行程。 比如想去厦门,智游啦会先
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)。 MedicalGPT: Training Your Own Medical GPT Model with ChatGPT Training Pipeline. 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化
Session适用于Web应用程序,Token适用于API认证,而Cookie适用于维护用户状态和存储用户偏好等信息。
目录 Session适用于Web应用程序,Token适用于API认证,而Cookie适用于维护用户状态和存储用户偏好等信息。服务器会生成 session id 、token、 cookie Session适用于Web应用程序,Token适用于API认证,而Cookie适用于维护用户状态和存储用户偏好等信息。 当用户在Web应用程序中进行登录时,服务器会创建一个唯一的Session
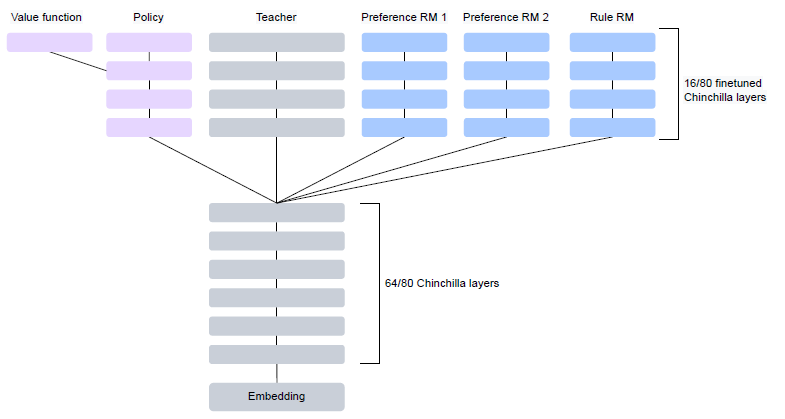
偏好对齐RLHF-OpenAI·DeepMind·Anthropic对比分析
OpenAI paper: InstructGPT, Training language models to follow instructions with human feedback paper: Learning to summarize from human feedback Introducing ChatGPT 解密Prompt系列4介绍了InstructGPT指令

开箱即用的企业级数据和业务管理中后台前端框架Ant Design Pro 5的开箱使用和偏好配置
Ant Design Pro 介绍 Ant Design Pro 是一个开箱即用的企业级前端解决方案,基于 Ant Design 设计体系,提供了丰富的组件和功能,帮助开发者更快速地开发和部署企业级应用。 Ant Design Pro 使用 React、umi 和 dva 这三个主要的前端开发技术栈,通过脚手架工具创建项目,并提供了一系列的模板和示例代码,方便开发者快速上手。 Ant Des