本文主要是介绍【RAG 论文】BGM:为 LLM 和 Retriever 的偏好 gap 搭建一个 Bridge,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文:Bridging the Preference Gap between Retrievers and LLMs
⭐⭐⭐
Google Research, arXiv:2401.06954
论文速读
LLM 与 Retriever 之间存在一个 preference gap:大多数 retriever 被设计为 human-friendly,但是 LLM 的偏好与人类的却不一致:
- ranking 方面:由于 LLM 的 self-attention 机制,模型可以集中任何 token 而无视其 position。但人类对于 position 还是很关注的。
- selection 方面:人类可以轻易地忽视掉与上下文无关的信息,但 LLM 却对于无关内容特别敏感。
- repetition 方面:人类往往不关心重复内容,甚至不喜欢重复内容,但是 repetition 却在对于 LLM 在衡量相关性的权重时很有帮助。
论文原文设计了一些实验来证明 preference gap 确实存在,具体可以参考原论文。
为了弥补 LLM 和 Retriever 之间的 preference gap,过去的研究工作往往是集中于对 LLM 或 Retriever 进行微调,但其实无论是 LLM 还是 Retriever 都很可能是无法微调的。
比如对于生产级的 Retriever,如 Google 或 Bing,都是不能被微调的。
本论文提出了 BGM(Bridging the Gap between retrievers and LLMs)框架来解决这个问题:它在 LLM 和 Retriever 之间额外添加了一个 seq2seq 的 Bridge 模型,这个 Bridge 模型的输入是 retrieved passages,输出是 LLM-friendly passages。(如下图的最三个模型)
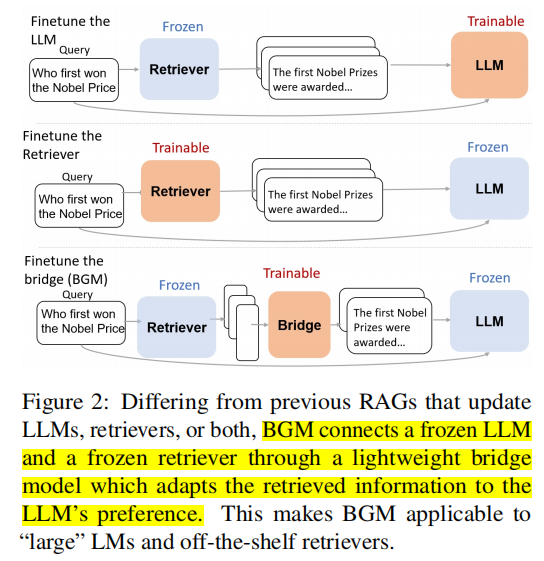
这里的 Bridge 模型是可以训练的,训练过程分成了两个阶段:监督学习(SL)阶段和强化学习(RL)阶段。
Bridge 模型的训练
阶段 1:SL 阶段
首先是 Supervised Learning(SL)阶段。
SL 学习往往需要 golden passage sequence 作为每个 query 的 label 从而实现监督学习,但是 golden passage sequence 是一种理想的情况,由于实际应用中不存在这样的真是标签,且对于一个 query,有太多有效的段落组合方式,从中选出最理想的答案在计算上是不可行的。
于是本文使用 sliver passage sequence(SPS)作为训练标签,也就是次优的标签。因此我们首先需要合成出用于 SL 的 SPS 数据。
SPS 数据的合成关键是用了贪心搜索的思想,通过迭代,最开始的段落序列是一个 empty sequence,之后逐步添加能够提升 downstream task 表现的最佳 passage,并将其加入到 SPS 中,直到无法进一步改善性能为止。
sliver passage sequence 用于监督学习阶段,作为训练目标,帮助桥接模型学习如何从检索到的段落中选择和排序,以生成对 downstream task 最有帮助的段落序列。
阶段 2:RL 阶段
实验发现,只使用 SL 来训练 Bridge model 是不够的,SL only 的模型最终的表现并不好,原因可能就是稀疏的 supervision 以及缺少在 downstream results 上的 end-to-end training。
为了解决这些问题,论文进一步对 SL 训练后的 Bridge Model 做进一步的强化学习,RL 可以让 Bridge model 学习到 optimal passage sequence 所需要的更加复杂的操作(比如 repetition)。
RL 的使用方法是:
- downstream task 的 performance 被用来设计 reward。比如 QA 任务中的 BLEU 分数。
- bridge model 就是需要训练的 policy model。
- action space 定义了模型可以采取的所有可能动作,在这篇论文中,action space 可能包括选择哪些 passages、它们的顺序、以及是否需要重复某些 passage 等。
- Environment 就是由 Retriever、Bridge Model、LLM 组成的整体。
训练阶段的优化算法可以是任何 off-the-shelf RL 算法,论文提到了使用 PPO 作为优化算法。
总结
本论文提出的问题是现实存在的:LLM 和 Retriever 往往都是 Frozen 的,都是无法微调的,但两者之间的 preference gap 又是明显存在的。
本文提出引入一个 Bridge Model 来填补这个 gap,但是本文提出的训练方法有点太复杂了,也许有进一步简化的思路。
这篇关于【RAG 论文】BGM:为 LLM 和 Retriever 的偏好 gap 搭建一个 Bridge的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









