本文主要是介绍番外篇-用户购物偏好标签BP-推荐算法ALS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
推荐系统式信息过载所采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品。
推荐系统是自动化的通过分析用户对历史行为数据,完成用户的个性化建模,从而主动给用户推荐能够满足他们兴趣和需求的软件系统。
数据仓库(Data Warehouse) -> 用户画像(User Profile) -> 推荐系统(Recommend System)
用户购物偏好模型:依据用户浏览行为日志数据,给用户推荐可能感兴趣的商品。
- 数据集:tbl_logs 表数据
- 推荐商品:Top5商品
- 解决方案:协同过滤推荐算法ALS
推荐系统概述
推荐系统是信息过载所采用的措施,面对海量的数据信息,从中快速的推荐出符合用户特点的物品。
推荐系统是自动化的通过分析用户的历史行为数据,完成用户的个性化建模,从而主动给用户推荐能够满足他们兴趣和需求的信息的软件系统。

推荐引擎需要依赖用户的行为日志,因此一般都作为一个后台应用程序存在于网站中。通过截取网站提供了大量用户行为日志,给用户提供不同的个性化页面或者信息,提高整个网站的点击率和转化率。

推荐系统一般都由三个部分组成,前端的交互界面、日志系统以及推荐算法系统。
个性化推荐的成功需要两个条件:
- 存在信息过载,用户不能很容易从所有物品中找到喜欢的物品
- 用户大部分时候没有明确的需求
一个完整的推荐系统一般存在3个参与方:用户、内容提供者和提供推荐系统的网站。
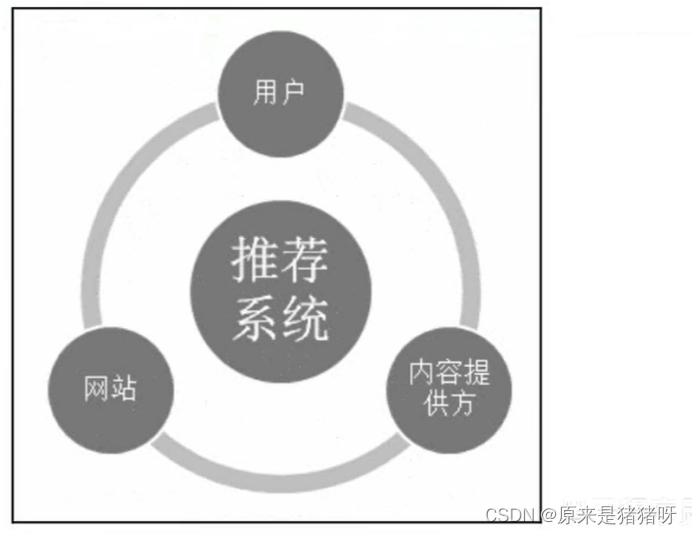
比如一个图书推荐系统:
- 推荐系统需要满足用户的需求,能给用户推荐那些令他们感兴趣的图书。
- 推荐系统要让各出版社的书都能够推荐给对其感兴趣的用户,恶如是只推荐几个大型出版社的书。
- 推荐系统应该能够收集到高质量的用户反馈,不断完善推荐的质量,增加用户和网站的交互,提高网站的收入。
好的推荐系统是一个能够让三分共赢的系统。
好的推荐系统不仅仅能够准确预测用户的行为,而且能够扩展用户的视野,帮助用户去“发现”更多自己可能感兴趣的事务。
·让用户更快更好的获取到自己需要的内容
·让内容更快更好的推送到喜欢他的用户手中
·让网站(平台)更有效的保留用户资源
推荐系统的基本思想
利用用户和物品的特征信息,给用户推荐那些具有用户喜欢的特征的物品。
利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品。
利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品。
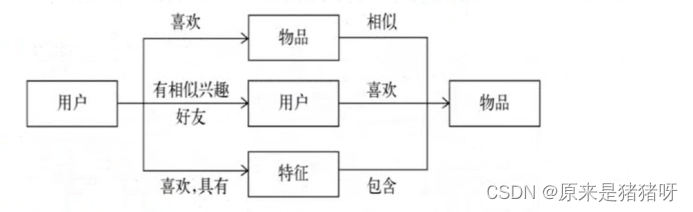
即:
知你所想,精准推送
利用用户和物品的特征信息,给用户推荐那些具有用户喜欢的特征和物品。
物以类聚
利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品。
人以群分
利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品。
推荐系统数据分析
推荐系统主要根据用户数据、物品数据以及用户对物品行为数据(评分数据、点击数据、购物数据等)
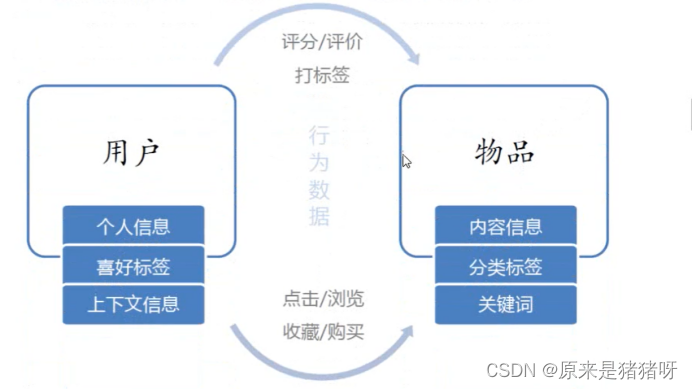
不同数据说明如下:
其一:要推荐物品或者内容的元数据
例如关键字、分类标签、基因描述等
其二:系统用户的基本信息
例如性别、年龄、兴趣标签等
其三:用户的行为数据,可以转换为对物品或信息的偏好
根据应用本身的不同,可以包括用户对物品的评分,用户查看物品的基类,用户购买的记录等
用户的偏好信息可以分为两类:
显示的用户反馈:这类是用户在网站上自然浏览或者使用网站意外,显示的提供反馈信息,例如用户对物品的评分,或者对物品的评论。
隐式的用户反馈:这类型用户在使用网站时产生的数据,隐式的反映了用户对物品的喜好,例如用户购买了某物品,用户查看了某物品的信息等等。
推荐系统分类
针对推荐系统来说,最重要的就是数据:用户数据、物品数据以及用户对物品行为数据(评分数据、点击数据、购物数据等),按照不同类型业务或实现,划分推荐系统为如下几个类型
协同过滤
如果推荐系统仅仅利用用户的行为数据,根据用户对历史兴趣来给用户做推荐
——如果用户能够找到和自己历史兴趣相似的一群用户,看看他们最近在看什么电影,那么结果可能比宽泛的热门排行榜更能符合自己的兴趣
·数据:用户对物品的评价,评价时最为关键
·使用此算法时,如何获取用户对物品的评价(显示评价与隐式评价)
基于内容推荐
如果推荐系统利用了物品的内容数据,计算用户的兴趣和物品描述之间的相似度,来给用户做推荐
——通过分析用户曾经看过的电影找到用户喜欢的演员或导演,然后给用户推荐这些演员或导演的其他电影
·某个用户浏览、点击、购买某个物品,再次浏览的时候,将会把相似的物品进行推荐
·物品相似度比较高
·啤酒与尿布的故事,购买某个物品时,通常也会购买什么别的商品
·依据用户购物数据(订单数据)
社会化推荐
如果推荐系统利用了用户之间的社会网络信息,利用用户在社会网络中的好友的兴趣来给用户做推荐。
——让好友给自己推荐物品
ALS算法
推荐算法中的ALS是指Alternating Least Squares(交替最小二乘法)算法。这是一种协同过滤推荐算法,主要用于解决推荐系统中的矩阵降维。
ALS算法的核心思想:将用户-物品评分矩阵分解为两个低维矩阵的乘积,即将用户-物品的关联关系表示为用户和物品的特征向量表示。具体而言,首先初始化一个因子矩阵,使用评分矩阵获取另外的因子矩阵,交替计算,直到满足终止条件(最大迭代次数 or 收敛条件),此时就可以得到两个因子矩阵,即模型Model。ALS算法构建模型最本质就是两个因子矩阵。
Spark MLlib的推荐模型库只包含基于矩阵分解模型:
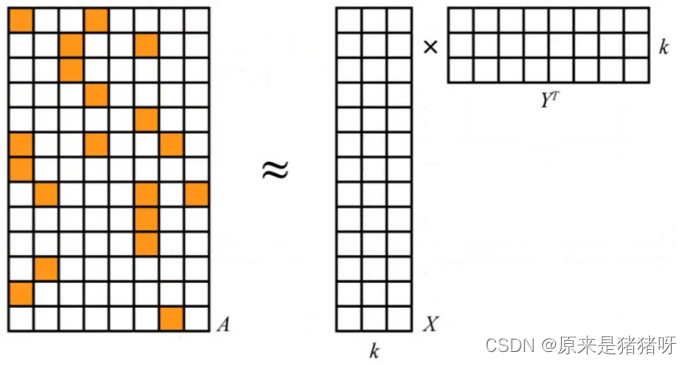
- 数学上,算法把User和Item数据当作一个大矩阵A,矩阵第i行和第j列上的元素有值,代表User-i对应Item-j的值
- 矩阵a是系数的:A中大多数元素都是0,因为相对于所有可能的用户-物品组合,只有很少一部分组合会出现在数据中
- 算法将A分解为两个小矩阵X和Y的乘积
矩阵X和矩阵Y非常小,因为A有很多行与列,但X和Y的行有很多而列很少(列数用k来标识)。这k个列就是潜在元素,用来解释数据中的交互关系。
K:矩阵因子,秩
矩阵分解
大致分为以下几个步骤:
Step1:初始化因子矩阵(随机)
Step2:依据大评价矩阵和初始化因子矩阵,计算出另外一个因子矩阵
Step3:再依据大评价矩阵和刚刚计算出来的因子矩阵,计算出另外一个因子矩阵。
Step4:重复2和3,直到满足收敛条件或达到次数为止
……
这里在之前进行知识点补充的时候已经详细的讲过了,想了解原理的xdm可以去看看之前我写的这篇文章->对ALS算法自己的理解,谢谢大家的支持!
样例代码实现(基于RDD实现)
import org.apache.spark.mllib.evaluation.RegressionMetrics
import org.apache.spark.mllib.recommendation._
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}/*** 使用MovieLens 电影评分数据集,调用Spark MLlib 中协同过滤推荐算法ALS建立推荐模型:* -a. 预测 用户User 对 某个电影Product 评价* -b. 为某个用户推荐10个电影Products* -c. 为某个电影推荐10个用户Users*/
object SparkAlsRmdMovie {def main(args: Array[String]): Unit = {// TODO: 1. 构建SparkContext实例对象val sc: SparkContext = {// a. 创建SparkConf对象,设置应用相关配置val sparkConf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName.stripSuffix("$"))// b. 创建SparkContextval context = SparkContext.getOrCreate(sparkConf)// 设置检查点目录context.setCheckpointDir(s"datas/ckpt/als-ml-${System.nanoTime()}")// c. 返回context}// TODO: 2. 读取 电影评分数据val rawRatingsRDD: RDD[String] = sc.textFile("datas/als/ml-100k/u.data")println(s"Count = ${rawRatingsRDD.count()}")println(s"First: ${rawRatingsRDD.first()}")// TODO: 3. 数据转换,构建RDD[Rating]val ratingsRDD: RDD[Rating] = rawRatingsRDD// 过滤不合格的数据.filter(line => null != line && line.split("\\t").length == 4).map{line =>// 字符串分割val Array(userId, movieId, rating, _) = line.split("\\t")// 返回Rating实例对象Rating(userId.toInt, movieId.toInt, rating.toDouble)}// 划分数据集为训练数据集和测试数据集val Array(trainRatings, testRatings) = ratingsRDD.randomSplit(Array(0.9, 0.1))// TODO: 4. 调用ALS算法中显示训练函数训练模型// 迭代次数为20,特征数为10val alsModel: MatrixFactorizationModel = ALS.train(ratings = trainRatings, // 训练数据集rank = 10, // 特征数rankiterations = 20 // 迭代次数)// TODO: 5. 获取模型中两个因子矩阵/*** 获取模型MatrixFactorizationModel就是里面包含两个矩阵:* -a. 用户因子矩阵* alsModel.userFeatures* -b. 产品因子矩阵* alsModel.productFeatures*/// userId -> Featuresval userFeatures: RDD[(Int, Array[Double])] = alsModel.userFeaturesuserFeatures.take(10).foreach{tuple =>println(tuple._1 + " -> " + tuple._2.mkString(","))}println("=======================================================")// productId -> Featuresval productFeatures: RDD[(Int, Array[Double])] = alsModel.productFeaturesproductFeatures.take(10).foreach{tuple => println(tuple._1 + " -> " + tuple._2.mkString(","))}// TODO: 6. 模型评估,使用RMSE评估模型,值越小,误差越小,模型越好// 6.1 转换测试数据集格式RDD[((userId, ProductId), rating)]val actualRatingsRDD: RDD[((Int, Int), Double)] = testRatings.map{tuple =>((tuple.user, tuple.product), tuple.rating)}// 6.2 使用模型对测试数据集预测电影评分val predictRatingsRDD: RDD[((Int, Int), Double)] = alsModel// 依据UserId和ProductId预测评分.predict(actualRatingsRDD.map(_._1))// 转换数据格式RDD[((userId, ProductId), rating)].map(tuple => ((tuple.user, tuple.product), tuple.rating))// 6.3 合并预测值与真实值val predictAndActualRatingsRDD: RDD[((Int, Int), (Double, Double))] = predictRatingsRDD.join(actualRatingsRDD)// 6.4 模型评估,计算RMSE值val metrics = new RegressionMetrics(predictAndActualRatingsRDD.map(_._2))println(s"RMSE = ${metrics.rootMeanSquaredError}")// TODO 7. 推荐与预测评分// 7.1 预测某个用户对某个产品的评分 def predict(user: Int, product: Int): Doubleval predictRating: Double = alsModel.predict(196, 242)println(s"预测用户196对电影242的评分:$predictRating")println("----------------------------------------")// 7.2 为某个用户推荐十部电影 def recommendProducts(user: Int, num: Int): Array[Rating]val rmdMovies: Array[Rating] = alsModel.recommendProducts(196, 10)rmdMovies.foreach(println)println("----------------------------------------")// 7.3 为某个电影推荐10个用户 def recommendUsers(product: Int, num: Int): Array[Rating]val rmdUsers = alsModel.recommendUsers(242, 10)rmdUsers.foreach(println)// TODO: 8. 将训练得到的模型进行保存,以便后期加载使用进行推荐val modelPath = s"datas/als/ml-als-model-" + System.nanoTime()alsModel.save(sc, modelPath)// TODO: 9. 从文件系统中记载保存的模型,用于推荐预测val loadAlsModel: MatrixFactorizationModel = MatrixFactorizationModel.load(sc, modelPath)// 使用加载预测val loaPredictRating: Double = loadAlsModel.predict(196, 242)println(s"加载模型 -> 预测用户196对电影242的评分:$loaPredictRating")// 为了WEB UI监控,线程休眠Thread.sleep(10000000)// 关闭资源sc.stop()}}样例代码实现(基于DF实现)
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.{ALS, ALSModel}
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType, StructField, StructType}/*** 基于DataFrame实现ALS算法库使用,构建训练电影推荐模型*/
object SparkRmdAls {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName(this.getClass.getSimpleName.stripSuffix("$")).master("local[4]").config("spark.sql.shuffle.partitions", "4").getOrCreate()import org.apache.spark.sql.functions._import spark.implicits._// 自定义Schame信息val mlSchema = StructType(Array(StructField("userId", IntegerType, nullable = true),StructField("movieId", IntegerType, nullable = true),StructField("rating", DoubleType, nullable = true),StructField("timestamp", LongType, nullable = true)))// TODO: 读取电影评分数据,数据格式为TSV格式val rawRatingsDF: DataFrame = spark.read.option("sep", "\t").schema(mlSchema).csv("datas/als/ml-100k/u.data")//rawRatingsDF.printSchema()/*** root* |-- userId: integer (nullable = true)* |-- movieId: integer (nullable = true)* |-- rating: double (nullable = true)* |-- timestamp: long (nullable = true)*///rawRatingsDF.show(10, truncate = false)// TODO: ALS 算法实例对象val als = new ALS() // def this() = this(Identifiable.randomUID("als"))// 设置迭代的最大次数.setMaxIter(10)// 设置特征数.setRank(10)// 显式评分.setImplicitPrefs(false)// 设置Block的数目, be partitioned into in order to parallelize computation (默认值: 10)..setNumItemBlocks(4).setNumUserBlocks(4)// 设置 用户ID:列名、产品ID:列名及评分:列名.setUserCol("userId").setItemCol("movieId").setRatingCol("rating")// TODO: 使用数据训练模型val mlAlsModel: ALSModel = als.fit(rawRatingsDF)// TODO: 用户-特征 因子矩阵val userFeaturesDF: DataFrame = mlAlsModel.userFactorsuserFeaturesDF.show(5, truncate = false)// TODO: 产品-特征 因子矩阵val itemFeaturesDF: DataFrame = mlAlsModel.itemFactorsitemFeaturesDF.show(5, truncate = false)/*** 推荐模型:* 1、预测用户对物品评价,喜好* 2、为用户推荐物品(推荐电影)* 3、为物品推荐用户(推荐用户)*/// TODO: 预测 用户对产品(电影)评分val predictRatingsDF: DataFrame = mlAlsModel// 设置 用户ID:列名、产品ID:列名.setUserCol("userId").setItemCol("movieId").setPredictionCol("predictRating") // 默认列名为 prediction.transform(rawRatingsDF)predictRatingsDF.show(5, truncate = false)/*TODO:实际项目中,构建出推荐模型以后,获取给用户推荐商品或者给物品推荐用户,往往存储至NoSQL数据库1、数据量表较大2、查询数据比较快可以是Redis内存数据,MongoDB文档数据,HBase面向列数据,存储Elasticsearch索引中*/// TODO: 为用户推荐10个产品(电影)// max number of recommendations for each userval userRecs: DataFrame = mlAlsModel.recommendForAllUsers(10)userRecs.show(5, truncate = false)// 查找 某个用户推荐的10个电影,比如用户:196 将结果保存Redis内存数据库,可以快速查询检索// TODO: 为产品(电影)推荐10个用户// max number of recommendations for each itemval movieRecs: DataFrame = mlAlsModel.recommendForAllItems(10)movieRecs.show(5, truncate = false)// 查找 某个电影推荐的10个用户,比如电影:242// TODO: 模型的评估val evaluator = new RegressionEvaluator().setLabelCol("rating").setPredictionCol("predictRating").setMetricName("rmse")val rmse = evaluator.evaluate(predictRatingsDF)println(s"Root-mean-square error = $rmse")// TODO: 模型的保存mlAlsModel.save("datas/als/mlalsModel")// TODO: 加载模型val loadMlAlsModel: ALSModel = ALSModel.load( "datas/als/mlalsModel")loadMlAlsModel.recommendForAllItems(10).show(5, truncate = false)// 应用结束,关闭资源Thread.sleep(1000000)spark.stop()}}
(叠甲:大部分资料来源于黑马程序员,这里只是做一些自己的认识、思路和理解,主要是为了分享经验,如果大家有不理解的部分可以私信我,也可以移步【黑马程序员_大数据实战之用户画像企业级项目】https://www.bilibili.com/video/BV1Mp4y1x7y7?p=201&vd_source=07930632bf702f026b5f12259522cb42,以上,大佬勿喷)
这篇关于番外篇-用户购物偏好标签BP-推荐算法ALS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





