本文主要是介绍微调实操四:直接偏好优化方法-DPO,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在《微调实操三:人类反馈对语言模型进行强化学习(RLHF)》中提到过第三阶段有2个方法,一种是是RLHF, 另外一种就是今天的DPO方法, DPO通过直接优化语言模型来实现对其行为的精确控制,而无需使用复杂的强化学习,也可以有效学习到人类偏好,DPO相较于RLHF更容易实现且易于训练,效果更好.
1、DPO VS RLHF
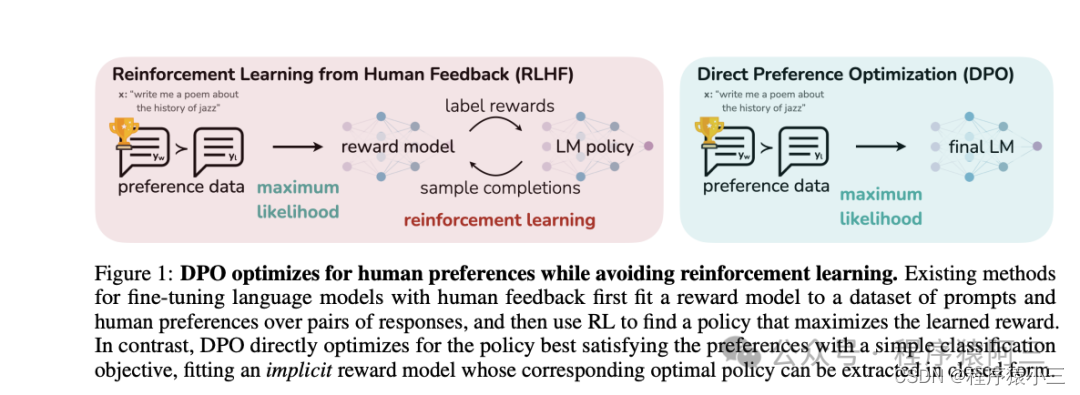
DPO 是一种自动微调方法,它通过最大化预训练模型在特定任务上的奖励来优化模型参数。与传统的微调方法相比,DPO 绕过了建模奖励函数这一步,而是通过直接在偏好数据上优化模型来提高性能。相对RLHF两阶段而言具有多项优越性:
(1)简单性:DPO更容易实施和培训,使其更易于使用。
(2)稳定性:不易陷入局部最优,保证训练过程更加可靠。
(3)效率:与RLHF 相比, DPO 需要更少的计算资源和数据,使其计算量轻。
(4)有效性:实验结果表明,DPO在情感控制、摘要和对话生成等任务中可以优于 RLHF 。
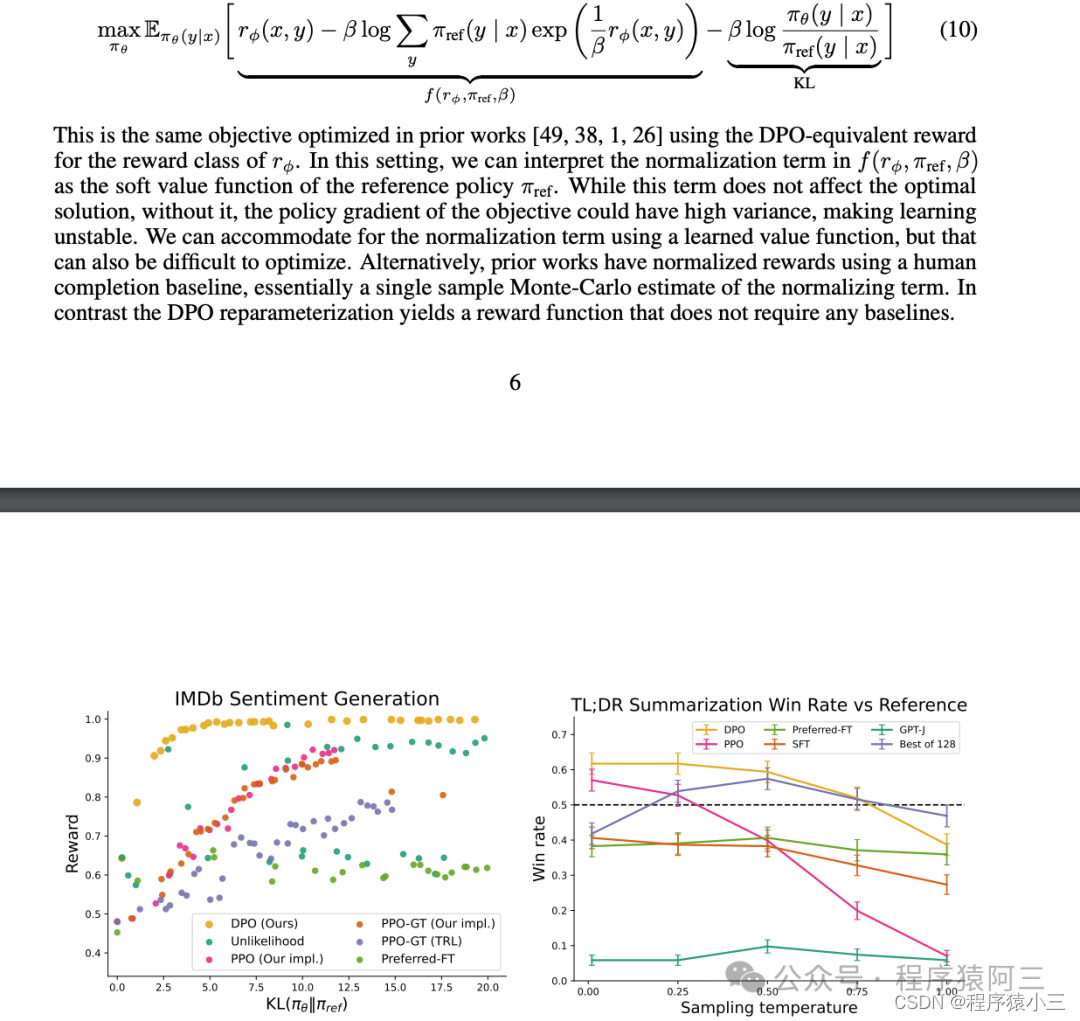
并不是说DPO没有奖励模型, 而是利用同个阶段训练建立模型和强化学习, 在 DPO 中,目标函数是优化模型参数以最大化奖励的函数。除了奖励最大化目标外,还需要添加一个相对于参考模型的 KL 惩罚项,以防止模型学习作弊或钻营奖励模型。
2、trl库
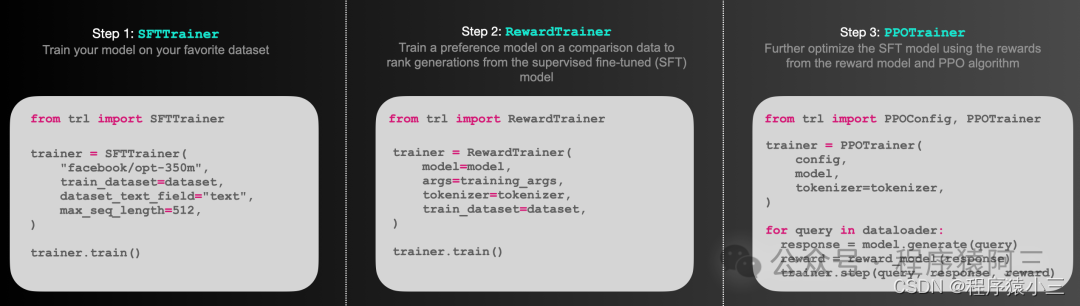
TRL(Transformer Reinforcement Learning)是一个全面的库,专为使用强化学习训练变换器语言模型而设计。它包含多种工具,可以支持从监督式微调(SFT)开始,通过奖励建模(RM)阶段,最终达到近端策略优化(PPO)阶段和DPO。此库 transformers框架无缝集成。所以未来在人工智能领域transformers必学.

3、实操
3.1 数据集

采用《微调实操三:人类反馈对语言模型进行强化学习(RLHF)》 阶段中训练奖励模型的数据集
3.2 合并指令微调的模型
!python /kaggle/working/MedicalGPT/merge_peft_adapter.py --model_type bloom \
--base_model merged-pt --lora_model outputs-sft-v1 --output_dir merged-sft/
3.3 DPO训练脚本
# dpo training
%cd /kaggle/working/autoorder
!ls
!git pull
!pip install -r algorithm/llm/requirements.txt
!pip install Logbook
import os
os.environ['RUN_PACKAGE'] = 'algorithm.llm.train.dpo_training'
os.environ['RUN_CLASS'] = 'DPOTraining'
print(os.getenv("RUN_PACKAGE"))
!python main.py \--model_type bloom \--model_name_or_path ./merged-sft \--train_file_dir /kaggle/working/MedicalGPT/data/reward \--validation_file_dir /kaggle/working/MedicalGPT/data/reward \--per_device_train_batch_size 3 \--per_device_eval_batch_size 1 \--do_train \--do_eval \--use_peft True \--max_train_samples 1000 \--max_eval_samples 10 \--max_steps 100 \--eval_steps 10 \--save_steps 50 \--max_source_length 128 \--max_target_length 128 \--output_dir outputs-dpo-v1 \--target_modules all \--lora_rank 8 \--lora_alpha 16 \--lora_dropout 0.05 \--torch_dtype float16 \--fp16 True \--device_map auto \--report_to tensorboard \--remove_unused_columns False \--gradient_checkpointing True \--cache_dir ./cache \--use_fast_tokenizer
这篇关于微调实操四:直接偏好优化方法-DPO的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





