本文主要是介绍RLHF的替代算法之DPO原理解析:从Zephyr的DPO到Claude的RAILF,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
本文的成就是一个点顺着一个点而来的,成文过程颇有意思
- 首先,如上文所说,我司正在做三大LLM项目,其中一个是论文审稿GPT第二版,在模型选型的时候,关注到了Mistral 7B(其背后的公司Mistral AI号称欧洲的OpenAI,当然 你权且一听,切勿过于当真)
- 而由Mistral 7B顺带关注到了基于其微调的Zephyr 7B,而一了解Zephyr 7B的论文,发现它还挺有意思的,即它和ChatGPT三阶段训练方式的不同在于:
在第二阶段训练奖励模型的时候,不是由人工去排序模型给出的多个答案,而是由AI比如GPT4去根据不同答案的好坏去排序
且在第三阶段的时候,用到了一个DPO的算法去迭代策略,而非ChatGPT本身用的PPO算法去迭代策略 - 考虑到ChatGPT三阶段训练方式我已经写得足够完整了(instructGPT论文有的细节我做了重点分析、解读,论文中没有的细节我更做了大量的扩展、深入、举例,具体可以参见《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》)
而有些朋友反馈到DPO比PPO好用(当然了,我也理解,毕竟PPO那套算法涉及到4个模型,一方面的策略的迭代,一方面是价值的迭代,理解透彻确实不容易) - 加之ChatGPT的最强竞品Claude也用到了一个RAILF的机制(和Zephyr 7B的AI奖励/DPO颇有异曲同工之妙),之前也曾想过写来着,但此前一直深究于ChatGPT背后的原理细节,现在也算有时间好好写一写了
综上,便拟定了本文的标题
第一部分 什么是DPO
今年5月份,斯坦福的一些研究者提出了RLHF的替代算法:直接偏好优化(Direct Preference Optimization,简称DPO),其对应论文为《Direct Preference Optimization: Your Language Model is Secretly a Reward Model》
那其与ChatGPT所用的RLHF有何本质区别呢,简言之
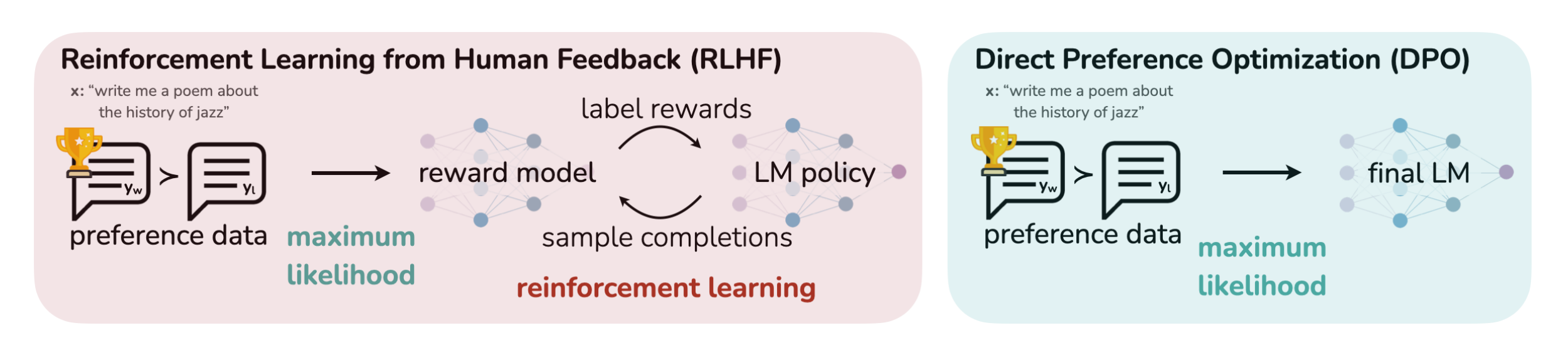
- RLHF将奖励模型拟合到人类偏好数据集上,然后使用RL方法比如PPO算法优化语言模型的策略,以输出可以获得高奖励的responses(同时不会偏离原始SFT模型太远)
RLHF methods fita reward model to a dataset of human preferences and then use RL to optimize a language model policy to produce responses assigned high reward without drifting excessively far from the original model.
虽然RLHF产生的模型具有令人印象深刻的会话和编码能力,但RLHF比监督学习复杂得多,其涉及训练多个LM和在训练循环中从LM策略中采样(4个模型,涉及到经验数据的采集,以及策略的迭代和价值的迭代,如果不太熟或忘了,请参见《ChatGPT技术原理解析》),从而产生大量的计算成本
While RLHF produces models with impressive conversational and coding abilities, the RLHFpipeline is considerably more complex than supervised learning, involving training multiple LMs andsampling from the LM policy in the loop of training, incurring significant computational costs. - 相比之下,DPO通过简单的分类目标直接优化最满足偏好的策略,而没有明确的奖励函数或RL
DPO directly optimizes for the policy best satisfying the preferences with a simple classification objective, without an explicit reward function or RL
更具体而言,DPO的本质在于
- 增加了被首选的response相对不被首选的response的对数概率,但它包含了一个动态的、每个示例的重要性权重,以防止我们发现的简单概率比目标发生的模型退化
与现有算法一样,DPO依赖于理论偏好模型,衡量给定的奖励函数与经验偏好数据的一致性
the DPO update increases the relative log probability of preferred to dispreferred responses, but it incorporates a dynamic, per-example importance weight that preventsthe model degeneration that we find occurs with a naive probability ratio objective
Like existingalgorithms, DPO relies on a the oretical preference model that measures how well a given reward function aligns with empirical preference data. - 然而,虽然现有方法比如ChatGPT通过定义偏好损失来训练奖励模型,然后在奖励模型的指引下训练策略,但DPO使用变量的变化来直接将偏好损失定义为策略的函数,给定人类对模型响应的偏好数据集,DPO因此可以使用简单的二元交叉熵目标优化策略,而无需在训练期间明确学习奖励函数或从策略中采样
However, while existing methods use the preference model to define a preference loss to train a reward model and then train a policy that optimizes the learned reward model, DPO uses a change of variables to definethe preference loss as a function of the policy directly. Given a dataset of human preferences overmodel responses, DPO can therefore optimize a policy using a simple binary cross entropy objective,without explicitly learning a reward function or sampling from the policy during training.
第二部分 Zephyr 7B的训练模式:从AI奖励到DPO
// 待更
第三部分 Claude的RAILF
// 待更
这篇关于RLHF的替代算法之DPO原理解析:从Zephyr的DPO到Claude的RAILF的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






