rlhf专题

RLHF PPO DPO
生成式大模型的RLHF技术(一):基础 DPO: Direct Preference Optimization 论文解读及代码实践 深入对比 DPO 和 RLHF 深入理解DPO(Direct Preference Optimization)算法

分意图 Prompt 调试、后置判别改写、RLHF 缓解大模型生成可控性
分意图 Prompt 调试、后置判别改写、RLHF 这三种方法是为了提高大模型生成内容的可控性,具体原因如下: 分意图 Prompt 调试: 通过针对不同的任务或意图设计特定的 Prompt,可以更精确地引导模型生成符合期望的内容。分意图 Prompt 调试的核心是将复杂的问题分解为更易于模型理解和处理的小问题,从而减少生成内容的偏差和不确定性。这种方法通过精细化控制 Prompt,能够在一定
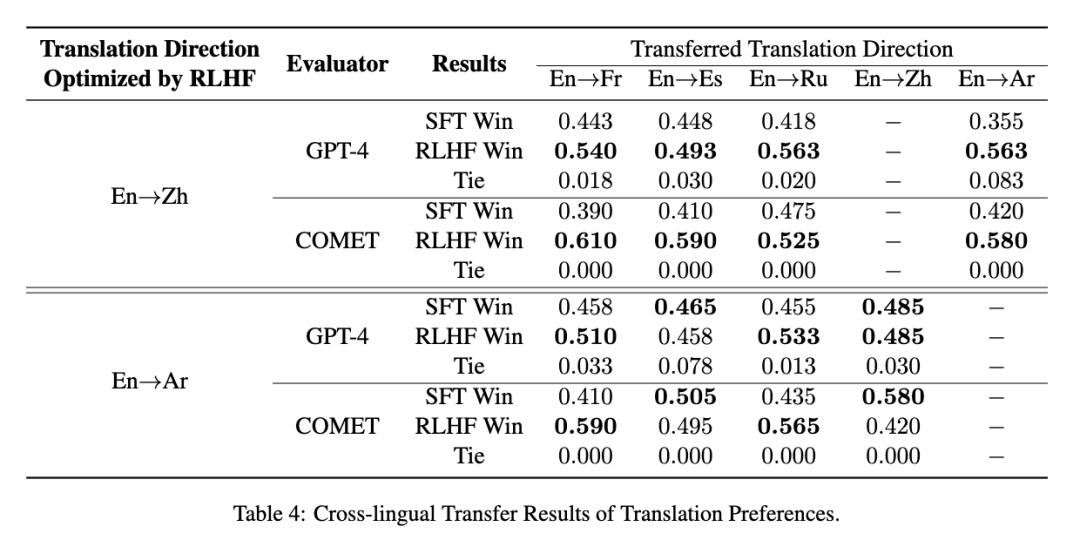
使用RLHF推动翻译偏好建模:低成本实现“信达雅”
在机器翻译领域,“忠实度(信)”、“表现力(达)”、“优雅性(雅)”一直是研究者们不懈追求的目标。然而,传统的评估指标如BLEU并不能完全符合人类对翻译质量的偏好。为了解决这一挑战,复旦大学自然语言处理实验室与复旦大学外文学院携手合作,共同探索了利用基于人类反馈的强化学习(RLHF)来提升翻译质量的可能途径。 我们提出一种代价高效的偏好学习策略,只需少量专业翻译即可让模型对齐人类的“信、达、雅”
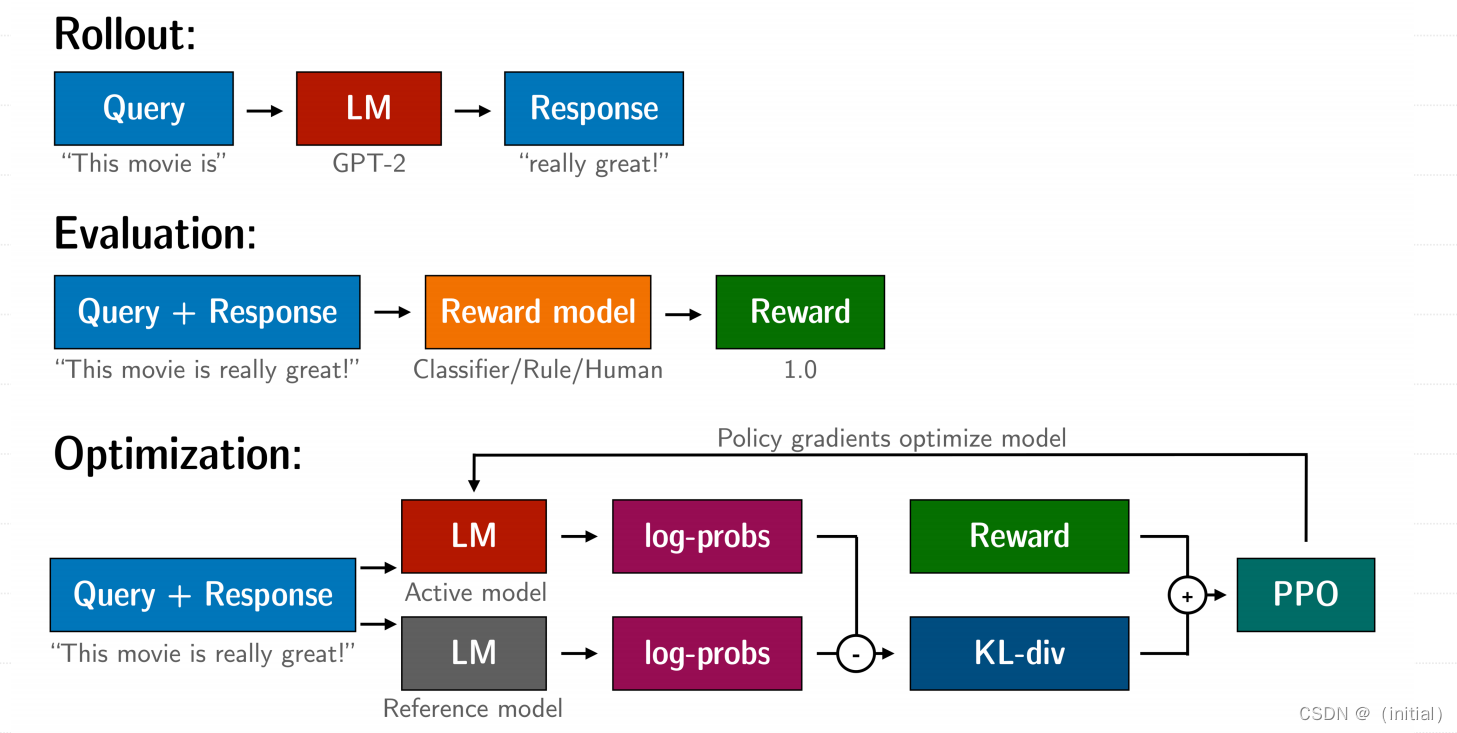
14.基于人类反馈的强化学习(RLHF)技术详解
基于人类反馈的强化学习(RLHF)技术详解 RLHF 技术拆解 RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,我们按三个步骤分解: 预训练一个语言模型 (LM) ;训练一个奖励模型 (Reward Model,RM) ;用强化学习 (RL) 方式微调 LM。 步骤一:使用SFT微调预训练语言模型 先收集⼀个提示词集合,并要求标注⼈员写出⾼质量的回复,然后使⽤该数据集以监督的⽅

RLHF(从人类反馈中进行强化学习)详解(四)
在人工智能领域,强化学习人类反馈(Reinforcement Learning from Human Feedback, RLHF)是一种将人类反馈与强化学习相结合的方法。通过引入人类反馈,RLHF可以训练出更符合人类期望和需求的智能体。然而,要确保训练效果,评测成为了关键的一环。本篇博客将详细探讨RLHF中的评测技术,并提供具体实例和代码示例。 什么是RLHF? RLHF是一种通过人类反馈来

清华大学提出IFT对齐算法,打破SFT与RLHF局限性
监督微调(Supervised Fine-Tuning, SFT)和基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)是预训练后提升语言模型能力的两大基础流程,其目标是使模型更贴近人类的偏好和需求。 考虑到监督微调的有效性有限,以及RLHF构建数据和计算成本高昂,这两种方法常常被结合使用。但由于损失函数、数据格式的差异以及对
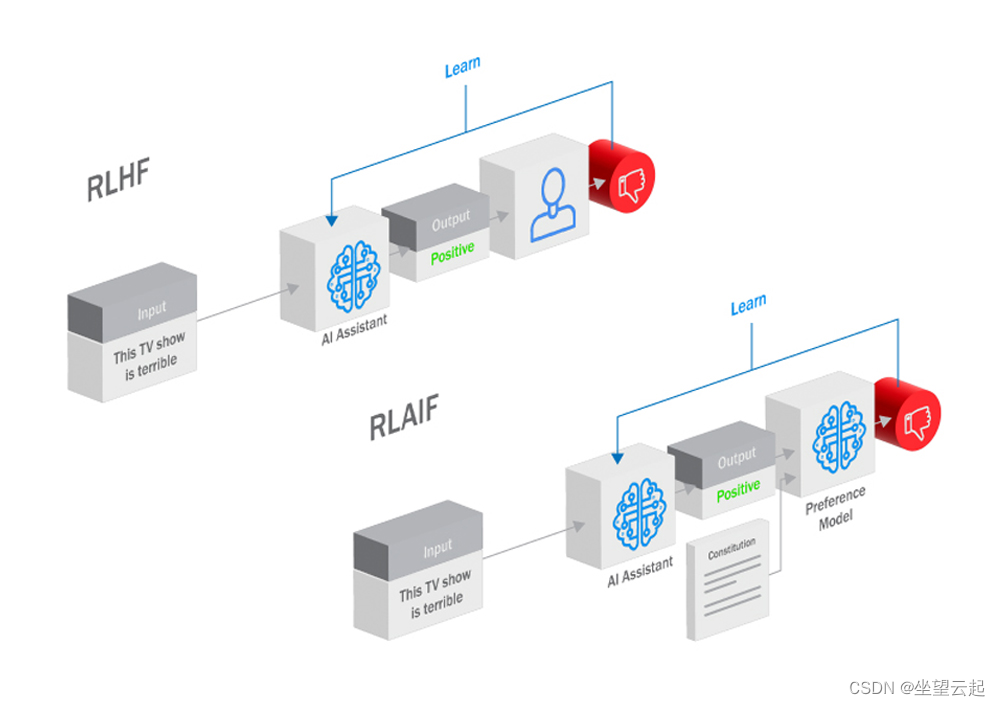
大语言模型微调过程中的 RLHF 和 RLAIF 有什么区别?
目前想要深入挖掘大型语言模型(LLM)的全部潜力需要模型与我们人类的目标和偏好保持一致。从而出现了两种方法:来自人类反馈的人力强化学习(RLHF)和来自人工智能反馈的人工智能驱动的强化学习(RLAIF)。两者都利用强化学习(RL)中的反馈循环来引导大语言模型接近并实现人类意图,但这两种方法的机制和含义却截然不同。 什么是 RLHF? RLHF是一个弥合人工智能模

RLHF(Reinforcement Learning from Human Feedback)的故事:起源、动机、技术及现代应用
RLHF(Reinforcement Learning from Human Feedback)的故事:起源、动机、技术及现代应用 自2018年BERT模型的提出以来,AI研究领域见证了自动语言任务处理技术的快速发展。BERT结合了变压器架构、自监督预训练及监督式迁移学习的强大能力,改写了多个性能基准测试的记录。尽管BERT不适用于生成任务,T5模型证明了监督式迁移学习在此类任务中同样有效。然而
DeepSpeed-Chat RLHF 阶段代码解读(0) —— 原始 PPO 代码解读
为了理解 DeepSpeed-Chat RLHF 的 RLHF 全部过程,这个系列会分三篇文章分别介绍: 原始 PPO 代码解读RLHF 奖励函数代码解读RLHF PPO 代码解读 这是系列的第一篇文章,我们来一步一步的看 PPO 算法的代码实现,对于 PPO 算法原理不太了解的同学,可以参考之前的文章: 深度强化学习(DRL)算法 2 —— PPO 之 Clipped Surrogate Obj
【LLM】大模型之RLHF和替代方法(DPO、RAILF、ReST等)
note SFT使用交叉熵损失函数,目标是调整参数使模型输出与标准答案一致,不能从整体把控output质量,RLHF(分为奖励模型训练、近端策略优化两个步骤)则是将output作为一个整体考虑,优化目标是使模型生成高质量回复。 启发1:像可以用6b、66b依次得到差一点、好一点的target构造排序数据集,进行DPO直接偏好学习或者其他RLHF替代方法(RAILF、ReST等),比直接RLHF更
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)
MedicalGPT 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化)。 MedicalGPT: Training Your Own Medical GPT Model with ChatGPT Training Pipeline. 训练医疗大模型,实现了包括增量预训练、有监督微调、RLHF(奖励建模、强化学习训练)和DPO(直接偏好优化
大语言模型LLM Large Language Model 的涌现Emergence 反馈强化学习 RLHF 预训练 token word embeddings 温度 temperature=0.7
1. Large Language Model(大型语言模型) Large Language Model(大型语言模型)是指具有大规模参数数量和处理能力的语言模型。这些模型通过深度学习技术训练,能够处理和生成自然语言文本。 大型语言模型在自然语言处理领域发挥着重要作用,它们能够理解和生成文本,执行语言相关的任务,如机器翻译、文本摘要、情感分析、对话系统等。这些模型的训练基于大量的文本数据集,使

偏好对齐RLHF-OpenAI·DeepMind·Anthropic对比分析
OpenAI paper: InstructGPT, Training language models to follow instructions with human feedback paper: Learning to summarize from human feedback Introducing ChatGPT 解密Prompt系列4介绍了InstructGPT指令

吴恩达-从人类反馈中进行强化学习RLHF
吴恩达-从人类反馈中进行强化学习RLHF https://www.bilibili.com/video/BV1R94y1P7QX?p=1&vd_source=e7939b5cb7bc219a05ee9941cd297ade 1、公开的LLM,Llama2, 使用LLM对同一个提示产生多个不同输出,然后人类评估这些输出。评估方法是对比两个输出,找出他们喜欢的那个。于是形成的就是偏好数据集。pr
RLHF与LLM训练的碰撞:寻找最佳实践之路!
了解更多公众号:芝士AI吃鱼 在讨论大型语言模型(LLM)时,无论是在研究新闻还是教程中,经常提到一个称为“带有人类反馈的强化学习”(RLHF)的过程。由于RLHF能够将人类偏好纳入优化过程,从而提高模型的有用性和安全性,它已成为现代LLM训练流程的一个重要部分。在本文中,将逐步分解RLHF,以提供对其核心理念和重要性的理解参考。 典型的LLM训练流程 现代基于transformer的
RLHF几大常用框架实践对比(trlx、deepspeedchat、colossalaichat)
原文:RLHF几大常用框架实践对比(trlx、deepspeedchat、colossalaichat) - 知乎 目录 收起 一、RLHF的作用 二、实践效果 三、怎么做 1、框架 2、算法 3、数据 4、调参 一、RLHF的作用 从InstructGPT的论文中看,RLHF目的就是为了让模型输出的结果能和人类对齐。而所谓对齐,体现在三点: 有用:即遵守指令的能力诚实:不
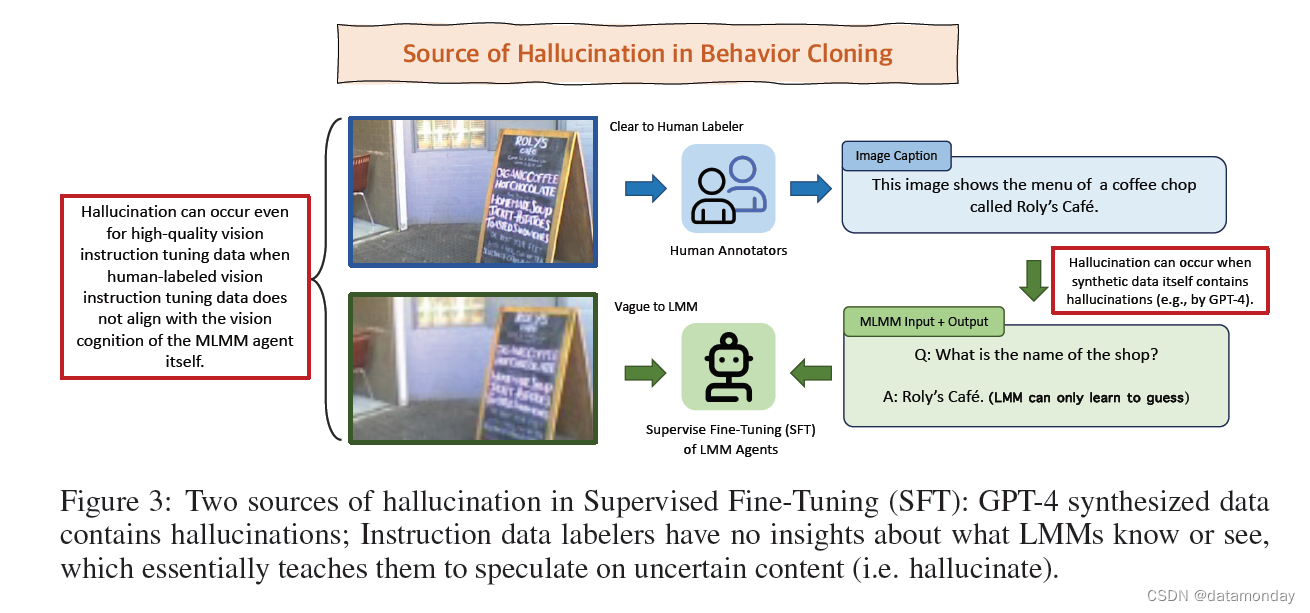
【LMM 004】LLaVA-RLHF:用事实增强的 RLHF 对齐大型多模态模型
论文标题:Aligning Large Multimodal Models with Factually Augmented RLHF 论文作者:Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming

基于人类反馈的强化学习(RLHF)
1. 监督微调(SFT):为了训练语言模型(LM)掌握基本的任务执行技能,首先需要构建一个监督数据集。这个数据集包含了指令性的输入提示和期望的输出结果,通过这些数据对LM进行精细调整。为了保证任务种类的广泛性,这些输入提示和输出结果需由专业标注人员针对特定任务量身定制。例如,InstructGPT项目中,标注人员会创造性地编写输入提示(比如,“给出五个重燃职业激情的建议”)和对应的输出,覆盖了开放
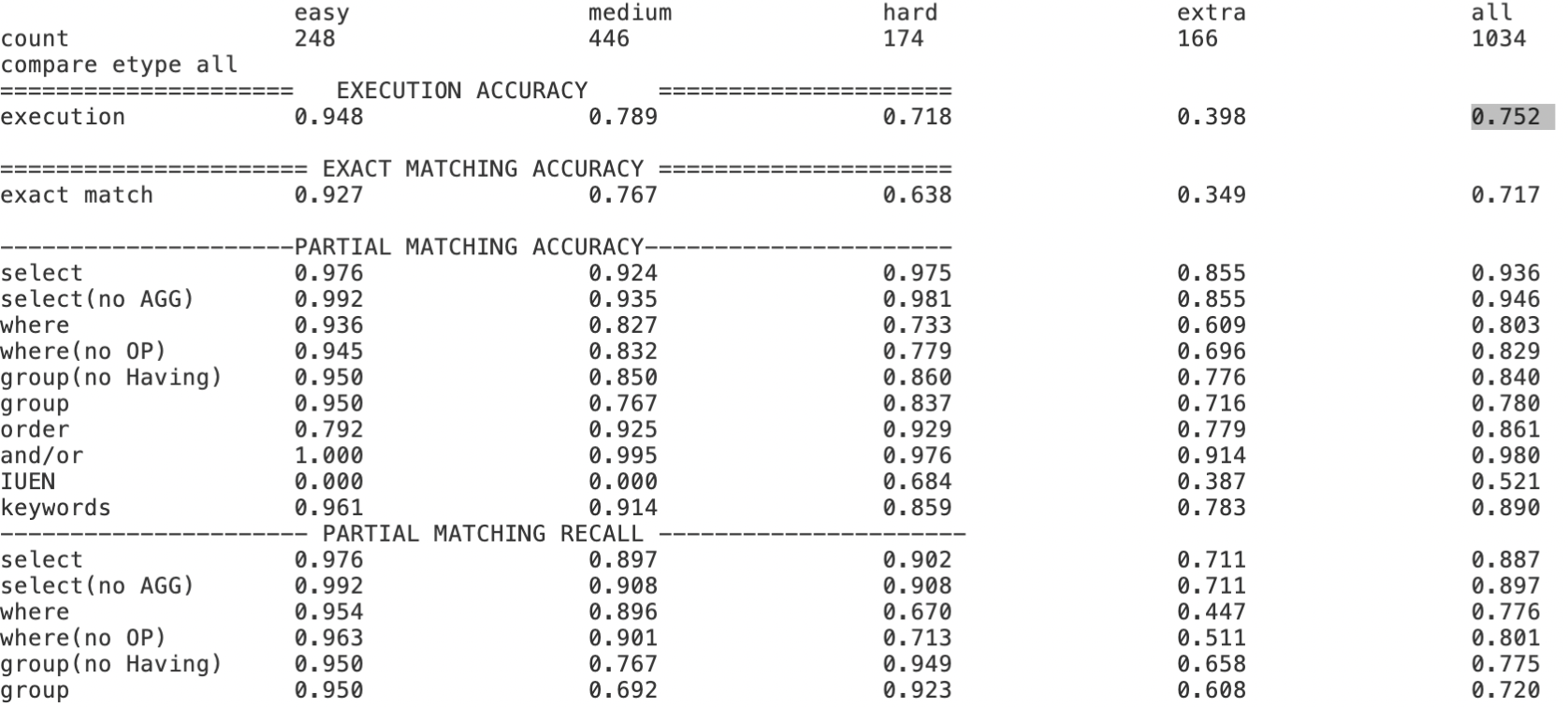
Text-to-SQL小白入门(十)RLHF在Text2SQL领域的探索实践
本文内容主要基于以下开源项目探索实践, Awesome-Text2SQL:GitHub - eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2SQL, Text2DSL、Text2API、Text2Vis and more.DB-GPT-Hub:GitHub
多模态大模型:关于RLHF那些事儿
Overview 多模态大模型关于RLHF的代表性文章一、LLaVA-RLHF二、RLHF-V三、SILKIE 多模态大模型关于RLHF的代表性文章 一、LLaVA-RLHF 题目: ALIGNING LARGE MULTIMODAL MODELS WITH FACTUALLY AUGMENTED RLHF 机构:UC伯克利 论文: https://arxiv.org/pdf
多模态大模型:关于RLHF那些事儿
Overview 多模态大模型关于RLHF的代表性文章一、LLaVA-RLHF二、RLHF-V三、SILKIE 多模态大模型关于RLHF的代表性文章 一、LLaVA-RLHF 题目: ALIGNING LARGE MULTIMODAL MODELS WITH FACTUALLY AUGMENTED RLHF 机构:UC伯克利 论文: https://arxiv.org/pdf

吴恩达RLHF课程笔记
1.创建偏好数据集 一个prompt输入到LLM后可以有多个回答,对每个回答选择偏好 比如{prompt,answer1,answer2,prefer1} 2.根据这个数据集(偏好数据集),创建reward model,这个model也是一个LLM,并且它是回归模型,返回的是对每个answer的score,loss是最大化winning candidate和losing candidate的
吴恩达RLHF课程笔记
1.创建偏好数据集 一个prompt输入到LLM后可以有多个回答,对每个回答选择偏好 比如{prompt,answer1,answer2,prefer1} 2.根据这个数据集(偏好数据集),创建reward model,这个model也是一个LLM,并且它是回归模型,返回的是对每个answer的score,loss是最大化winning candidate和losing candidate的
RLHF介绍及实践测试
介绍 RLHF(Reinforcement Learning Hyperparameter Optimization Framework)是一种用于强化学习模型的超参数优化框架。它结合了强化学习中的经典方法和贝叶斯优化技术,能够更高效地找到最佳超参数组合。下面是强化学习微调的完整 RLHF 流程: RLHF-Stage1 是 supervised-fintuning,即使用上文提到的数据集进行
一文打通RLHF的来龙去脉
文章目录 1. RLHF的发展历程2. 强化学习2.1 强化学习基本概念2.2 强化学习分类2.3 Policy Gradient2.3.1 add a baseline2.3.2 assign suitable credit 2.4 TRPO和PPO算法2.4.1 on-policy2.4.2 Important Sampling2.4.3 Off Policy2.4.4 TRPO 和 P