
相关文章

强化学习-优化策略算法(DPO和PPO)
DPO(Direct Preference Optimization)和 PPO(Proximal Policy Optimization)虽然都是用于优化策略的算法,但它们在理论基础、优化目标和应用场景上存在显著区别。 优化目标 • PPO: • PPO 是一种基于策略梯度的优化算法,其目标是通过最大化累积奖励来优化策略。PPO 通过限制策略更新的幅度(剪切损失函数),确保训练过程中的策略更

深入理解DPO(Direct Preference Optimization)算法
目录 1. 什么是DPO?2. Bradley-Terry模型2.1 奖励模型的训练 3. 从PPO到DPO4. DPO的简单实现5. 梯度分析Ref 1. 什么是DPO? 直接偏好优化(Direct Preference Optimization, DPO)是一种不需要强化学习的对齐算法。由于去除了复杂的强化学习算法,DPO 可以通过与有监督微调(SFT)相似的复杂度实现模型对

大模型对齐:DPO vs PPO
现在这些大型语言模型(LLMs),可真是火得不行,各行各业都离不开它们了。它们能处理和写出跟我们差不多的文本,这让自然语言处理、写东西、还有客服这些领域都焕然一新。不过呢,这技术进步的同时也带来了一个大问题,就是怎么让这些模型跟我们人类的想法和价值观保持一致。要是没搞定这个对齐问题,这些模型搞不好就会写出一些伤人的、有偏见的或者让人误解的内容来。 咱们来聊聊怎么让这些大型语言模型更好地符合我们人

大模型学习笔记 - LLM 对齐优化算法 DPO
LLM - DPO LLM - DPO DPO 概述DPO 目标函数推导DPO 目标函数梯度的推导 DPO 概述 大模型预训练是从大量语料中进行无监督学习,语料库内容混杂,训练的目标是语言模型损失,任务是next token prediction,生成的token 不可控,为了让大模型能生成符合人类偏好的答案(无毒无害等)一般都会进行微调和人类对齐,通常采用的方法是 基于人类反馈的强化学习

LLM 直接偏好优化(DPO)的一些研究
今天我们来聊聊大型语言模型(LLMs)吧。要让这些聪明的家伙和咱们人类的价值观还有喜好对上号,这事儿可不简单。以前咱们用的方法,比如基于人类反馈的强化学习(RLHF),虽然管用,但是它太复杂了,得用上好多计算资源和数据处理的力气。现在,直接偏好优化(Direct Preference Optimization, DPO)来了,它就像是一股清流,给咱们提供了一个既简单又高效的新选择。DPO简化了优化

分意图 Prompt 调试、后置判别改写、RLHF 缓解大模型生成可控性
分意图 Prompt 调试、后置判别改写、RLHF 这三种方法是为了提高大模型生成内容的可控性,具体原因如下: 分意图 Prompt 调试: 通过针对不同的任务或意图设计特定的 Prompt,可以更精确地引导模型生成符合期望的内容。分意图 Prompt 调试的核心是将复杂的问题分解为更易于模型理解和处理的小问题,从而减少生成内容的偏差和不确定性。这种方法通过精细化控制 Prompt,能够在一定
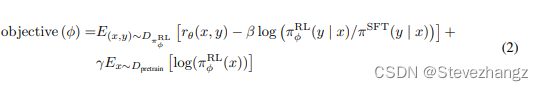
GPT3.5的PPO目标函数怎么来的:From PPO to PPO-ptx
给定当前优化的大模型 π \pi π,以及SFT模型 π S F T \pi_{SFT} πSFT 原始优化目标为: max E ( s , a ) ∼ R L [ π ( s , a ) π S F T ( s , a ) A π S F T ( s , a ) ] \max E_{(s,a)\sim RL}[\frac{\pi(s,a)}{\pi_{SFT}(s,a)}A^{\pi_
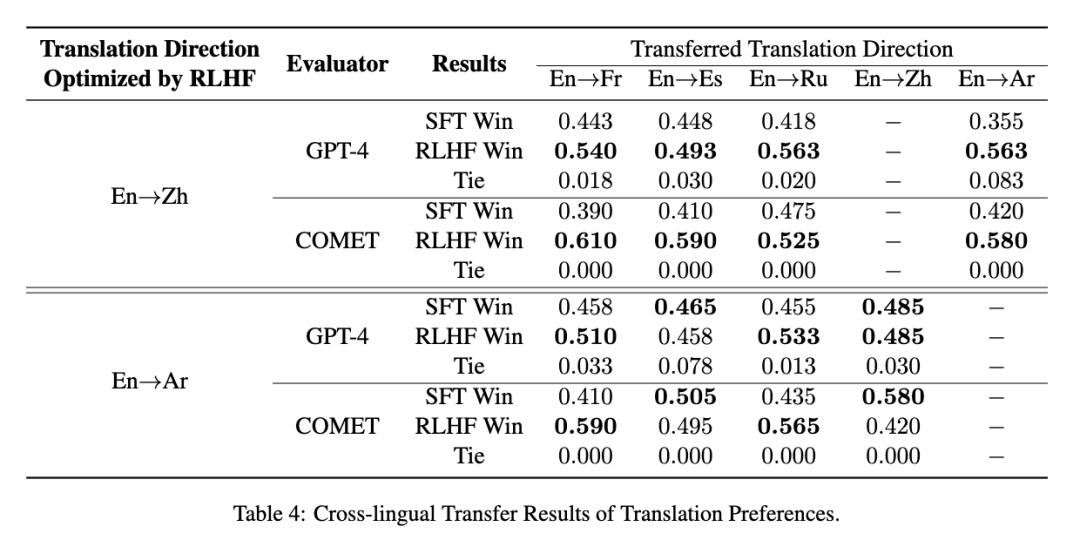
使用RLHF推动翻译偏好建模:低成本实现“信达雅”
在机器翻译领域,“忠实度(信)”、“表现力(达)”、“优雅性(雅)”一直是研究者们不懈追求的目标。然而,传统的评估指标如BLEU并不能完全符合人类对翻译质量的偏好。为了解决这一挑战,复旦大学自然语言处理实验室与复旦大学外文学院携手合作,共同探索了利用基于人类反馈的强化学习(RLHF)来提升翻译质量的可能途径。 我们提出一种代价高效的偏好学习策略,只需少量专业翻译即可让模型对齐人类的“信、达、雅”
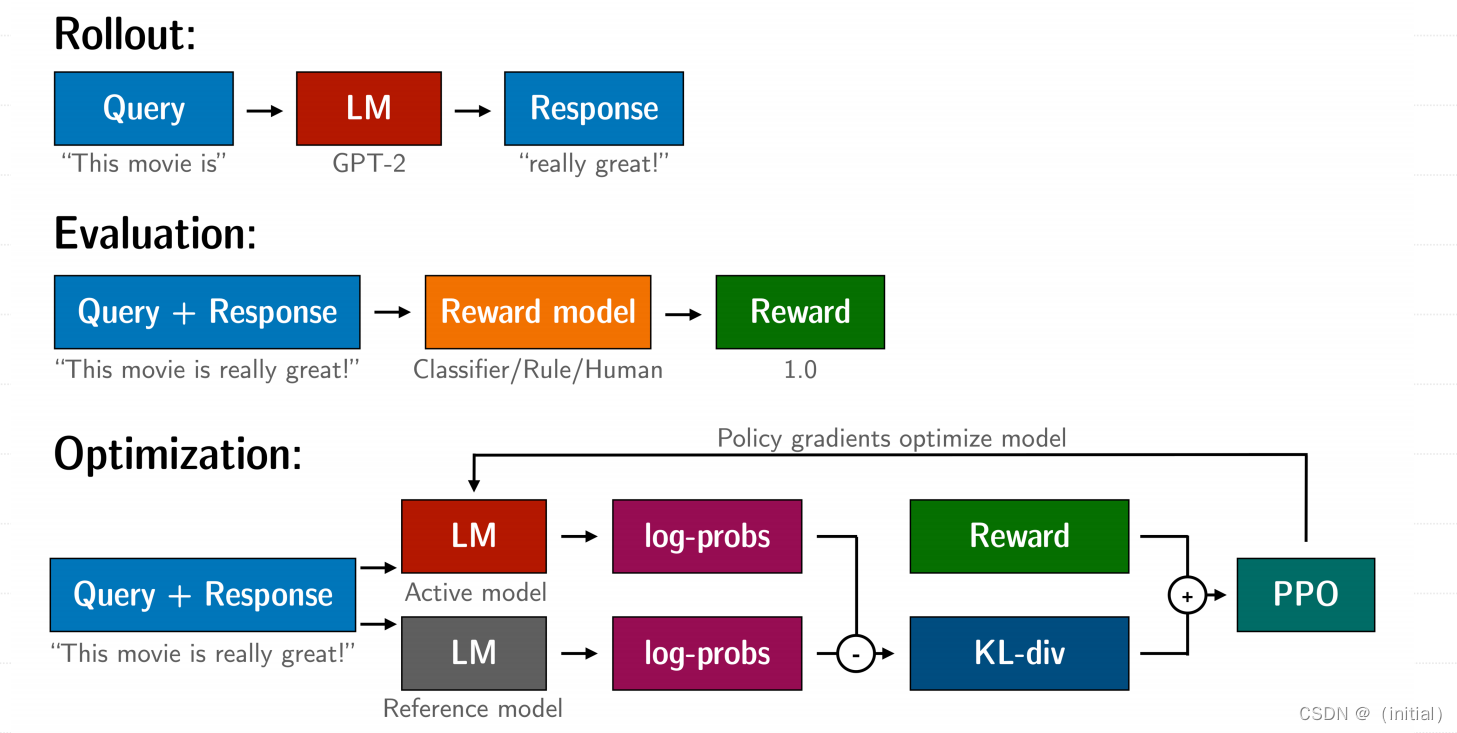
14.基于人类反馈的强化学习(RLHF)技术详解
基于人类反馈的强化学习(RLHF)技术详解 RLHF 技术拆解 RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,我们按三个步骤分解: 预训练一个语言模型 (LM) ;训练一个奖励模型 (Reward Model,RM) ;用强化学习 (RL) 方式微调 LM。 步骤一:使用SFT微调预训练语言模型 先收集⼀个提示词集合,并要求标注⼈员写出⾼质量的回复,然后使⽤该数据集以监督的⽅
使用DPO微调大模型Qwen2详解
简介 基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。但传统的RLHF比较复杂,且还需要奖励模型,故DPO方法被提出,其将现有方法使用的基于强化学习的目标转换为可以通过简单的二元交叉熵损失直