ppo专题

RLHF PPO DPO
生成式大模型的RLHF技术(一):基础 DPO: Direct Preference Optimization 论文解读及代码实践 深入对比 DPO 和 RLHF 深入理解DPO(Direct Preference Optimization)算法

强化学习-优化策略算法(DPO和PPO)
DPO(Direct Preference Optimization)和 PPO(Proximal Policy Optimization)虽然都是用于优化策略的算法,但它们在理论基础、优化目标和应用场景上存在显著区别。 优化目标 • PPO: • PPO 是一种基于策略梯度的优化算法,其目标是通过最大化累积奖励来优化策略。PPO 通过限制策略更新的幅度(剪切损失函数),确保训练过程中的策略更

大模型对齐:DPO vs PPO
现在这些大型语言模型(LLMs),可真是火得不行,各行各业都离不开它们了。它们能处理和写出跟我们差不多的文本,这让自然语言处理、写东西、还有客服这些领域都焕然一新。不过呢,这技术进步的同时也带来了一个大问题,就是怎么让这些模型跟我们人类的想法和价值观保持一致。要是没搞定这个对齐问题,这些模型搞不好就会写出一些伤人的、有偏见的或者让人误解的内容来。 咱们来聊聊怎么让这些大型语言模型更好地符合我们人
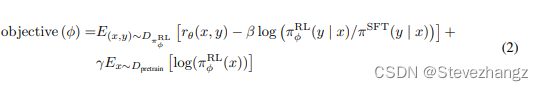
GPT3.5的PPO目标函数怎么来的:From PPO to PPO-ptx
给定当前优化的大模型 π \pi π,以及SFT模型 π S F T \pi_{SFT} πSFT 原始优化目标为: max E ( s , a ) ∼ R L [ π ( s , a ) π S F T ( s , a ) A π S F T ( s , a ) ] \max E_{(s,a)\sim RL}[\frac{\pi(s,a)}{\pi_{SFT}(s,a)}A^{\pi_

了解强化学习算法 PPO
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 介绍: PPO 算法,即 Proximal Policy Optimization(近端策略优化),是一种强化学习算法。它的主要目的是改进策略梯度方法,使得训练过程更加稳定高效。PPO 算法通过限制策略更新的步长,来避免训练过程中出现的性能剧烈波动,因而在实际应用中取得了广泛的成功。该算法核心的元

PPO:推动语言模型对齐的关键技术
PPO:推动语言模型对齐的关键技术 最新的人工智能研究揭示,通过人类反馈的强化学习(RLHF)是训练大型语言模型(LLMs)的关键技术。尽管某些AI从业者因熟悉监督学习而回避使用RL,但RL技术其实并不复杂,并能显著提升LLM的性能。本文深入探讨了Proximal Policy Optimization (PPO)算法,它易于理解和使用,被OpenAI选为对InstructGPT进行RLHF的算
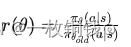
Proximal Policy Optimization (PPO)
Proximal Policy Optimization (PPO) 是一种先进的策略梯度方法,由 OpenAI 在 2017 年提出,目的是提高样本效率和训练过程的稳定性,特别适用于处理动态变化的环境,如网络环境中的自适应控制问题。PPO 成功地解决了早期策略梯度方法中的一些关键问题,尤其是在执行策略更新时保持稳定性的问题。 1. 核心思想 PPO 旨在通过限制策略更新的大小来平衡探索和利用
DeepSpeed-Chat RLHF 阶段代码解读(0) —— 原始 PPO 代码解读
为了理解 DeepSpeed-Chat RLHF 的 RLHF 全部过程,这个系列会分三篇文章分别介绍: 原始 PPO 代码解读RLHF 奖励函数代码解读RLHF PPO 代码解读 这是系列的第一篇文章,我们来一步一步的看 PPO 算法的代码实现,对于 PPO 算法原理不太了解的同学,可以参考之前的文章: 深度强化学习(DRL)算法 2 —— PPO 之 Clipped Surrogate Obj

强化学习_06_pytorch-PPO实践(Hopper-v4)
一、PPO优化 PPO的简介和实践可以看笔者之前的文章 强化学习_06_pytorch-PPO实践(Pendulum-v1) 针对之前的PPO做了主要以下优化: batch_normalize: 在mini_batch 函数中进行adv的normalize, 加速模型对adv的学习policyNet采用beta分布(0~1): 同时增加MaxMinScale 将beta分布产出值转换到acti
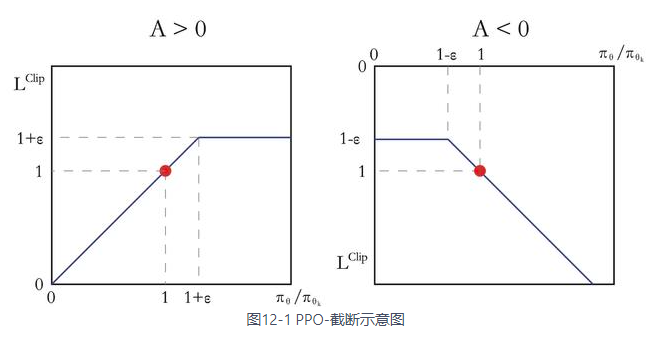
ETH开源PPO算法学习
前言 项目地址:https://github.com/leggedrobotics/rsl_rl 项目简介:快速简单的强化学习算法实现,设计为完全在 GPU 上运行。这段代码是 NVIDIA Isaac GYM 提供的 rl-pytorch 的进化版。 下载源码,查看目录,整个项目模块化得非常好,每个部分各司其职。下面我们自底向上地进行讲解加粗的部分。 rsl_rl/ │ __init__

【RL】(task5)PPO算法和代码实现
note 文章目录 note一、RLHF对齐1. 训练奖励模型和RL2. RLHF3. 常见的公开偏好数据集 二、PPO近端策略优化1. PPO介绍2. PPO效果 二、PPO代码实践PPOmemoryPPO modelPPO update 时间安排Reference 一、RLHF对齐 1. 训练奖励模型和RL 用奖励模型训练sft模型,生成模型使用奖励或惩罚来更新策略,以便

PPO 跑CartPole-v1
gym-0.26.2 cartPole-v1 参考动手学强化学习书中的代码,并做了一些修改 代码 import gymimport torchimport torch.nn as nnimport torch.nn.functional as Fimport numpy as npimport matplotlib.pyplot as pltfrom tqdm import
13、近端策略优化Proximal Policy Optimization (PPO) 算法:从原理到实践
基于LunarLander登陆器的PPO强化学习(含PYTHON工程) PPO对标的是TRPO算法,改进了其性能。也有学者认为其理论性不强,但实践效果往往不错。 TRPO的缺点: 无法处理大参数矩阵:尽管使用了共轭梯度法,TRPO仍然难以处理大的 Fisher矩阵,即使它们不需要求逆近似值可能会违反KL约束,从而导致分析得出的步长过大,超出限制要求我们不能利用一阶随机梯度优化器,例如ADAM

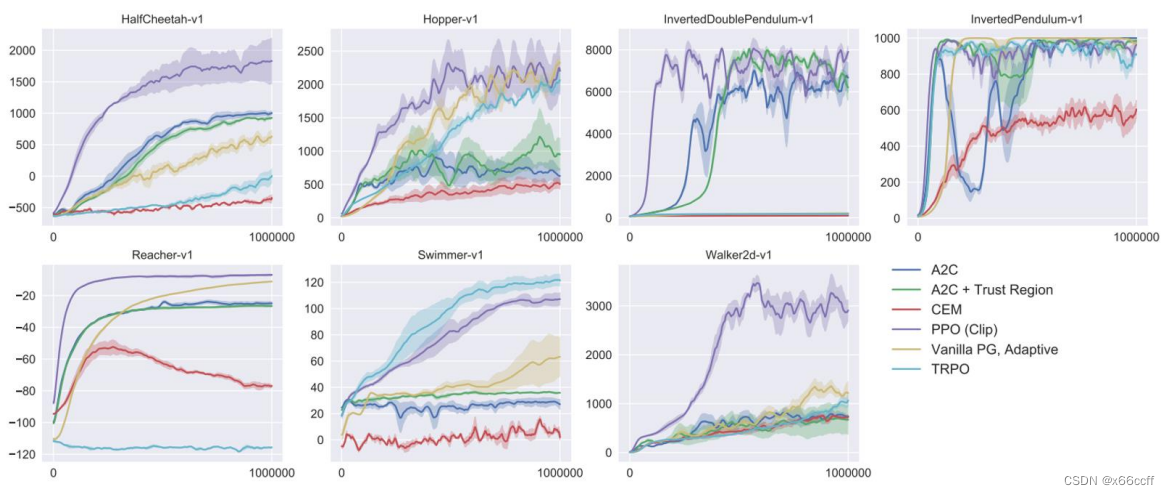
【深度强化学习】TRPO、PPO
策略梯度的缺点 步长难以确定,一旦步长选的不好,就导致恶性循环 步长不合适 → 策略变差 → 采集的数据变差 → (回报 / 梯度导致的)步长不合适 步长不合适 \to 策略变差 \to 采集的数据变差 \to (回报/梯度导致的)步长不合适 步长不合适→策略变差→采集的数据变差→(回报/梯度导致的)步长不合适 一阶信息不限制步长容易越过局部最优,而且很难回来 TRPO 置信域策略优
![[cleanrl] ppo_continuous_action源码解析](/front/images/it_default.gif)
[cleanrl] ppo_continuous_action源码解析
1 import库(略) import osimport randomimport timefrom dataclasses import dataclassimport gymnasium as gymimport numpy as npimport torchimport torch.nn as nnimport torch.optim as optimimport tyro

拆解大语言模型 RLHF 中的PPO算法
为什么大多数介绍大语言模型 RLHF 的文章,一讲到 PPO 算法的细节就戛然而止了呢?要么直接略过,要么就只扔出一个 PPO 的链接。然而 LLM x PPO 跟传统的 PPO 还是有些不同的呀。 其实在 ChatGPT 推出后的相当一段时间内,我一直在等一篇能给我讲得明明白白的文章,但是一直未能如愿。我想大概是能写的人都没时间写吧。 前几个月,自己在工作中遇到要用到 PPO 的场景了。我心

强化学习------PPO算法
目录 简介一、PPO原理1、由On-policy 转化为Off-policy2、Importance Sampling(重要性采样)3、off-policy下的梯度公式推导 二、PPO算法两种形式1、PPO-Penalty2、PPO-Clip 三、PPO算法实战四、参考 简介 PPO 算法之所以被提出,根本原因在于 Policy Gradient 在处理连续动作空间时 Le

强化学习笔记1——ppo算法
参考莫烦Python的学习视频链接: 莫烦Python的学习视频. why PPO? 根据 OpenAI 的官方博客, PPO 已经成为他们在强化学习上的默认算法. 如果一句话概括 PPO: OpenAI 提出的一种解决 Policy Gradient 不好确定 Learning rate (或者 Step size) 的问题. 因为如果 step size 过大, 学出来的 Policy

【论文阅读】强化学习—近端策略优化算法(Proximal Policy Optimization Algorithms, PPO)
(一)Title 写在前面: 本文介绍PPO优化方法及其一些公式的推导。原文中作者给出了三种优化方法,其中第三种是第一种的拓展,这两种使用广泛,且效果好,第二种方法在实验中验证效果不好,但也算一个trick,作者也在文中进行了分析。 (二)Abstract 深度强化学习在训练过程中难以避免效果容易发生退化并且很难恢复这类问题,导致训练不稳定。自然策略梯度[1](NPG,Natural

强化学习调参经验大集成:TD3、PPO+GAE、SAC、离散动作噪声探索、以及Off-policy 、On-policy 算法常见超参数
1. 强化学习通用参数设置 (1)强化学习算法选用 目前推荐的使用的算法主要是: 离散控制问题建议算法: ①D3QN——D3 指的是 Dueling Double DQN,主要集成了 Double DQN 与 Dueling DQN 的方法架构,另可与 Noisy DQN 来配合γ-greedy 方法来提升探索效率。 ②SAC-Discrete——提出的主要目标是用于解决混合动作空间中的