本文主要是介绍【RL】(task5)PPO算法和代码实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
note
文章目录
- note
- 一、RLHF对齐
- 1. 训练奖励模型和RL
- 2. RLHF
- 3. 常见的公开偏好数据集
- 二、PPO近端策略优化
- 1. PPO介绍
- 2. PPO效果
- 二、PPO代码实践
- PPOmemory
- PPO model
- PPO update
- 时间安排
- Reference
一、RLHF对齐
1. 训练奖励模型和RL
用奖励模型训练sft模型,生成模型使用奖励或惩罚来更新策略,以便生成更高质量、符合人类偏好的文本。
| 奖励模型 | RL强化学习 | |
|---|---|---|
| 作用 | (1)学习人类兴趣偏好,训练奖励模型。由于需要学习到偏好答案,训练语料中含有response_rejected不符合问题的答案。 (2)奖励模型能够在RL强化学习阶段对多个答案进行打分排序。 | 根据奖励模型,训练之前的sft微调模型,RL强化学习阶段可以复用sft的数据集 |
| 训练语料 | {‘question’: ‘土源性线虫感染的多发地区是哪里?’, ‘response_chosen’: ‘苏北地区;贵州省剑河县;西南贫困地区;桂东;江西省鄱阳湖区;江西省’, ‘response_rejected’: ‘在热带和亚热带地区的农村。’}, | {‘qustion’:‘这是一个自然语言推理问题:\n前提:要继续做好扶贫工作,帮助贫困地区脱贫致富\n假设:中国有扶贫工作\n选项:矛盾,蕴含,中立’ ‘answer’:‘蕴含。因为前提中提到了要继续做好扶贫工作,这表明中国存在扶贫工作。因此,前提蕴含了假设。’} |
2. RLHF
RLHF(reinforcement learning from human feedback)
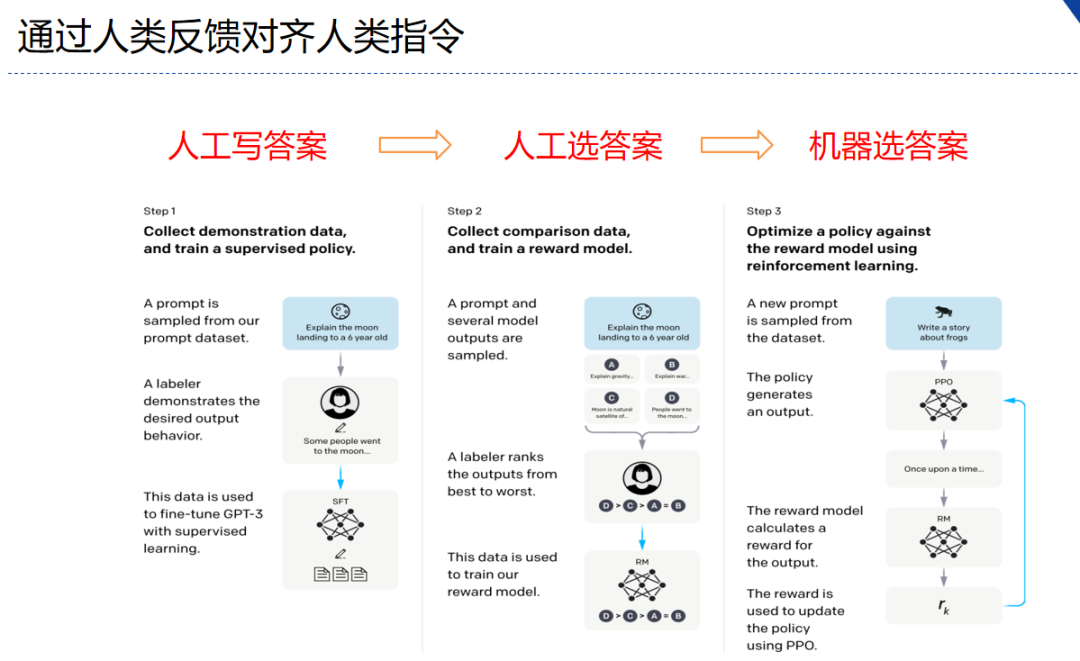
- 分为三个步骤
- step1 我做你看:有监督学习,从训练集中挑出一批prompt,人工对prompt写答案。其实就是构造sft数据集进行微调。
- step2 你做我看:奖励模型训练,这次不人工写答案了,而是让GPT或其他大模型给出几个候选答案,人工对其质量排序,Reward model学习一个打分器;这个让机器学习人类偏好的过程就是【对齐】,但可能会导致胡说八道,可以通过KL Divergence等方法解决。
- instructGPT中奖励模型的损失函数如下,其中 rθ(x,y) 是奖励模型对提示x和完成y的标量输出,具有参数θ, y w y_w yw是 y w y_w yw和 y l y_l yl中更受欢迎的补全,D是人类比较的数据集。 loss ( θ ) = − 1 ( K 2 ) E ( x , y w , y l ) ∼ D [ log ( σ ( r θ ( x , y w ) − r θ ( x , y l ) ) ) ] \operatorname{loss}(\theta)=-\frac{1}{\left(\begin{array}{c} K \\ 2 \end{array}\right)} E_{\left(x, y_w, y_l\right) \sim D}\left[\log \left(\sigma\left(r_\theta\left(x, y_w\right)-r_\theta\left(x, y_l\right)\right)\right)\right] loss(θ)=−(K2)1E(x,yw,yl)∼D[log(σ(rθ(x,yw)−rθ(x,yl)))]
- 每个样本包括
question、response_chosen、response_rejected键值对,每对样本的loss定义: L ( ψ ) = log σ ( r ( x , y w ) − r ( x , y l ) ) \mathcal{L}(\psi)=\log \sigma\left(r\left(x, y_w\right)-r\left(x, y_l\right)\right) L(ψ)=logσ(r(x,yw)−r(x,yl))- 其中上面的符号: σ \sigma σ 是 sigmoid 函数, r r r 代表参数为 ψ \psi ψ 的奖励模型的值, r ( x , y ) r(x, y) r(x,y) 表示针对输入提示 x x x 和输出 y y y所预测出的单一标量奖励值。
- 上面是instructGPT的ranking loss,但是llama2中增加一个离散函数 m ( r ) m(r) m(r)

- step3 自学成才:PPO训练,利用第二阶段的奖励模型RM计算奖励分数,同时使用PPO(近端策略优化)更新第一步训练得到的sft模型,最大优化该目标函数: objective ( ϕ ) = E ( x , y ) ∼ D π ϕ R L [ r θ ( x , y ) − β log ( π ϕ R L ( y ∣ x ) / π S F T ( y ∣ x ) ) ] + γ E x ∼ D pretrain [ log ( π ϕ R L ( x ) ) ] \begin{aligned} \text { objective }(\phi)= & E_{(x, y) \sim D_{\pi_\phi^{\mathrm{RL}}}}\left[r_\theta(x, y)-\beta \log \left(\pi_\phi^{\mathrm{RL}}(y \mid x) / \pi^{\mathrm{SFT}}(y \mid x)\right)\right]+ \\ & \gamma E_{x \sim D_{\text {pretrain }}}\left[\log \left(\pi_\phi^{\mathrm{RL}}(x)\right)\right] \end{aligned} objective (ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpretrain [log(πϕRL(x))]
- π φ R L π^{RL}_φ πφRL是学习到的RL策略,
- π S F T π^{SFT} πSFT是监督训练模型,
- D p r e t r a i n D_pretrain Dpretrain 是预训练分布。
- KL奖励系数β和预训练损失系数γ分别控制KL惩罚和预训练梯度的强度。对于“PPO”模型,γ 设为 0。

3. 常见的公开偏好数据集
源自《Llama 2: Open Foundation and Fine-Tuned Chat Models》Table 6:
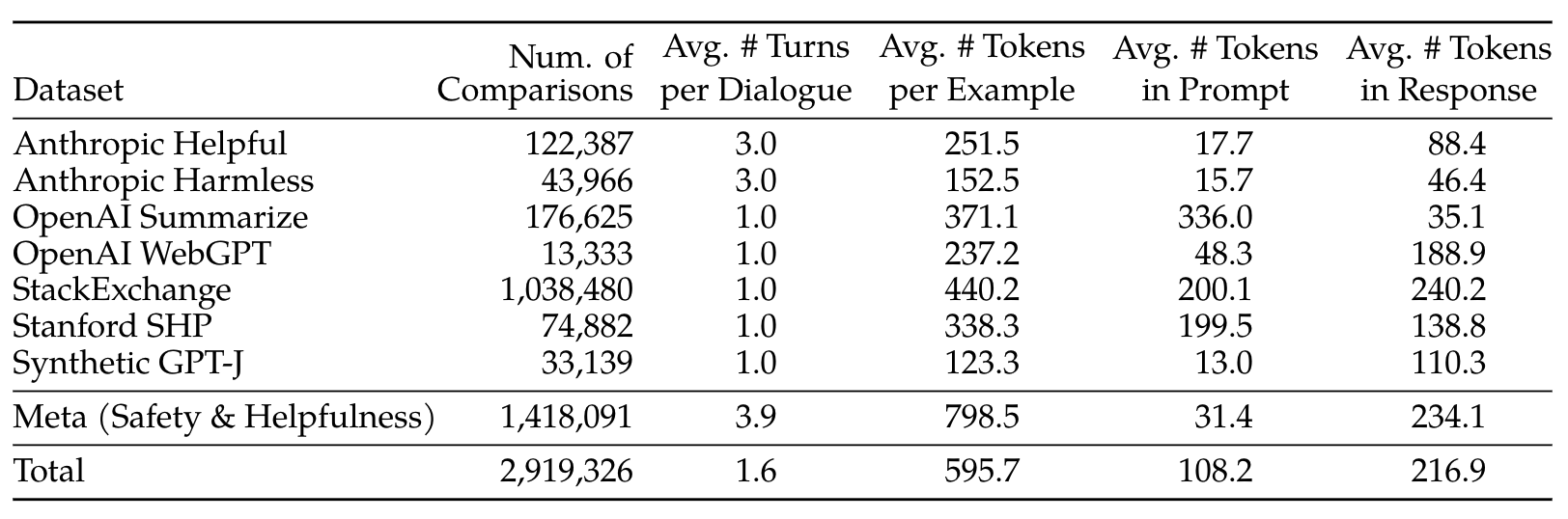
如:https://huggingface.co/datasets/lvwerra/stack-exchange-paired
二、PPO近端策略优化
1. PPO介绍
- 思想:保证策略改进同时,通过一些约束来控制策略更新的幅度;在每次迭代中,通过采样多个轨迹数据来更新策略:
- 使用当前策略对环境交互,收集多个轨迹数据
- 利用第一步的轨迹数据计算当前策略和旧策略之间的KL散度,通过控制KL散度大小来限制策略更新的幅度
- 使用优化器对策略进行更新,使其更加接近当前的样本策略

- 近端策略优化PPO涉及到四个模型:
- (1)策略模型(Policy Model),生成模型回复。
- (2)奖励模型(Reward Model),输出奖励分数来评估回复质量的好坏。
- (3)评论模型(Critic Model/value model),来预测回复的好坏,可以在训练过程中实时调整模型,选择对未来累积收益最大的行为。
- (4)参考模型(Reference Model)提供了一个 SFT 模型的备份,帮助模型不会出现过于极端的变化。
- 近端策略优化PPO的实施流程如下:
- 环境采样:策略模型基于给定输入生成一系列的回复,奖励模型则对这些回复进行打分获得奖励。
- 优势估计:利用评论模型预测生成回复的未来累积奖励,并借助广义优势估计(Generalized Advantage Estimation,GAE)算法来估计优势函数,能够有助于更准确地评估每次行动的好处。
- GAE:基于优势函数加权估计的GAE可以减少策略梯度估计方差
- 优化调整:使用优势函数来优化和调整策略模型,同时利用参考模型确保更新的策略不会有太大的变化,从而维持模型的稳定性。
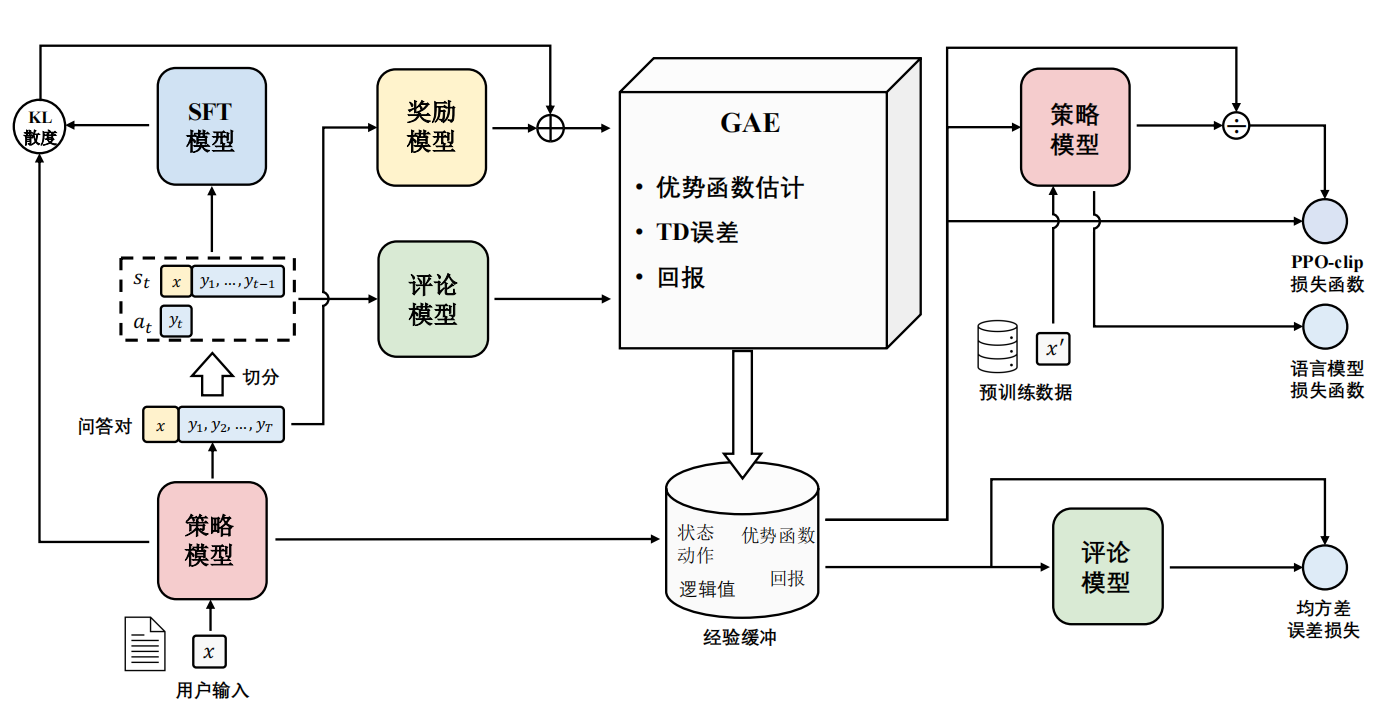
- 相关强化学习概念对应:
- Policy:现有LLM接受输入,进行输出的过程。
- State:当前生成的文本序列。
- Action Space:即vocab,也就是从vocab中选取一个作为本次生成的token。
- KL散度(Kullback-Leibler Divergence),可以衡量两个概率分布之间的差异程度。在 PPO 算法中,KL 散度(Kullback-Leibler Divergence)的计算公式如下:
K L ( π o l d ∣ ∣ π n e w ) = ∑ i π o l d ( i ) l o g ( π o l d ( i ) / π n e w ( i ) ) KL(π_old || π_new) = ∑i π_old(i) log(π_old(i) / π_new(i)) KL(πold∣∣πnew)=∑iπold(i)log(πold(i)/πnew(i))- 其中,π_old 表示旧的策略,π_new 表示当前的样本策略。KL 散度的含义是用 π_old 的分布对 π_new 的分布进行加权,然后计算两个分布之间的差异程度。
- 具体来说,KL 散度的计算方法是首先计算 π_old(i) / π_new(i) 的比值,然后对其取对数并乘以 π_old(i) 来进行加权。最后将所有加权后的结果相加,即可得到 KL 散度的值。这里的KL散度值是一个【惩罚项】,即经过RL训练后模型和SFT后模型的KL散度(繁殖两个模型偏差太多,导致模型效果下降,RLHF的主要目的是alignment)。
注意:KL 散度是一个非对称的度量,即 KL(π_old || π_new) 与 KL(π_new || π_old) 的值可能不相等。在 PPO 算法中,我们通常使用 KL(π_old || π_new) 来控制策略更新的幅度,因为 KL(π_old || π_new) 的值通常比 KL(π_new || π_old) 更容易控制,并且更能够反映出策略改变的方向。
2. PPO效果
在instructGPT论文实验中,效果最好的是GPT-3 + supervised finetuning + RLHF的模型:

二、PPO代码实践
PPO是一种on-policy算法,具有较好的性能,其前身是TRPO算法,也是policy gradient算法的一种,它是现在 OpenAI 默认的强化学习算法。PPO算法主要有两个变种,一个是结合KL penalty的,一个是用了clip方法,本文实现的是后者即PPO-clip。
PPOmemory
我们可以定义一个PPOmemory来存储相关信息:
class PPOMemory:def __init__(self, batch_size):self.states = []self.probs = []self.vals = []self.actions = []self.rewards = []self.dones = []self.batch_size = batch_sizedef sample(self):batch_step = np.arange(0, len(self.states), self.batch_size)indices = np.arange(len(self.states), dtype=np.int64)np.random.shuffle(indices)batches = [indices[i:i+self.batch_size] for i in batch_step]return np.array(self.states),\np.array(self.actions),\np.array(self.probs),\np.array(self.vals),\np.array(self.rewards),\np.array(self.dones),\batchesdef push(self, state, action, probs, vals, reward, done):self.states.append(state)self.actions.append(action)self.probs.append(probs)self.vals.append(vals)self.rewards.append(reward)self.dones.append(done)def clear(self):self.states = []self.probs = []self.actions = []self.rewards = []self.dones = []self.vals = []
这里的push函数就是将得到的相关量放入memory中,sample就是随机采样出来,方便第六步的随机梯度下降。
PPO model
model就是actor和critic两个网络了:
import torch.nn as nn
from torch.distributions.categorical import Categorical
class Actor(nn.Module):def __init__(self,n_states, n_actions,hidden_dim=256):super(Actor, self).__init__()self.actor = nn.Sequential(nn.Linear(n_states, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, n_actions),nn.Softmax(dim=-1))def forward(self, state):dist = self.actor(state)dist = Categorical(dist)return distclass Critic(nn.Module):def __init__(self, n_states,hidden_dim=256):super(Critic, self).__init__()self.critic = nn.Sequential(nn.Linear(n_states, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, 1))def forward(self, state):value = self.critic(state)return value
这里Actor就是得到一个概率分布(Categorica,也可以是别的分布,可以搜索torch distributionsl),critc根据当前状态得到一个值,这里的输入维度可以是n_states+n_actions,即将action信息也纳入critic网络中,这样会更好一些,感兴趣的小伙伴可以试试。
PPO update
定义一个update函数主要实现伪代码中的第六步和第七步:
def update(self):for _ in range(self.n_epochs):state_arr, action_arr, old_prob_arr, vals_arr,\reward_arr, dones_arr, batches = \self.memory.sample()values = vals_arr### compute advantage ###advantage = np.zeros(len(reward_arr), dtype=np.float32)for t in range(len(reward_arr)-1):discount = 1a_t = 0for k in range(t, len(reward_arr)-1):a_t += discount*(reward_arr[k] + self.gamma*values[k+1]*\(1-int(dones_arr[k])) - values[k])discount *= self.gamma*self.gae_lambdaadvantage[t] = a_tadvantage = torch.tensor(advantage).to(self.device)### SGD ###values = torch.tensor(values).to(self.device)for batch in batches:states = torch.tensor(state_arr[batch], dtype=torch.float).to(self.device)old_probs = torch.tensor(old_prob_arr[batch]).to(self.device)actions = torch.tensor(action_arr[batch]).to(self.device)dist = self.actor(states)critic_value = self.critic(states)critic_value = torch.squeeze(critic_value)new_probs = dist.log_prob(actions)prob_ratio = new_probs.exp() / old_probs.exp()weighted_probs = advantage[batch] * prob_ratioweighted_clipped_probs = torch.clamp(prob_ratio, 1-self.policy_clip,1+self.policy_clip)*advantage[batch]actor_loss = -torch.min(weighted_probs, weighted_clipped_probs).mean()returns = advantage[batch] + values[batch]critic_loss = (returns-critic_value)**2critic_loss = critic_loss.mean()total_loss = actor_loss + 0.5*critic_lossself.actor_optimizer.zero_grad()self.critic_optimizer.zero_grad()total_loss.backward()self.actor_optimizer.step()self.critic_optimizer.step()self.memory.clear()
该部分首先从memory中提取搜集到的轨迹信息,然后计算gae,即advantage,接着使用随机梯度下降更新网络,最后清除memory以便搜集下一条轨迹信息。
时间安排
| 任务 | 天数 | 截止时间 | 注意事项 |
|---|---|---|---|
| Task01: 马尔可夫过程、DQN算法 | 3天 | 1月15周一-17日周三 | |
| Task02: 策略梯度算法 | 3天 | 1月18日周四-20周六 | |
| Task03: A2C、A3C算法、JoyRL开源文档(关注多进程) | 3天 | 1月21日周日-23日周二 | |
| Task04: DDPG、TD3算法 | 3天 | 1月24日周三-26日周五 | |
| Task05: PPO算法,JoyRL代码实践(选择任一算法任一环境,研究算法不同参数给实验结果带来的影响,也可以用JoyRL上没有跑过的环境尝试) | 6天 | 1月27日周六-2月1号周四 |
Reference
[1] 开源内容https://linklearner.com/learn/detail/91
[2] https://github.com/datawhalechina/joyrl-book
这篇关于【RL】(task5)PPO算法和代码实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





