task5专题
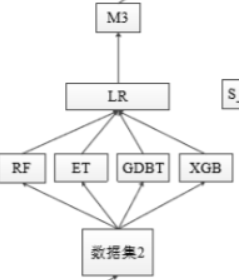
零基础入门数据挖掘之心电图分类 Task5 建模融合
此次学习是整个学习的最后一节。收获颇丰!感谢datawhale提供的平台! 模型融合 在前面的特征工程中,特征融合也是一个重要的环节,而对于模型的融合也是一个相当重要的环节。俗话说:三个臭皮匠顶个诸葛亮 常见的模型融合有以下三大类型的方法 简单的加权融合:这部分比较好理解,光看名字就可以理解例如 回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometr

【RL】(task5)PPO算法和代码实现
note 文章目录 note一、RLHF对齐1. 训练奖励模型和RL2. RLHF3. 常见的公开偏好数据集 二、PPO近端策略优化1. PPO介绍2. PPO效果 二、PPO代码实践PPOmemoryPPO modelPPO update 时间安排Reference 一、RLHF对齐 1. 训练奖励模型和RL 用奖励模型训练sft模型,生成模型使用奖励或惩罚来更新策略,以便

【天池——街景字符识别】 Task5 模型集成
文章目录 集成学习方法深度学习中的集成学习DropoutTTASnapshot 结果后处理小节 集成学习方法 在机器学习中的集成学习可以在一定程度上提高预测精度,常见的集成学习方法有Stacking、Bagging和Boosting,同时这些集成学习方法与具体验证集划分联系紧密。 由于深度学习模型一般需要较长的训练周期,如果硬件设备不允许建议选取留出法,如果需要追求精度可以使用交
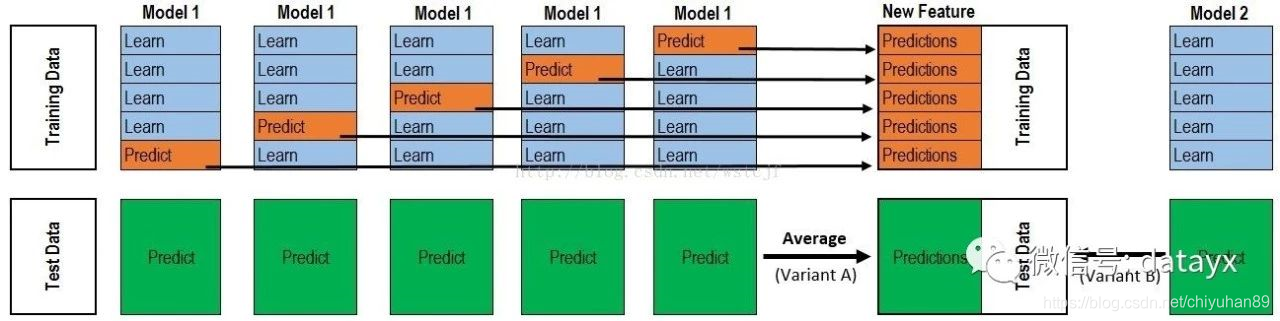
零基础入门数据挖掘 - 二手车交易价格预测 Task5
本次的任务是模型融合。 首先,搞明白什么是模型融合: 模型融合就是综合考虑不同模型的情况,并将它们的结果融合到一起。模型融合主要通过几部分来实现:从提交结果文件中融合、stacking和blending。 集成学习(Ensemble Learning) 在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到

【李宏毅深度学习】(task5)分类Classification
学习心得 (1)从optimization的角度,来说明相较於Mean Square Error,交叉熵Cross-entropy是被更常用在分类上 (2)网络设计技巧 【李宏毅深度学习】(task5)网络设计技巧1—Local Minimum和鞍点 【李宏毅深度学习】(task5)网络设计技巧2—Batch and Momentum 【李宏毅深度学习】(task5)网络设计技巧3—Adapti

【李宏毅深度学习】(task5)网络设计技巧3—Adaptive Learning Rate
学习心得 (1)AdaGrad算法在迭代过程中不断调整学习率,并让目标函数自变量中每个元素都分别拥有自己的学习率;自变量中每个元素的学习率在迭代过程中一直在降低(或不变)。 (2)RMSProp算法和AdaGrad算法不同在于,RMSProp算法使用了小批量随机梯度按元素平方的指数加权移动平均来调整学习率。 (3)Adam在RMSProp基础上对小批量随机梯度也做了指数加权移动平均。并且使用了偏

二手车交易价格预测_Task5_模型融合
模型融合_代码示例部分 #导入工具包 import numpy as npimport pandas as pdfrom sklearn import metricsfrom sklearn import linear_modelfrom sklearn.datasets import make_blobs # 这是打包好的波士顿房价数据集from sklearn import
