本文主要是介绍零基础入门数据挖掘 - 二手车交易价格预测 Task5,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本次的任务是模型融合。
首先,搞明白什么是模型融合:
模型融合就是综合考虑不同模型的情况,并将它们的结果融合到一起。模型融合主要通过几部分来实现:从提交结果文件中融合、stacking和blending。
集成学习(Ensemble Learning)
在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好)。集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。
- 数据集大:划分成多个小数据集,学习多个模型进行组合
- 数据集小:利用Bootstrap方法进行抽样,得到多个数据集,分别训练多个模型再进行组合
Boosting
是一种可以用来减小监督学习中偏差的机器学习算法。主要也是学习一系列弱分类器,并将其组合为一个强分类器。
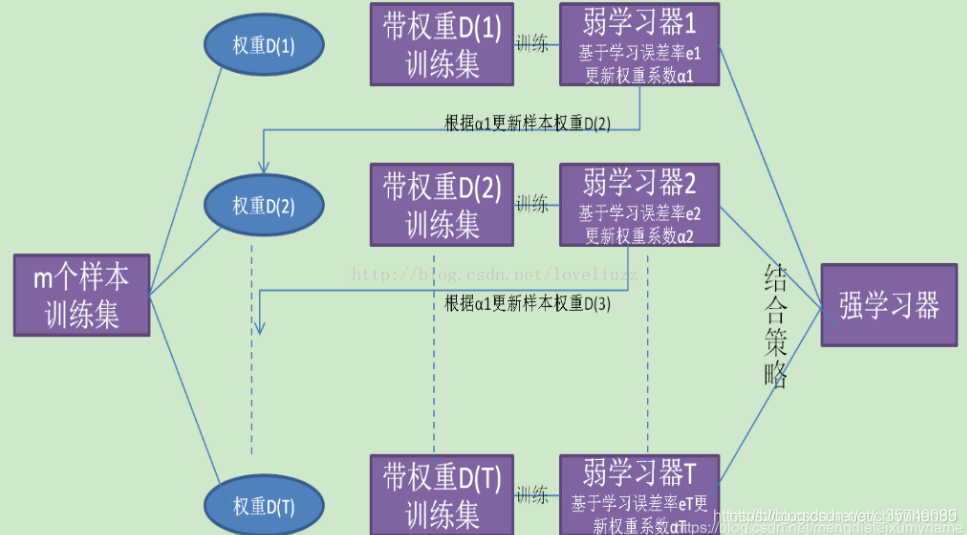
从图中可以看出,Boosting算法的工作机制是:
- 首先从训练集用初始权重训练出一个弱学习器1
- 根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视
- 基于调整权重后的训练集来训练弱学习器2
- 重复进行,直到弱学习器数达到事先指定的数目T
- 将这T个弱学习器通过集合策略进行整合,得到最终的强学习器。
bagging
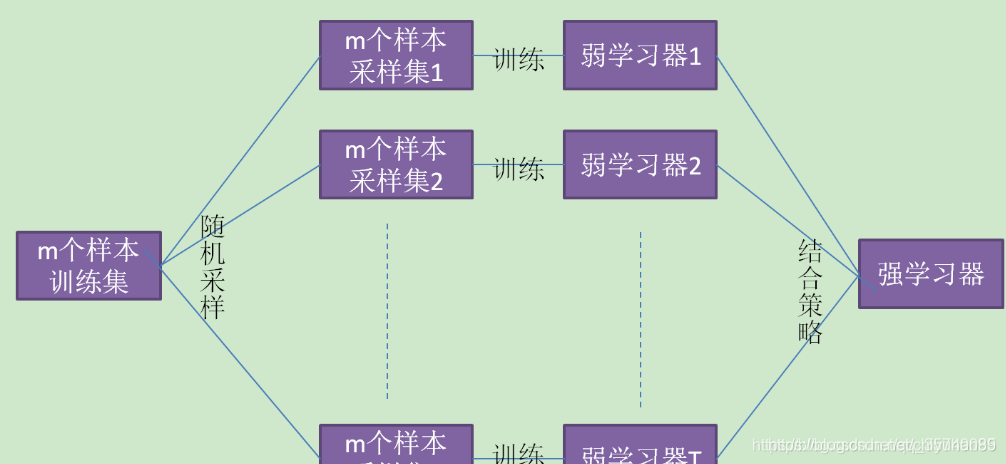
bagging的个体学习器的训练集是通过随机采样得到的。通过T次的随机采样,我们就可以得到T个采样集,对于这T个采样集,我们可以分别独立的训练出T个弱学习器,再对这T个弱学习器通过集合策略来得到最终的强学习器。这里的随机采样是采用Bootstrap自助有放回采样。
随机森林
随机森林(Random Forest)是在Bagging基础上做了修改,加上了属性的随机选择
- 从样本集中用Bootstrap采样选出n个样本
- 从所有属性中随机选择k个属性,选择最佳分割属性作为节点建立CART决策树
- 重复以上两步m次,即建立了m课CART决策树
- 这m个CART形成随机森林,通过投票表决结果,决定数据属于哪一类
一、简单加权融合
- 回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);
- 分类:投票(Voting)
- 综合:排序融合(Rank averaging),log融合
平均法(Averaging)
对于回归问题,一个简单直接的思路是取平均。稍稍改进的方法是进行加权平均。权值可以用排序的方法确定,举个例子,比如A、B、C三种基本模型,模型效果进行排名,假设排名分别是1,2,3,那么给这三个模型赋予的权值分别是3/6、2/6、1/6。
- 简单算术平均法:Averaging方法就多个模型预测的结果进行平均。这种方法既可以用于回归问题,也可以用于对分类问题的概率进行平均。
- 加权算术平均法:这种方法是平均法的扩展。考虑不同模型的能力不同,对最终结果的贡献也有差异,需要用权重来表征不同模型的重要性importance。
投票法(voting)
假设对于一个二分类问题,有3个基础模型,现在我们可以在这些基学习器的基础上得到一个投票的分类器,把票数最多的类作为我们要预测的类别。
- 绝对多数投票法:最终结果必须在投票中占一半以上。
- 相对多数投票法:最终结果在投票中票数最多。
- 加权投票法
- 硬投票:对多个模型直接进行投票,不区分模型结果的相对重要度,最终投票数最多的类为最终被预测的类。
- 软投票:增加了设置权重的功能,可以为不同模型设置不同权重,进而区别模型不同的重要度。
code
平均法:
1、生成一些简单的样本数据,test_prei 代表第i个模型的预测值, y_test_true 代表第模型的真实值
test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]y_test_true = [1, 3, 2, 6]
2、 定义结果的加权平均函数
import numpy as np
import pandas as pd# 定义结果的加权平均函数
def weighted_method(test_pre, w):weighted_result = 0.0for i in range(len(w)):weighted_result += pd.Series(test_pre[i]) * w[i]return weighted_result3、各模型的预测结果计算MAE
from sklearn import metricsprint('Pred1 MAE:', metrics.mean_absolute_error(y_test_true, test_pre1))
print('Pred2 MAE:', metrics.mean_absolute_error(y_test_true, test_pre2))
print('Pred3 MAE:', metrics.mean_absolute_error(y_test_true, test_pre3))
4、根据加权计算MAE
w = [0.3, 0.4, 0.3]
test_pre = [test_pre1,test_pre2,test_pre3]
weighted_result = weighted_method(test_pre, w)
print('Weighted_pre MAE:',metrics.mean_absolute_error(y_test_true, weighted_result))
通过结果可以发现,经过加权融合后的结果对比之前的结果有所提升,这就是简单的加权平均。
5、其他形式的平均(mean平均、median平均)。
# mean平均
def mean_method(test_pre):mean_result = pd.DataFrame(np.array(test_pre).T).mean(axis=1)return mean_resultmean_result = mean_method(test_pre)
print('Mean_pre MAE:',metrics.mean_absolute_error(y_test_true, mean_result))
# median平均
def median_method(test_pre):median_result = pd.DataFrame(np.array(test_pre).T).median(axis=1)return median_resultmedian_result = median_method(test_pre)
print('Median_pre MAE:',metrics.mean_absolute_error(y_test_true, median_result))
投票法
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.ensemble import VotingClassifierfrom sklearn.metrics import accuracy_score,roc_auc_score
from sklearn.model_selection import cross_val_score, train_test_splitfrom sklearn import datasets
iris = datasets.load_iris() # 使用著名的鸢尾花数据集
x = iris.data
y = iris.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)clf1 = XGBClassifier(learning_rate=0.1, n_estimators=150, max_depth=3, min_child_weight=2, subsample=0.7, colsample_bytree=0.6, objective='binary:logistic')
clf2 = RandomForestClassifier(n_estimators=50, max_depth=1, min_samples_split=4, min_samples_leaf=63,oob_score=True)
clf3 = SVC(C=0.1)
1、硬投票
eclf = VotingClassifier(estimators=[('xgb', clf1), ('rf', clf2), ('SVM', clf3)], voting='hard')
for clf, label in zip([clf1, clf2, clf3, eclf], ['XGBBoosting', 'Random Forest', 'SVM', 'Ensemble']):scores = cross_val_score(clf, x, y, cv=5, scoring='accuracy')print("Accuracy: %0.2f (+/- %0.2f)[%s]" %(scores.mean(), scores.std(), label))
2、软投票
eclf = VotingClassifier(estimators=[('xgb', clf1), ('rf', clf2), ('SVM', clf3)], voting='hard', weights=[2,1,1])
for clf, label in zip([clf1, clf2, clf3, eclf], ['XGBBoosting', 'Random Forest', 'SVM', 'Ensemble']):scores = cross_val_score(clf, x, y, cv=5, scoring='accuracy')print("Accuracy: %0.2f (+/- %0.2f)[%s]" %(scores.mean(), scores.std(), label))
二、Stacking/Blending:
Stacking:
简单来说 stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器。使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的。
如何进行Stacking?

用初始模型训练的标签再利用真实标签进行再训练,毫无疑问会导致一定的模型过拟合训练集,这样或许模型在测试集上的泛化能力或者说效果会有一定的下降,因此现在的问题变成了如何降低再训练的过拟合性,这里我们一般有两种方法。
- 次级模型尽量选择简单的线性模型
- 利用K折交叉验证
code
1、简单的Stacing融合(回归)
## 生成一些简单的样本数据,test_prei 代表第i个模型的预测值
train_reg1 = [3.2, 8.2, 9.1, 5.2]
train_reg2 = [2.9, 8.1, 9.0, 4.9]
train_reg3 = [3.1, 7.9, 9.2, 5.0]
# y_test_true 代表第模型的真实值
y_train_true = [3, 8, 9, 5] test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]# y_test_true 代表第模型的真实值
y_test_true = [1, 3, 2, 6] from sklearn import linear_modeldef Stacking_method(train_reg, y_train_true, test_pre, model_L2):model_L2.fit(train_reg.values, y_train_true)stacking_result = model_L2.predict(test_pre.values)return stacking_resultmodel_L2 = linear_model.LinearRegression()
train_reg = pd.DataFrame([train_reg1, train_reg2, train_reg3]).T
test_pre = pd.DataFrame([test_pre1, test_pre2, test_pre3]).T
stacking_pre = Stacking_method(train_reg, y_train_true, test_pre, model_L2)
print("Stacking_pre MAE:", metrics.mean_absolute_error(y_test_true, stacking_pre))
2、5-Fold Stacking
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier,GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import StratifiedKFolddata_0 = iris.data
data = data_0[:100, :]target_0 = iris.target
target = target_0[:100]# 模型融合中使用到的各个单模型(初级学习器)
clfs = [LogisticRegression(solver='lbfgs'),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]# 切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=2020)
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_predict.shape[0], len(clfs)))# 5折stacking
n_splits = 5
# StratifiedKFold 将X_train和 X_test 做有放回抽样,随机分5次,取出索引
skf = StratifiedKFold(n_splits)
skf = skf.split(X, y)# 依次训练单个模型
for j, clf in enumerate(clfs):dataset_blend_test_j = np.zeros((X_predict.shape[0],5))# 5折交叉训练,第i个部分作为预测,预测结果作为第i部分新特征,其余用来训练初级学习器for i, (train, test) in enumerate(skf):X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]clf.fit(X_train, y_train)y_submission = clf.predict_proba(X_test)[:, 1] # predict_proba返回的是一个n行k列的数组,(i,j)数值是模型预测第i个预测样本为某个标签的概率,并且每一行的概率和为1dataset_blend_train[test, i] = y_submissiondataset_blend_test_j[:, i] = clf. predict_proba(X_predict)[:, 1] dataset_blend_test[:, j] = dataset_blend_test_j.mean(1) # 1 对行求meanprint("val auc Score: %f" % roc_auc_score(y_predict, dataset_blend_test[:, j])) # roc曲线,需单独笔记clf = LogisticRegression(solver='lbfgs')
clf.fit(dataset_blend_train, y)
yy = clf.predict_proba(dataset_blend_test)
y_submission = clf.predict_proba(dataset_blend_test)[:, 1]print("Val auc Score of Stacking: %f" % (roc_auc_score(y_predict, y_submission)))
3、分类的Stacking融合(利用mlxtend)
mlxtend.regressor 中的StackingRegressor是一种集成学习元回归器
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.targetclf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3], meta_classifier=lr)label = ['KNN', 'Random Forest', 'Naive Bayes', 'Stacking Classifier']
clf_list = [clf1, clf2, clf3, sclf]fig = plt.figure(figsize=(10,8))
gs = gridspec.GridSpec(2, 2) # 画布分为两行两列
grid = itertools.product([0,1],repeat=2)clf_cv_mean = []
clf_cv_std = []
for clf, label, grd in zip(clf_list, label, grid):scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')print("Accuracy: %.2f (+/- %.2f) [%s]" %(scores.mean(), scores.std(), label))clf_cv_mean.append(scores.mean())clf_cv_std.append(scores.std())clf.fit(X, y)ax = plt.subplot(gs[grd[0], grd[1]])fig = plot_decision_regions(X=X, y=y, clf=clf)plt.title(label)plt.show()
Blending
- 对于一般的blending,主要思路是把原始的训练集先分成两部分,比如70%的数据作为新的训练集,剩下30%的数据作为测试集。
- 我们在这70%的数据上训练多个初级学习器,然后用余下的30%预测相应的P PP。
- 我们直接用这30%数据在第一层预测的PPP结合真实值,作为新特征继续训练次级学习器。
构建多层模型,并利用预测结果再拟合预测。
现在一般认为blending的融合是弱化版的stacking,是切分样本集为不相交的子样本然后用各个算法生成结果再融合,并且不适用交叉验证,这种方法不能够最大限度的利用数据,而stacking是得到各个算法训练全样本的结果再用一个元算法融合这些结果,效果会比较好一些,它可以选择使用网格搜索和交叉验证。
# Blending
iris = datasets.load_iris()
data_0 = iris.data
data = data_0[:100, :]target_0 = iris.target
target = target_0[:100]# 模型融合中使用到的各个单模型
clfs = [LogisticRegression(solver='lbfgs'),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),# ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]# 切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=2020)
# 将训练集切分为d1,d2两部分
X_d1,X_d2,y_d1,y_d2 = train_test_split(X,y,test_size=0.5,random_state=2020)
dataset_d1 = np.zeros((X_d2.shape[0], len(clfs)))
dataset_d2 = np.zeros((X_predict.shape[0], len(clfs)))for j, clf in enumerate(clfs):# 训练单个模型clf.fit(X_d1, y_d1)y_submission = clf.predict_proba(X_d2)[:,1]dataset_d1[:,j] = y_submission# 将原始数据集的测试集,放入初试学习器中,评价初试学习器好坏dataset_d2[:,j] = clf.predict_proba(X_predict)[:,1]print("val auc Score: %f" % roc_auc_score(y_predict, dataset_d2[:, j]))# 融合的模型
clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30)
clf.fit(dataset_d1, y_d2)
y_submission = clf.predict_proba(dataset_d2)[:,1]
print(print("Val auc Score of Blending: %f" % (roc_auc_score(y_predict, y_submission))))结合下图来看更香:
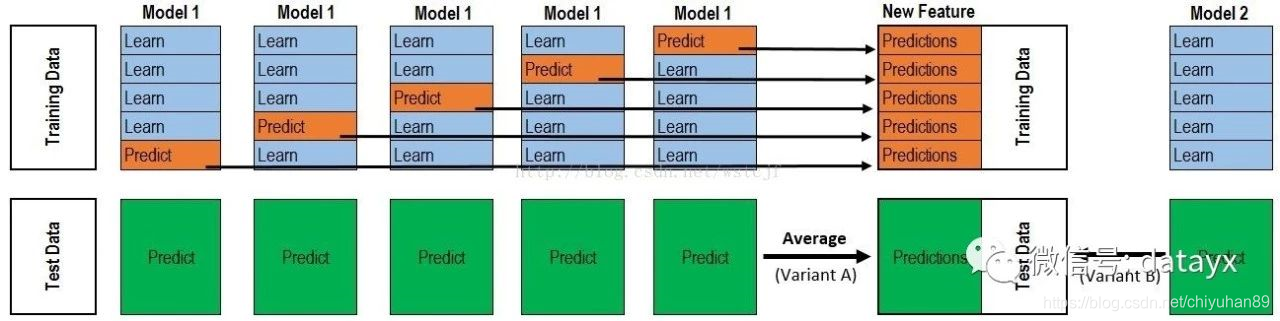
本赛题示例
1、构造数据集
data_train = pd.read_csv('used_car_train_20200313.csv', sep=' ')
data_test_a = pd.read_csv('used_car_testA_20200313.csv', sep=' ')numerical_cols = data_train.select_dtypes(exclude='object').columns
feature_cols = [col for col in numerical_cols if col not in ['SaleID','name','regDate','price']]data_X = data_train[feature_cols]
data_y = data_train['price']test_X = data_test_a[feature_cols]
2、查看数值特征
# 数值特征
def sta_inf(data):print('_min',np.min(data))print('_max:',np.max(data))print('_mean',np.mean(data))print('_ptp',np.ptp(data))print('_std',np.std(data))print('_var',np.var(data))
3、填充空值
data_X = data_X.fillna(-1)
test_X = test_X.fillna(-1)
4、模型构造
# 模型构造
def build_model_lr(x_train, y_train):reg_model = linear_model.LinearRegression()reg_model.fit(x_train, y_train)return reg_modeldef build_model_ridge(x_train, y_train):reg_model = linear_model.Ridge(alpha=0.8)#alphas=range(1,100,5)reg_model.fit(x_train, y_train)return reg_modeldef build_model_lasso(x_train,y_train):reg_model = linear_model.LassoCV()reg_model.fit(x_train,y_train)return reg_modeldef build_model_gbdt(x_train,y_train):estimator =GradientBoostingRegressor(loss='ls',subsample= 0.85,max_depth= 5,n_estimators = 100)param_grid = { 'learning_rate': [0.05,0.08,0.1,0.2],}gbdt = GridSearchCV(estimator, param_grid,cv=3)gbdt.fit(x_train,y_train)print(gbdt.best_params_)# print(gbdt.best_estimator_ )return gbdtdef build_model_xgb(x_train,y_train):model = xgb.XGBRegressor(n_estimators=120, learning_rate=0.08, gamma=0, subsample=0.8,\colsample_bytree=0.9, max_depth=5) #, objective ='reg:squarederror'model.fit(x_train, y_train)return modeldef build_model_lgb(x_train,y_train):estimator = lgb.LGBMRegressor(num_leaves=63,n_estimators = 100)param_grid = {'learning_rate': [0.01, 0.05, 0.1],}gbm = GridSearchCV(estimator, param_grid)gbm.fit(x_train, y_train)return gbm
5、XGBoost的五折交叉回归验证实现
# xbg
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, subsample=0.8, colsample_bytree=0.9, max_depth=7)
scores_train = []
scores = []# 5折交叉验证方式
sk = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
for train_ind, val_ind in sk.split(data_X, data_y):train_x = data_X.iloc[train_ind].valuestrain_y = data_y.iloc[train_ind]val_x = data_X.iloc[val_ind].valuesval_y = data_y.iloc[val_ind]xgr.fit(train_x, train_y)pred_train_xgb = xgr.predict(train_x)pred_xgb = xgr.predict(val_x)score_train = mean_absolute_error(train_y, pred_train_xgb)scores_train.append(score_train)score = mean_absolute_error(val_y, pred_xgb)scores.append(score)print('Train mae:',np.mean(score_train))
print('Val mae',np.mean(scores))
6、划分数据集,并用多种方法训练和预测
x_train, x_val, y_train, y_val = train_test_split(data_X, data_y, test_size=0.3)# train and predict
print('Predict LR:')
model_lr = build_model_lr(x_train, y_train)
val_lr = model_lr.predict(x_val)
subA_lr = model_lr.predict(test_X)print('Predict Ridge:')
model_ridge = build_model_ridge(x_train,y_train)
val_ridge = model_ridge.predict(x_val)
subA_ridge = model_ridge.predict(test_X)print('Predict Lasso:')
model_lasso = build_model_lasso(x_train,y_train)
val_lasso = model_lasso.predict(x_val)
subA_lasso = model_lasso.predict(test_X)print('Predict GBDT:')
model_gbdt = build_model_gbdt(x_train,y_train)
val_gbdt = model_gbdt.predict(x_val)
subA_gbdt = model_gbdt.predict(test_X)# 一般比赛中效果最为显著的两种方法
print('predict XGB...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
subA_xgb = model_xgb.predict(test_X)print('predict lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
subA_lgb = model_lgb.predict(test_X)
7、加权融合
def weighted_method(test_pre, w):weighted_result = 0.0for i in range(len(w)):weighted_result += pd.Series(test_pre[i]) * w[i]return weighted_result# init weight
w = [0.3, 0.4, 0.3]# 测试验证集准确度
test_pre = [val_lgb,val_xgb,val_gbdt]
val_pre = weighted_method(test_pre, w)
MAE_weighted = mean_absolute_error(y_val, val_pre)
print('MAE of Weighted of val:',MAE_weighted)# 预测部分数据
subA_pre = [subA_lgb,subA_xgb,subA_gbdt]
subA = weighted_method(subA_pre, w)
print('Sta inf:')
sta_inf(subA)# 生成提交文件
sub = pd.DataFrame()
sub['SaleID'] = test_X.index
sub['price'] = subA
sub.to_csv('sub_Weighted.csv', index=False)
8、 Stacking
# 第一层
train_lgb_pred = model_lgb.predict(x_train)
train_xgb_pred = model_xgb.predict(x_train)
train_gbdt_pred = model_gbdt.predict(x_train)Strak_X_train = pd.DataFrame()
Strak_X_train['Method_1'] = train_lgb_pred
Strak_X_train['Method_2'] = train_xgb_pred
Strak_X_train['Method_3'] = train_gbdt_predStrak_X_val = pd.DataFrame()
Strak_X_val['Method_1'] = val_lgb
Strak_X_val['Method_2'] = val_xgb
Strak_X_val['Method_3'] = val_gbdtStrak_X_test = pd.DataFrame()
Strak_X_test['Method_1'] = subA_lgb
Strak_X_test['Method_2'] = subA_xgb
Strak_X_test['Method_3'] = subA_gbdt# 第二层
model_lr_stacking = build_model_lr(Strak_X_train, y_train)# 训练集
train_pre_stacking = model_lr_stacking.predict(Strak_X_train)
print('MAE of Stacking-LR:',mean_absolute_error(y_train,train_pre_stacking))# 验证集
val_pre_stacking = model_lr_stacking.predict(Strak_X_val)
print('MAE of Stacking-LR:',mean_absolute_error(y_val,val_pre_stacking))# 预测集
print('Predict Stacking-LR...')
subA_Stacking = model_lr_stacking.predict(Strak_X_test)# 去除过小的预测值
subA_Stacking[subA_Stacking<10] = 10sub = pd.DataFrame()
sub['SaleID'] = data_test_a.SaleID
sub['price'] = subA_Stacking
sub.to_csv('sub_Stacking.csv', index=False)
总结
第一次参加这种组队学习,底子薄弱,感觉每天都在赶作业,不过收获很多,知道了整个流程,从数据探索到特征工程到建模调参到模型融合,真的很值得。
也通过这次学习,知道了自己的弱鸡,需要学习的东西太多太多了,统计、python缺一不可,只能说,慢慢来,多积累,加油啊!
接下来的时间,消化这次的学习,期待下次的组队。
这篇关于零基础入门数据挖掘 - 二手车交易价格预测 Task5的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







