数据挖掘专题

EI会议推荐-第二届大数据与数据挖掘国际会议(BDDM 2024)
第二届大数据与数据挖掘国际会议(BDDM 2024) 1、基本信息 大会官网:http://www.icbddm.org/ 官方邮箱:icbddm@163.com 主办方:武汉纺织大学 会议时间:2024年12月13日-12月15日 会议地点:湖北武汉 02征稿主题: 包含(但不限于)以下领域: 大数据:大数据分析、人工智能、大数据网络技术、大数据搜索算法和系统、分布式和点对

【数据分析案例】使用机器学习做游戏留存数据挖掘的一种尝试
案例来源:@深极智能 案例地址: https://zhuanlan.zhihu.com/p/31213553 1. 目标:针对K游戏数据,预测玩家留存情况,并找出影响留存的因素 2. 数据:玩家id,动作,动作时间戳,玩家关键属性(金币、装备、等级等) 3. 数据清洗: 1)剔除操作数<16的玩家,这类对游戏题材不感兴趣,非目
【校招面经】机器学习与数据挖掘常见面试题整理 part9
八十、SVM的核函数 from:https://blog.csdn.net/lihaitao000/article/details/51173459 SVM核函数包括线性核函数、多项式核函数、径向基核函数、高斯核函数、幂指数核函数、拉普拉斯核函数、ANOVA核函数、二次有理核函数、多元二次核函数、逆多元二次核函数以及Sigmoid核函数. 核函数的定义并不困难,根据泛函的有关理论,只要一种函数
【校招面经】机器学习与数据挖掘常见面试题整理 part8
七十六、t-SNE from:http://www.datakit.cn/blog/2017/02/05/t_sne_full.html t-SNE(t-distributed stochastic neighbor embedding)是用于降维的一种机器学习算法,是由 Laurens van der Maaten 和 Geoffrey Hinton在08年提出来。此外,t-SNE 是一种非
2015百度机器学习/数据挖掘工程师+自然语言处理工程师笔试题目
1.new 和 malloc 的区别。 new 返回指定类型的指针,并且可以自动计算所需要大小。 比如: int *p; p = new int; //返回类型为int* 类型(整数型指针),分配大小为 sizeof(int); 或: int* parr; parr = new int [100]; //返回类型为 int* 类型(整数型指针),分配大小为
数据挖掘工程师的面试问题与答题思路
一个Java程序可以认为是一系列对象的集合,而这些对象通过调用彼此的方法来协同工作。下面简要介绍下类、对象、方法和实例变量的概念。 对象:对象是类的一个实例,有状态和行为。例如,一条狗是一个对象,它的状态有:颜色、名字、品种;行为有:摇尾巴、叫、吃等。类:类是一个模板,它描述一类对象的行为和状态。方法:方法就是行为,一个类可以有很多方法。逻辑运算、数据修改以及所有动作都是在方法中完成的。实例变量


【视频讲解】数据挖掘实战:Python金融贷款模型分类潜在贷款客户
全文链接:https://tecdat.cn/?p=37521 原文出处:拓端数据部落公众号 分析师:Hengtao Fan 模型的存在依托于这样一个事实:基于概率的决策乃是最优之选。将概率转化为评分,能够便于对齐风险。而评分则是通过统计的方法来识别潜在客户,进而判断客户是否合乎心意。这里的 “合意” 由我们预先定义,可以涵盖诸如风险、收益率、响应率、续借意愿、违约后的偿还意愿等等诸多方

程序猿成长之路之数据挖掘篇——Kmeans聚类算法
Kmeans 是一种可以将一个数据集按照距离(相似度)划分成不同类别的算法,它无需借助外部标记,因此也是一种无监督学习算法。 什么是聚类 用官方的话说聚类就是将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。用自己的话说聚类是根据不同样本数据间的相似度进行种类划分的算法。这种划分可以基于我们的业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。 什么是K-m

机器学习和数据挖掘(9):线性模型
线性模型 非线性变换的代价 非线性变换回顾 在之前的文章中我们说过了非线性变换,我们有一个输入 x=(x0,…,xd) {\bf x}=(x_0,\dots,x_d),通过一个 Φ \Phi变化,我们将之投影到一个新的平面上去,得到 z=(z0,……,zd~) {\bf z}=(z_0,\dots\dots,z_{\tilde d})。例如, z=(1,x1,x2,x1x2,x21,x22)
机器学习和数据挖掘(8):偏见方差权衡
偏见方差权衡 偏见和方差 我们一直试图在近似和泛化之间找到一个平衡。 我们的目标是得到一个较小的 Eout E_{out},也希望在样例之外也表现得非常棒的 Eout E_{out}。复杂的假设集 H \mathcal H将有机会得到一个接近目标函数的结果。 VC维分析使用的是泛化边界来进行泛化。根据公式 Eout≤Ein+Ω E_{out}\leq E_{in}+\Omega,其中 Ei

机器学习和数据挖掘(7):VC维
VC维 回顾与说明 如果一个假设空间存在突破点,则一定存在成长函数 mH(N) m_{\mathcal H}(N)被某个上限函数 B(N,k) B(N,k)所约束,而上限函数等于一个组合的求和形式 ∑k−1i=0CiN \sum_{i=0}^{k-1}C_N^i,易知该形式的最高次项是 Nk−1 N^{k-1}。图左和右分别是以上限函数为上限的情况和以为 Nk−1 N_{k-1}上限的情况。

机器学习和数据挖掘(6):雷蒙保罗MAPA泛化理论
泛化理论 上一章中提到的生长函数 mH(N) m_{\mathcal H}(N)的定义:假设空间在 N N个样本点上能产生的最大二分(dichotomy)数量,其中二分是样本点在二元分类情况下的排列组合。 上一章还介绍了突破点(break point)的概念,即不能满足完全分类情形的样本点个数。不存在kk个样本点能够满足完全分类情形,完全二分类情形(shattered)是可分出 2N 2^N种

机器学习和数据挖掘(5):训练与测试
回顾与说明 不像上一章的学习流程图,我们这里假设可学习的数据来自于一个统一的分布(不考虑噪声的情况),且假设空间中的假设函数为有限个的情况下,其学习流程图如图所示。 我们这里假设训练样本和测试样本本来自同一的分布,并且假设空间的假设是有限的,即 |H|=M |\mathcal H| = M, M M是有限的值。在这种情况下,在训练样本N足够大,假设空间中的所有的假设都会遵循P
机器学习和数据挖掘(4):噪声与误差
噪声与误差 噪音(Noise) 实际应用中的数据基本都是有干扰的,还是用信用卡发放问题举例子: 噪声产生原因: 标记错误:应该发卡的客户标记成不发卡,或者两个数据相同的客户一个发卡一个不发卡;输入错误:用户的数据本身就有错误,例如年收入少写一个0、性别写反了什么的。 目标分布(Target Distribution) 上述两个原因导致数据信息不精准,产生噪声数据。那

机器学习和数据挖掘(3):线性模型
感知器模型 基本概念 线性可分:在特征空间中可以用一个线性分界面正确无误地分开两类样本;采用增广样本向量,即存 在合适的增广权向量 a 使得: 则称样本是线性可分的。如下图中左图线性可分,右图不可分。 所有满足条件的权向量称为解向量。权值空间中所有解向量组成的区域称为解区。 通常对解区限制:引入阈值threshold,要求解向量满足: aTy
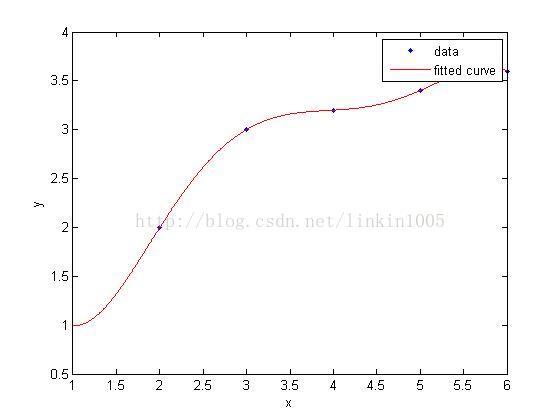
机器学习与数据挖掘(2):学习的可能性
误差理论 ① 偏倚(bias)和方差(variance) 在讨论线性回归时,我们用一次线性函数对训练样本进行拟合(如图1所示);然而,我们可以通过二次多项式函数对训练样本进行拟合(如图2所示),函数对样本的拟合程序看上去更“好”;当我们利用五次多项式函数对样本进行拟合(如图3所示),函数通过了所有样本,成为了一次“完美”的拟合。 图3建立的模型,在训练集中通过x可以

基于数据挖掘的消费者商品交易数据分析可视化与聚类分析
文章目录 ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==项目介绍项目实现实现流程实现过程数据预处理EDA探索性数据分析聚类分析每文一语 有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主 项目介绍 基于python的消费者商品交易数据分析与可视化主要包含以下内容: 首先探讨如何从各种渠道获取消费者商品交易数据,例如电子商务网站的API、

销售预测数据挖掘实战V2.0
1、概述 沃尔玛全年都会举办几次促销减价活动。这些减价活动都是在重要节假日之前进行的,其中最大的四个节假日是超级碗、劳动节、感恩节和圣诞节。包括这些节假日在内的几周在评估中的权重是非节假日周的五倍。在缺乏完整/理想历史数据的情况下,对这些节假日周的降价影响进行建模,是此次竞争所面临的部分挑战。我们提供了位于不同地区的 45 家沃尔玛商店的历史销售数据。 数据集信息 这是 2010-02-05
数据挖掘与分析 个别选择题ID3Apriori算法
选择题 1.当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?(聚类) 2.关于K-means算法,正确的描述是:初始值不同,最终结果可能不同 3.K-means算法中的初始中心点:直接影响算法的收敛结果 4.处理缺失值的方法包括:不处理、删除记录、插补法 5.神经网络的缺点包括:需要大量的参数,如网络拓扑结构权值和阈值的初始值等;输出的结果难以解释

Python--python数据挖掘领域工具包
原文:http://qxde01.blog.163.com/blog/static/67335744201368101922991/ Python在科学计算领域,有两个重要的扩展模块:Numpy和Scipy。其中Numpy是一个用python实现的科学计算包。包括: 一个强大的N维数组对象Array;比较成熟的(广播)函数库;用于整合C/C++和Fortran代码的工具包;实用的线性代数
数据挖掘与分析——数据预处理
数据探索 波士顿房价数据集:卡内基梅隆大学收集,StatLib库,1978年,涵盖了麻省波士顿的506个不同郊区的房屋数据。 一共含有506条数据。每条数据14个字段,包含13个属性,和一个房价的平均值。 数据读取方法: import pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sk
数据挖掘系列笔记(2):机器学习的应用实例
机器学习的应用领域非常广泛,而且随着VLSI技术的发展和大规模并行计算的推广,机器学习机器相关的大数据领域,再次成为研究的热点。 1. 学习关联性 从样本的空间中学习各种事件之间的关联性。以超市购物为例,X代表客户购买尿布的事件,Y代表客户购买奶粉的事件,则P(Y|X)代表客户在购买了尿布时,又购买了奶粉的概率。机器学习的一个任务就是,从一个大的样本空间之内,学习事件之间的关联性,以指导商业或
数据挖掘的Apriori算法
该算法是经典的频繁项集的挖掘算法,主要用的是一个先验性质,任何频繁项集的自己都是频繁的。反过来说,一个项集的有一个子集不是频繁的,那这个项集也不是频繁的。 算法的输入:(1)事务数据库D ID 购买的产品的编号 T100 1,2,3,4 T200 2,3,4,5 T300 1,2,7,5,4 T400 1,2,3,4,5,6,7,8
