本文主要是介绍零基础入门数据挖掘之心电图分类 Task5 建模融合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
此次学习是整个学习的最后一节。收获颇丰!感谢datawhale提供的平台!
模型融合
在前面的特征工程中,特征融合也是一个重要的环节,而对于模型的融合也是一个相当重要的环节。俗话说:三个臭皮匠顶个诸葛亮
常见的模型融合有以下三大类型的方法
- 简单的加权融合:这部分比较好理解,光看名字就可以理解例如
回归(分类概率):算术平均融合(Arithmetic mean),几何平均融合(Geometric mean);
分类:投票(Voting)
综合:排序融合(Rank averaging),log融合 - stacking/blending:本次blog主要学习这个给方法
- boosting/bagging :在前面的学习提到了
stacking
参考链接
stacking:stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的stacking模型。stacking的方法在各大数据挖掘比赛上都很风靡,模型融合之后能够小幅度的提高模型的预测准确度。
如图所示
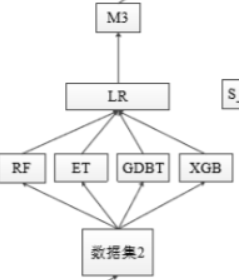
第一层,我们采用RF、ET、GBDT、XGB四种模型,分别对训练样本进行预测,然后将预测结果作为下一层的训练样本
具体过程:
- 划分training data为K折,为各个模型的训练打下基础;
- 针对各个模型RF、ET、GBDT、XGB,分别进行K次训练,每次训练保留K分之一的样本用作训练时的 检验,训练完成后对testing data进行预测,一个模型会对应5个预测结果,将这5个结果取平均;
- 最后分别得到四个模型运行5次之后的平均值,同时拼接每一系列模型对训练数据集的预测结果带入下一层;
第二层:将上一层的四个结果带入新的模型,进行训练再预测。第二层的模型一般为了防止过拟合会采用简单的模型。
具体训练过程:将四个预测结果,拼接上各个样本的真实label,带入模型进行训练,最终再预测得到的结果就是stacking融合之后的最终预测结果了。
blending
- Blending方式和Stacking方式很类似,相比Stacking更简单点,两者区别是:
Blending是直接准备好一部分10%留出集只在留出集上继续预测,用不相交的数据训练不同的 Base Model,将它们的输出取(加权)平均。实现简单,但对训练数据利用少了 - blending 的优点是:比stacking简单,不会造成数据穿越(所谓数据穿越,就比如训练部分数据时候用了全局的统计特征,导致模型效果过分的好),generalizers和stackers使用不同的数据,可以随时添加其他模型到blender中。
- 缺点在于:blending只使用了一部分数据集作为留出集进行验证,而stacking使用多折交叉验证,比使用单一留出集更加稳健。
一些其他方法
利用stacking的原理,将特征放进模型中预测,并将预测结果变换并作为新的特征加入原有特征中再经过模型预测结果 (Stacking变化)
代码如下
def Ensemble_add_feature(train,test,target,clfs):# n_flods = 5# skf = list(StratifiedKFold(y, n_folds=n_flods))train_ = np这篇关于零基础入门数据挖掘之心电图分类 Task5 建模融合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





