本文主要是介绍强化学习调参经验大集成:TD3、PPO+GAE、SAC、离散动作噪声探索、以及Off-policy 、On-policy 算法常见超参数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 强化学习通用参数设置
(1)强化学习算法选用
目前推荐的使用的算法主要是:
离散控制问题建议算法:
①D3QN——D3 指的是 Dueling Double DQN,主要集成了 Double DQN 与 Dueling DQN 的方法架构,另可与 Noisy DQN 来配合γ-greedy 方法来提升探索效率。
②SAC-Discrete——提出的主要目标是用于解决混合动作空间中的决策问题,将输出的动作矢量当作每个动作的执行概率,具体效果评价有高有低。
③H-PPO——H-MPO 都是基于离散空间信息处理的 PPO 算法。
连续控制问题建议算法:
PPO+GAE——PPO 是对 TRPO 的简化版,本身就具有调参简单、鲁棒性强特点。而 GAE 指 Generalized Advantage Estimation,会根据经验轨迹生成优势函数的估计值,而后让 Critic 拟合该值,达到利用少量 trajectory 描述当前策略的目标,经验发现 GAE 虽可与多种 RL 算法结合,但与 PPO 结合效果最佳,训练最稳定、调参最简单。
SAC(Automating Temperature Parameterα版)——通过自动调整温度系数来使策略熵保持动态平衡,但有经验指出不适合最优策略有大量边界动作的任务,即若最优策略下的动作大量达到边界值时效果会变差,例如在控制机器人移动时全速移动通常是最优解,则不适合使用 SAC 算法,这主要原因是 SAC 在计算策略熵时使用了 tanh() 的导数项作为修正,使得动作值接近 - 1、+1 边界值时计算误差非常大,导致梯度方向出现错误,详见 如何选择深度强化学习算法:MuZero/SAC/PPO/TD3/DDPG/DQN/等算法
。另 SAC 对 reward function 比较敏感,通常会进行 scaling 的方式调整大小。
TD3—— Twin Delay DDPG,是 DDPG 的升级版,依托确定性策略用于处理在连续动作空间中进行处理学习,一般经验是 TD3 敏感的超参数很多,更适合擅于调参的人使用。与 SAC 不同,如果最优策略通常是边界值,则首先的算法就是 TD3。
(2)强化学习网络架构
共识是强化学习不需要过深的网络,因为多数算法是基于在线学习方式的,过深的网络反而会造成学习难度过大、与环境变化难以契合。一般情况下,宽度选择 128、256,而不要超过 10 层(一些程序员表示 2~3 层足够,普遍表示不要超过 8 层),在进行层的计算时以 weight 为基准,因此 LSTM 视作 2 层。
(3)状态信息归一化处理
结论是针对状态信息,不要使用批归一化处理,但可以使用类似 running mean std 的归一化技巧,且鼓励使用层归一化处理。
①不建议使用批归一化。

深度强化学习算法是否需要使用批归一化(Batch Norm) 或归一化,文本带你详解。 文章中有深入的探讨,简单说来,是由于深度强化学习与基于固定数据集训练的有监督学习不同,是在与环境不断的交互中在线学习的,因而训练数据并不稳定,当数据变动过大时(即出现大量的全新状态信息),BN(批归一化)层原有的均值与方差来不及适应新的数据,从而造成价值函数与策略函数的崩溃,曾伊言用一张图形象地表示了二者的区别,如下图中绿色直线表示有监督学习过程中由于采样数据稳定,BN 是由不稳定趋于稳定的;但在强化学习过程中,由于数据是不稳定造成当 BN 趋向稳定后(如橙色曲线)可能因为数据的不稳定造成进一步失稳(如红色曲线),两条经线不断循环,造成彻底失稳。
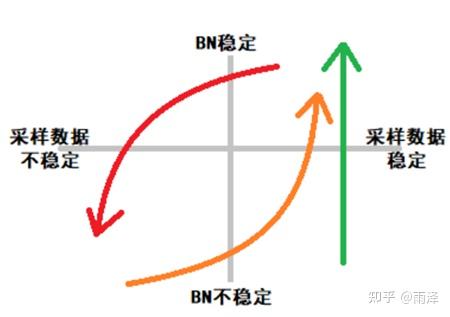
当然,并非所有实验条件下都会失稳,学界有一些研究也指出加入 BN 可以提升 RL 性能,这个分歧主要还是由于不同 RL 算法下状态采样变化频度不同所造成的,一般而言,RL 算法收敛快、学习效率高,则采样数据变化得快,加入 BN 后会带来负效果。
特例分析:使用批归一化的特例是自己状态转移与环境变化关系不大的情形,如你拿 100 元让强化学习智能体进行股票投资,根本不会对状态转移带来影响,则数据是可以使用批归一化的。
②建议使用 running mean std 的 trick
简单而言是构建一个随着批数据缓慢更新的均值与方差,并用于处理数据:
训练时
running_mean = (1 - momentum) * mean_old + momentum * mean_new
running_var = (1 - momentum) * var_old + momentum * var_new
测试时
running_mean = mean_old
running_var = var_old
先更新running_mean和running_var,再计算bn曾伊言提出更简单的技巧:
1.开始DRL的训练,然后将历史训练数据保存在经验回放 (relpay buffer) 里
2.训练结束后,计算 replay buffer 里 state 每个维度的均值和方差,结束整个训练流程
3.下一次训练开始前,对所有输入网络的state用固定的均值和方差进行归一化
4.重复一两次此过程实际在实现的过程中,将训练得到的状态值除以标准差再减去均值即可,可以节省大量性能开销。
③建议使用层归一化
层归一化的对象是神经元之间的张量数据,使其尽可能满足高斯白噪声化,可以直接使用 torch.nn.LayerNorm,按数据要求依次输入张量的各项参数即可,个人在实验中发现可以极大提升算法性能。
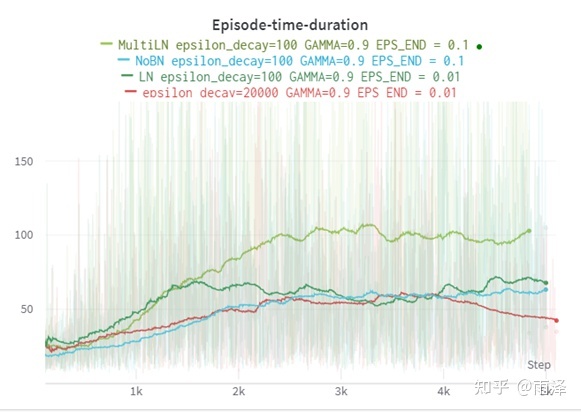
下图我基于图像像素的 Cartpole 实验,红色加入了 BN,蓝色为无 BN,深绿为加入了单层 LN,浅绿为加入了多层 LN,实验可以看出,BN 在训练后期带来的性能的下降,而 LN 取得了极好的效果。
(3)强化学习的 reward 设计
相比于状态信息的归一化,reward 不应执行归一化,可以进行放缩。而 Reward 设计主要针对两个方面,一个是每步均给出 Reward 值的辅助 Reward 设计,另一个是给出最终结果的最终 Reward 设计。
①Reward 值不可执行归一化
这是因为 reward 准确地对应于各个运作,加入归一化后使 reward 值减去均值,则在价值计算的过程中会难以避免地受到步长的影响,即随着时间步长按常数进行增加或减少,类似于在 reward 值会在奖励函数中引入非零常数的影响,使得贝尔曼公式 Q_t+1 = r_t + Q_t 存在了近似非零常数的影响,即 Q_t+1 = r_t + Q_t + c_t,造成智能体无需动作即能增加或减少 reward,破坏了环境的 reward function,从而造成价值函数与策略函数训练的困难。
特例分析:特例情况下,对 Reward 也可使用归一化,即当 Reward 不存在近似这种非零常数影响的前提下,则是可以对 Reward 使用归一化的,如智能体无论采取什么策略均不影响其在环境中的步数,即 reward 不会因为步数的长度改变,则可以引入批归一化处理。
②辅助 Reward 与最终 Reward 的设计原则
辅助 reward 属于在每个 step 均出现,用于引导智能体不断接近得到最终 reward,其主要设计原则有两个:
1 > 正负均衡,均负则智能体最终策略趋于保守,均为正则智能体最终策略,所以针对稠密的辅助 reward 值 R_tAsst 设计一定要正负均衡;
2 > 大小上不得影响最终 reward 值 R_tfinal,即其值在经γ帖现因子乘积后值应不大于最终 reward 值,因此需要首先对完成步数进行估计即 t_done,必须满足条件:R_tFinal > R_tAsst * (1 - γ)^ (t_done)
3> 辅助 reward 不可过大或过小,建议介于 - 1 到 +1 之间,而最终 reward 可以设置在满足最小条件的同规模数据上。
2.Off-policy 算法常见超参数
(1)γ-gamma 贴现因子
γ-gamma 其实描述的是智能体在做动作时需要考虑的 reward 的步数长,目前可以使用的两个经验公式分别是:
①t_len = 1 / (1 - gamma)
②gamma = 0.1^(1/t_len) ——》 t_len = (-lg(gamma))^-1其中γ趋近于 1,则在计算中考虑步数越多,越趋近于无穷,因此γ不能选择为 1,因为这样会将无穷远的 reward 也考虑近来。γ取 0 则表示不考虑任何未来步数的影响,只考虑当前步的 reward 值进行训练。
通常情况下,可将γ设为 0.99。
第①个贴现因子的公式其实是由 Q 值的近似推导得来的,将 Q 值视作基于均值 r 的多步乘积:

(2)Frame Skipping / Drop Rate/ Drop out
针对 Frame Skipping 的设计与γ其实是相辅相成的,经验公式告诉了我们智能体可以考虑的步数,但若状态信息太稠密,则可以丢掉一些信息,达到 “快进” 效果。经验建议是,在深度强化学习中并不建议使用 Drop Rate,即便使用也选择非常小的 dropout rate(0~0.2)。
(3)Buffer Size
大型网络的智能体训练,Replay Buffer 的 Memory Size 起始值可以设计在 2^17 至 2^20 之间(即 1e6 至 1e7 的规模之间),如果 Buffer Size 过小,则不利于对稀有样本的训练,而过大也会造成旧有样本在缓存中存留时间过长从而阻碍策略优化。
(4)Batch Size
Batch Size 的选取主要是为了兼顾训练的稳定性与训练速度,有建议选择与网络宽度相同或略大的 batch size,一般可以从 128、256 在 2^N 进行尝试。建议将 Replay Buffer 的大小与 Replay 的数据量成一定的比例经验公式如下:
replay_max = 'the maximum capacity of replay buffer'
replay_len = len(ReplayBuffer)
k = 1 + replay_len / replay_max
batch_size = int(k * basic_batch_size)(5)Update Times 更新次数
更新次数也同样应与 Replay 的数据量成比例,经验公式如下:
replay_max = 'the maximum capacity of replay buffer'
replay_len = len(ReplayBuffer)
k = 1 + replay_len / replay_max
update_times = int(k * basic_update_times)
for _ in range(update_times):data = ReplayBuffer.random_sample(batch_size)...3. On-policy 算法常见超参数
由于 on-policy 是利用 replay buffer 中相同策略产生数据来更新策略网络的,所以部分超参数在设计上与 off-policy 具有天然地不同。
(1) Buffer Size
应大于等于单轮同一策略采样步数
(2) Batch Size
有关经验建议是 on-policy 方法使用稍大的学习率(2e-4,即 0.0002)以及更大的 batch size(2^9 ~ 2^12)且对于难调参的任务 batch size 可以设置得更大(2^14)些,更易获得单调上升的学习曲线
(3)Update Times
在线学习的更新次数也是可以通过单轮更新采样步数 step、batch size、以及数据重用次数 reuse time 来直接计算得到:
update_times = steps * reuse_times / batch_size4. 离散动作常用超参数
(1)使用 Epsilon-Greedy 策略探索
通常情况下使用的是 epsilon decay 的方法,即初始ε值相对较大,使策略更随机便于探索,随时间增加后ε值不断衰减至某一固定值:
EPS_START = 0.9
EPS_END = 0.05 # Never less than 0.1
EPS_DECAY = 1000
EPS_threshold = EPS_START
EPS_threshold = EPS_END + (EPS_START - EPS_END) * exp(-1. * steps_done / EPS_DECAY)退火(缩小与放大的周期性变化),一些博主尝试过并无特别效果,不建议使用。
(2)使用 Noisy 的策略探索
在网络中添加噪声得出带噪声的 Q 值,配合ε贪心策略使用,可以探索更多 Q 值更高的动作从而增加探索效率,但一些 Q 值更低的动作可能被覆盖,经验建议是噪声方差从 0.2 开始调整观察不同动作下 Q 值的方差辅助调参。
(3)输出离散动作的执行概率
利用 softmax 在输出动作 Q 值时额外输出执行概率,使智能体自行决策探索方式。
5. 连续动作相关超参数
①OU-noise (Ornstein-Uhlenbeck 噪声)——有评价指出 OU 噪声适用于惯性环境,或需要偷嘴的猫儿性不改实际机器人时,但大多实验条件下由于其带来了更多的超参数,多数不建议使用。
②连续动作空间值范围——建议选择 - 1~+1,无需为物理含义选择其他区间值。
6. 部分算法特有超参数
(1)TD3 我有超参数
①探索噪声方差 exploration noise std——先尝试较小值如 0.05,而后逐渐增大,一般不会超过 0.5,过大的噪声训练出来的智能体会让探索动作更接近单一的边界动作,也会临别秋波智能体性能,导致不容易探索到一些状态。
②策略噪声方差 policy noise std——策略噪声一般只需比探索噪声大 1~2 倍,其目的是使 Q 值函数更加光滑,提高训练稳定性,同时也结合可以使用加权重要性采样算出更稳定的 Q 值期望,策略噪声方差最大值也不应超过 0.5。
③延迟更新频率 delay update frequency——延迟更新主要是为了提升 network 的稳定性,因此当环境随机因素多的情形下,需要尝试更大延迟更新频率,如 1~8;提供策略梯度的 critic 可以多更新几次后再更新一次 actor,可尝试值为 1~4;提供策略梯度的 critic 可以有更大的学习率,如让 critic 学习率是 actor 的 0.1~1 倍;由于 critic 需要 处理比 actor 更多的数据,建议 critic 网络宽度略大于 actor。
④鼓励边界动作探索方法——将策略网络输出张量经激活函数 tanh 调整到 (-1, +1);为输出的动作添加 clip 过的高斯噪声;对动作再进行一次 clip,将其调整到 (-1, +1)。
(2)PPO+GAE 超参数
①单轮更新的采样步数 sample step——指同策略下的一轮数据规模,在随机因素大的环境中需要加大采样步数,值一般为 2 的倍数,如 1024、2048、4096 等。通常环境是具有终止状态的,一般会在达到规定采样步数后继续采样,直到遇到终止状态,从而每段 trajectory 的完整性,同时方便 reward 结算。
②数据复用次数 reuse times——由于 PPO 只在 trust region 内更新,使得新旧策略差异一起限制在某个范围内,只要差异不太大,那么作为 on-policy 算法就能复用训练数据。而 Repaly buffer 中的每个样本的使用次数主要与学习率、batch size 以及拟合难度有关,由于深度强化学习通常使用比深度学习更小的学习率,如(1e-3~1e-4),建议先尝试偏小的数值避免过拟合的情况出现。如在 batch size 为 512 的情况下,复用次数建议选 8。如果放宽了对新旧策略的限制,动态鼓励探索,则需要减少 repeat times,防止新旧策略差异过大。
③限制新旧策略总体差异系数 lambda entropy ——推荐默认值罚 0.01,一般可选范围在 0.005~0.05,该值越大,则新旧策略越不同,过大时甚至会使得学习曲线下降。
④估计优势函数的裁剪 clip epsilon——即 clip ε,默认值为 0.2,通常值为(0.1~0.3),ratio 越小则信任域越窄,策略更新越谨慎。
⑤GAE 调整方差与偏差系数 lambda advantage——默认值为 0.98,可选值一般在 0.96~0.99,调整λ advantage 的目的是在方差与偏差之间取得均衡,使其覆盖
(3)SAC 特有超参数
①奖励放缩 reward scale ——直接让 reward 乘以一个常数 k,在不破坏 reward function 的前提下调整 reward 值,从而间接调整 Q 值到合适大小,经验上进行 reward 目标调整的值主要是将整个 epsiode 的累积收益范围落在 - 1000 ~ +1000 以内,另也建议 Q 值的绝对值小于 256,100 以内时更方便神经网络拟合。
②温度系数 alpha (目标策略熵 target entropy)——第二版的 SAC 已经加入了温度系数α的自动调整机制,使得策略熵维持在目标熵附近,不因过大而影响优化,也不因过小而影响探索。策略熵与目标熵对 SAC 一般不敏感,采用默认值即可:
策略熵 policy_entropy = log_prob = -log(sum(...))
目标熵 target_entropy = -log(action.shape)有时策略的熵过大导致智能体无法探索到优势的 state,则需要 将目标熵调小。
③温度系数学习率——α最好使用 log 形式进行优化,学习率与网络参数的学习率应保持一致,一般为 1e-4,当环境随机因素过大导致每个 batch 算出来的策略熵 log_prob 不稳定时,则需要调小温度系数的学习率。
④温度系数初始值——α的初始值可以随意设置,一般均能自动调整到合适的值,设置为 log(1) 会延长 SAC 预热时间,经验是选择更小的值使得计算出来 Q 值的大小绝对值在 128 范围内。
文章在学习过程中主要参考了以下作者的成果,在此一并致谢。
深度强化学习调参技巧:以 D3QN、TD3、PPO、SAC 算法为例(有空再添加图片)
WYJJYN:深度强化学习落地方法论(7)—— 训练篇
强化学习需要批归一化 (Batch Norm) 或归一化吗?
如何选择深度强化学习算法?MuZero/SAC/PPO/TD3/DDPG/DQN / 等)
WYJJYN:深度强化学习落地方法论(3)—— 算法选择篇
Weyman:强化学习中 Ornstein-Uhlenbeck 噪声是鸡肋吗?
https://github.com/AI4Finance-Foundation/ElegantRL/issues/10
这篇关于强化学习调参经验大集成:TD3、PPO+GAE、SAC、离散动作噪声探索、以及Off-policy 、On-policy 算法常见超参数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


