policy专题

第十五章 WS-Policy 配置类详细信息 - 配置 XData 块的详细信息(二)
文章目录 第十五章 WS-Policy 配置类详细信息 - 配置 XData 块的详细信息(二)`<method>``<request>``<response>` 第十五章 WS-Policy 配置类详细信息 - 配置 XData 块的详细信息(二) <method> <method> 元素将策略与父 <service> 元素指定的 Web 服务或客户端内的特定 Web 方法

强化学习实践(二):Dynamic Programming(Value \ Policy Iteration)
强化学习实践(二):Dynamic Programming(Value \ Policy Iteration) 伪代码Value IterationPolicy IterationTruncated Policy Iteration 代码项目地址 伪代码 具体的理解可以看理论学习篇,以及代码中的注释,以及赵老师原著 Value Iteration Policy Itera

mysql密码策略修改(password does not satisfy the current policy requirements)
1.查看当前策略.SHOW VARIABLES LIKE 'validate_password%'; 2.修改策略 等级改为最低:set global validate_password_policy=LOW; 长度改为6:set global validate_password_length=6;

MySQL对设置密码进行了默认的限制(policy = 1)的含义
MySQL对设置密码进行了默认的限制(policy = 1)。 表格内容应该改成如下所示: Policy Tests Performed 0 or LOW Length 1 or MEDIUM Length; numeric, lowercase, uppercase, and special characters 2 or STRONG Length; numer

AFNetworking 提示The resource could not be loaded because the App Transport Security policy requires
原因:iOS9以后,苹果把原http协议改成了https协议,所以不能直接在http协议下GET/POST 解决方案之一: 直接编辑工程文件下的Info.plist文件,加入以下代码 <key>NSAppTransportSecurity</key> <dict> <key>NSAllowsArbitraryLoads</key><true/> </dict> 如图
MySQL8修改密码报错ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
目录 一、问题描述二、解决方法1.查看密码策略2.修改密码策略为 LOW3.修改密码长度为 6 一、问题描述 MySQL8 修改密码报错:ERROR 1819 (HY000): Your password does not satisfy the current policy requirements 二、解决方法 1.查看密码策略 show variables li
Policy-Based Reinforcement Learning(1)
之前提到过Discount Return: Action-value Function : State-value Function: (这里将action A积分掉)这里如果策略函数很好,就会很大;反之策略函数不好,就会很小。 对于离散类型: 用神经网络近似策略, 即 学习参数,使得越来越大。这里使用梯度上升的方法,对于一个可观测状态s,更新 这里称为策略梯度(P

springbootajaxhas been blocked by CORS policy: No ‘Access-Control-Allow-Origin
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到教程。 ajax+springboot解决跨域问题,以下报的错误就是html跨域的问题 Access to XMLHttpRequest at 'http://localhost:8080/user/login1' from origin 'http://localhost:59033' has bee
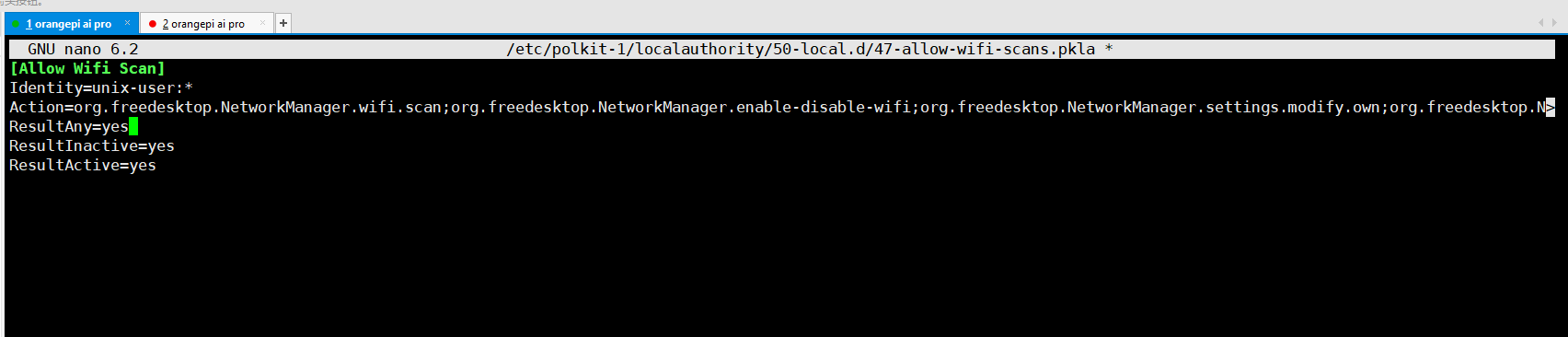
【问题随记】System policy prevents Wi-Fi scans,解决连接 WIFI 需要权限的问题
问题随记 System policy prevents Wi-Fi scans,每次打开我的开发板连接 wifi 都会出现下面的弹窗,这也阻挡了我的WIFI自动连接,然后就需要连上屏幕,输入 wifi 密码,这样才能进行 VNC、SSH 等一系列的连接。 问题解决 创建并编辑 47-allow-wifi-scans.pkla 文件 打开终端并使用管理员权限创建和编辑文件 /etc/po

WEB安全:Content Security Policy (CSP) 详解
Content Security Policy (CSP) 是一种强大的网页安全机制,用于防止跨站脚本 (XSS) 和其他注入攻击。通过设置一系列的内容安全策略,CSP 可以限制网页可以加载的资源,从而保护用户数据和网站的安全性。 什么是 XSS 攻击? 跨站脚本攻击 (XSS) 是一种常见的安全漏洞,攻击者通过注入恶意脚本来劫持用户会话、破坏网站内容或进行钓鱼攻击。XSS 攻击主要分为三

(笔记)CentOS7 Failed to load SELinux policy. Freezing的解决方案
1. 在这个界面按 'e' 进入 grub编辑界面 2. 在编辑界面添加 selinux=0 或者enforcing=0 添加完之后按下Ctrl + X 进入启动界面 3. 进入桌面后,打开终端并输入 vim /etc/selinux/config 将SELINUX=enforcing改成SELINUX=disabled并保存退出 希望能帮到你
强化学习算法中on-policy和off-policy
强化学习算法中on-policy和off-policy On-PolicyOff-Policy对比总结示例:SARSA vs Q-LearningSARSA实现Q-Learning实现 结论 在强化学习中,策略(policy)是智能体选择动作的规则。根据策略更新的方式,强化学习算法可以分为on-policy和off-policy两类。这两种类型的主要区别在于它们如何使用和更新策

Offline RL : Beyond Reward: Offline Preference-guided Policy Optimization
ICML 2023 paper code preference based offline RL,基于HIM,不依靠额外学习奖励函数 Intro 本研究聚焦于离线偏好引导的强化学习(Offline Preference-based Reinforcement Learning, PbRL),这是传统强化学习(RL)的一个变体,它不需要在线交互或指定奖励函数。在这个框架下,代理(agent)被提

1.3 基础知识——GP2.1 方针(Policy)
摘要: 方针这个GP每个PA都有,其实CMMI实践有没有实在价值,就在于方针!如果我们做出来的CMMI实践仅仅就是写文档、多步骤、没事找事,那其实就是违背了公司的商业目标,公司的商业目标简单说就是:用简单有效的办法多赚钱!如果你的CMMI实践达不到这个目标,其实就是方针出了问题。 GP2.1 方针 对每一个PA,公司都应该有相应的高层次的要求来指导该方面的工作,也就是所谓的方针。方针
android6.0系统缺少com.android.internal.policy.PolicyManager导致无法获取LayoutInflater实例问题
问题出现原因: 插件技术动态加载View需要实例化一个LayoutInflater,但6.0以后com.android.internal.policy.PolicyManager被去除,导致插件view无法被创建,为了能让我的app能够在6.0系统上运行,我必须解决掉这个bug 解决办法: 搜素源码找到这个类: https://android.googlesource.com/platfo
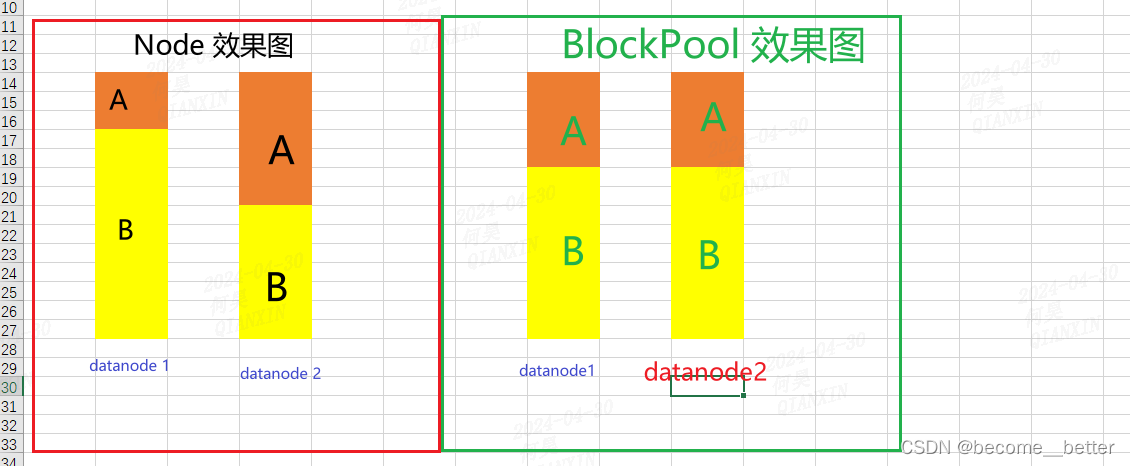
hdfs balancer -policy
hdfs balancer -policy当前有两种,datanode(默认):如果每个数据节点是平衡的,则集群是平衡的。blockpool:如果每个datanode中的每个块池都是平衡的,则集群是平衡的。 代码区别:计算方式不同,一个使用datanode 的使用量,一个使用自己blockpool的使用量。 理想效果
强化学习-MAPPO算法解析与实践-Multi Agent Proximal Policy Optimization
一 算法简介 mappo 是一种将ppo算法扩展到多智能体情况的算法,在讨论过这种算法的论文中,比较有名和权威的是Nips2021上发表的《The Surprising Effectiveness of PPO in Cooperative》。比较遗憾的是,可能作者出于自己不是最早提出mappo算法的人的原因,论文中并没有将mappo算法的具体实现作详细介绍(而最早提出mappo
深度强化学习系列tensorflow2.0自定义loss函数实现policy gradient策略梯度
本篇文章利用tensorflow2.0自定义loss函数实现policy gradient策略梯度,自定义loss=-log(prob) *Vt现在训练最高分能到193分,但是还是不稳定,在修改中,欢迎一起探讨文章代码也有参考莫烦大佬的代码action_dim = 2 //定义动作state_dim = 4 //定义状态env = gym.make('CartPole-v0')class
Web Services Platform Architecture : SOAP, WSDL, WS-Policy, WS-Addressing, WS-BPEL, WS-Reliable Mess
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Web Services Platform Architecture covers the entire platform. The authors illuminate every specification
Access Denied: The Practice and Policy of Global Internet Filtering
版权声明:原创作品,允许转载,转载时请务必以超链接形式标明文章原始出版、作者信息和本声明。否则将追究法律责任。 http://blog.csdn.net/topmvp - topmvp Many countries around the world block or filter Internet content, denying access to informationoften ab
强化学习 | Off-policy 和 On-policy直观理解
如是我闻: 在机器学习领域,特别是在强化学习中,“off-policy” 和 “on-policy” 是两种不同的学习策略,它们决定了智能体如何从环境中学习和做出决策。下面我们通过学做饭的例子比喻来理解这两种策略。 做饭 (真是太生动形象啦) On-policy 学习: 想象我们在学习做饭。在On-policy学习中,我们只能通过亲自做饭并尝试你的菜肴来学习。我们根据自己的食谱尝试做菜,然后

【强化学习的数学原理-赵世钰】课程笔记(九)策略梯度方法(Policy Gradient Method)
目录 一.policy gradient 的基本思路(Basic idea of policy gradient) 二.定义最优策略的 metrics,也就是 objective function 是什么 三.objective function 的 gradient 四.梯度上升算法(REINFORCE) 五.总结 上节课介绍了 value function approxim

同源政策(same-origin policy)
前言 浏览器同源政策(Same-origin policy) 是浏览器安全的基石。它是前端开发人员必须要理解的一个知识点,也是后面各种实现跨域资源访问方式学习的基础。在接触这方面的知识时个人思考很多,在此记录一下。只能看作是个人的当前理解,并不代表一定准确,如果有误,希望指出。 1. 同源的定义 学习同源政策之前我们先明确一下同源的概念。在浏览器中,如果两个页面(请求)拥有相同的协议、域名和

「off-policy强化学习」被低估!Google Brain等提出使用off-policy算法的「机器人抓取」任务基准
本文转自雷克世界(ID:raicworld) 编译 | 嗯~阿童木呀 在本文中,我们探讨了用于基于视觉的机器人抓取操作的深度强化学习算法。无模型深度强化学习(RL)已经在一系列具有挑战性的环境中得到了成功应用,但算法的激增使得我们难以辨别出哪种特定的方法最适合于执行一个丰富的、多样化的任务,例如抓取。为了回答这一问题,我们提出了一个机器人抓取的模拟基准,强调了对于没见过的目标的策略学习和

mysql修改密码提示: Your password does not satisfy the current policy requirements
1、问题概述? 环境说明: Red Hat Enterprise Linux7+mysql5.7.10 执行如下语句报错: set password for 'root'@'localhost' = password('123456'); ERROR 1819 (HY000): Your password does not satisfy the current policy
oslo_policy学习小结
0 公共方法 0.1 Enforcer.load_rules(self, force_reload = False) #从policy_file加载policy规则 判断是否force_reload,若是,将self.use_conf设为True 调CONF.find_file寻找组件对应的policy.json,找到的话将self.policy_path设为找到的文件路径 然后判断pol