本文主要是介绍强化学习-MAPPO算法解析与实践-Multi Agent Proximal Policy Optimization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一 算法简介
mappo 是一种将ppo算法扩展到多智能体情况的算法,在讨论过这种算法的论文中,比较有名和权威的是Nips2021上发表的《The Surprising Effectiveness of PPO in Cooperative》。比较遗憾的是,可能作者出于自己不是最早提出mappo算法的人的原因,论文中并没有将mappo算法的具体实现作详细介绍(而最早提出mappo的论文又没有附上代码),我们只能根据其提供的代码和论文中粗略的描述来进行学习。
1. 网络结构
和单智能体ppo算法一样,mappo算法中每个智能体都有各自的actor 网络和 critic网络(如果所有智能体的状态空间和动作空间也相同,即同构,也可以所有智能体共享一套actor和critic网络)。与单智能体ppo不同的是,mappo的critic网络可以接收有关全局状态的信息,这个全局状态可以是由所有智能体的观察拼接而成,也可以是环境直接提供。
2.损失函数
和单智能体ppo算法一样,损失函数由acrot loss和critic loss组成
actor loss 为 最小化负的代理在当前策略下的预期累积奖励
critic loss 为 回报和状态价值函数的均方差
3.采样和更新方式
关于采样和更新,论文中没有介绍细节,本段从代码中总结。
3.1采样
如智能体间不共享参数,即每个智能体有各自的actor和critic网络,则给每个智能体建立一个replaybuffer,将该智能体交互中获得的 st,at,r,st+1 存入对应的replaybuffer中。另在replaybuffer中增加mask 组,记录每一时刻智能体是否存活,以便后续死亡的智能体后续数据不用于更新网络。一般情况下,不同智能体间不共享奖励。
每个智能体决策时,可以不把其他智能体的动作加入观察,可以正常收敛。
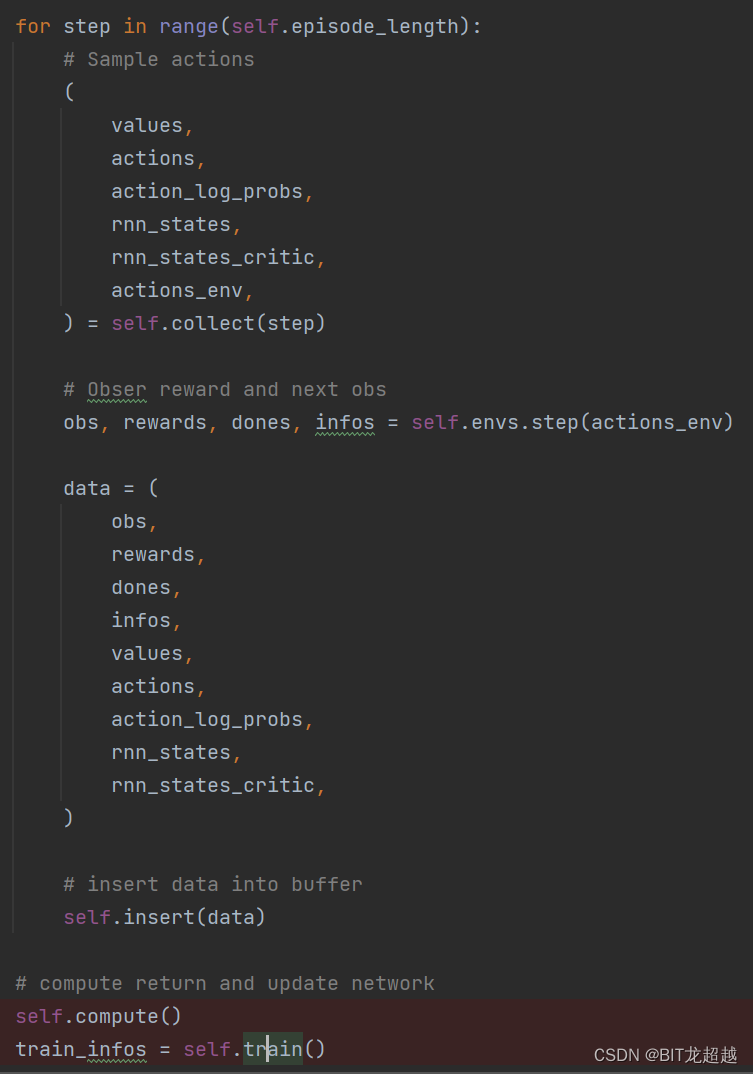
图一:env_runner.py中采样过程
3.2更新
如智能体间不共享参数,则针对每一个智能体分别从replaybuffer中抽样,训练其网络,其更新函数与ppo更新函数整体一致,出了增加了GAE、value normlization等trick
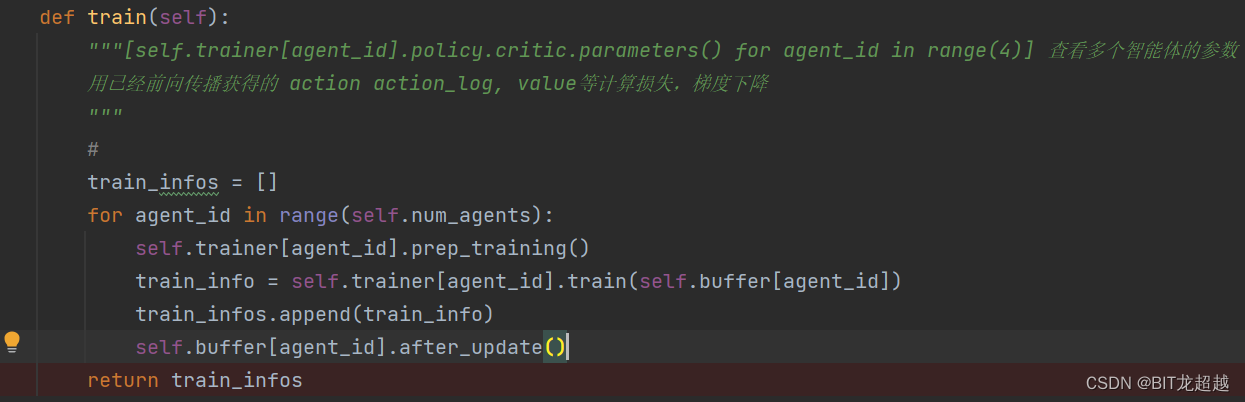
图二:base_runner.py中采样过程
4.必要的trick
4.1 GAE和Value Normalization
论文中虽未对网络做出具体介绍,但是使用的trick给了很多笔墨。GAE和Value Normalization就是其中之二,也是最通用的两个trick。GAE是对价值函数的一种平衡方法,价值函数V的评估方法中,一步TD的方差小,偏差大,而蒙特卡洛法的偏差小,方差大,为了结合两种算法,GAE(generalized advantage estimator)是对优势函数A的估计,它用从TD(0) 到TD(n)的加权和表示V,进而估计优势函数A,TD(0) 到TD(n)权重之和是一, n代表改慕结束的步数。【有点像离线 λ 回报算法思想】
Value Normalization是在训练时对critic网络输出的V值归一化,即减去均值除以方差,作者认为这样使得训练更加稳定。但是在计算GAE时又对归一化的V反归一化恢复了原值。
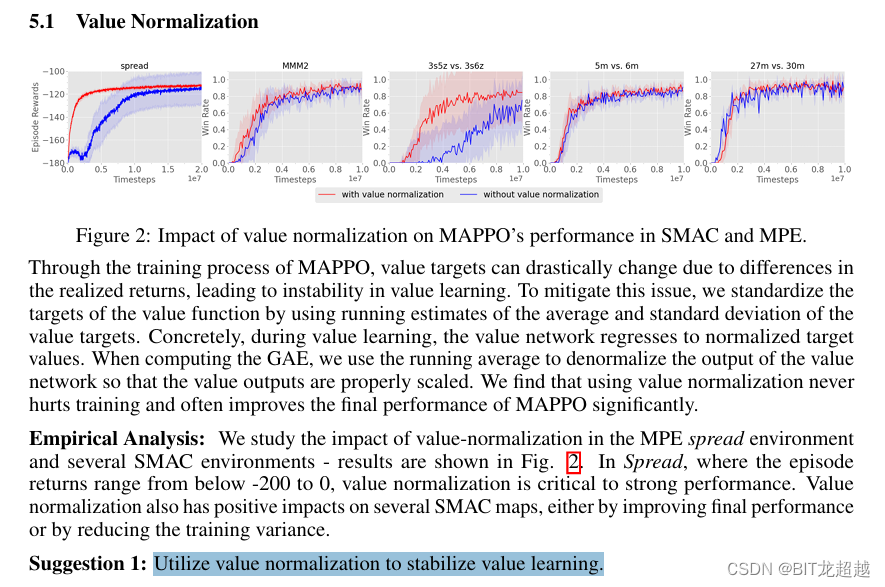
图三:MAPPO论文中关于Value Normalization
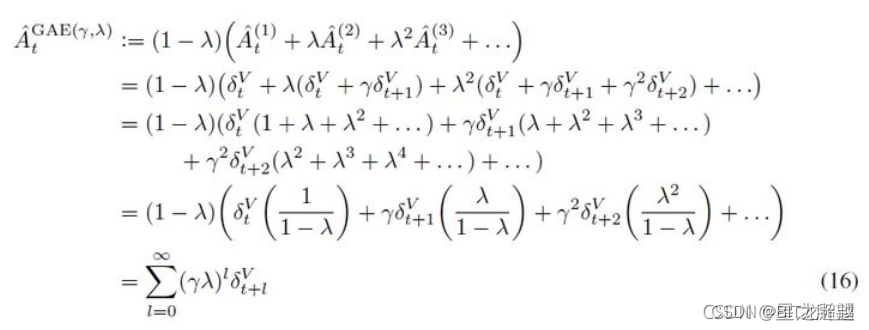
图四:GAE公式来自CSDN@星之所望
4.2其他trick
论文中还包括其他trick,通用性和重要度不如4.1,不再详细展开分别为:
建议1:When available, include both local, agent-specific features and global features in the value function input. Also check that these features do not unnecessarily increase the input dimension.
建议2:Use at most 10 training epochs on difficult environments and 15 training epochs on easy environments. Additionally, avoid splitting data into mini-batches
建议3:For the best PPO performance, maintain a clipping ratio ϵ under 0.2; within this range, tune ϵ as a trade-off between training stability and fast convergence
建议4:Utilize a large batch size to achieve best task performance with MAPPO. Then, tune the batch size to optimize for sample-efficiency.
二 算法实践
1.环境介绍
使用ma_gym 环境中的combat环境进行实践,该环境可从github下载
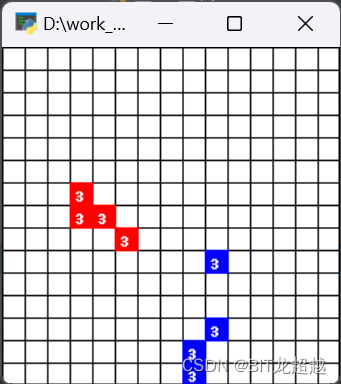
ma-gym 库中的 Combat 环境。Combat 是一个在二维的格子世界上进行的两个队伍的对战模拟游戏,每个智能体的动作集合为:向四周移动格,攻击指定敌方智能体(因而动作空间随敌方智能体增多增多,动作空间维数=4+n+1,4代表上下左右移动,n代表攻击敌方n号智能体),或者不采取任何行动。起初每个智能体有 3 点生命值,如果智能体在敌人的攻击范围内被攻击到了,则会扣 1 生命值,生命值掉为 0 则死亡,最后存活的队伍获胜。每个智能体的攻击有一轮的冷却时间。
本次实验旨在验证多智能体ppo,所以设置双方智能体为4.
2.实验代码
mappo训练代码选用github上 light-mappo 项目代码这是一个轻量化的mappo算法
下载代码后将ma_env放进项目根目录下,修改env_core.py代码如下
import timeimport numpy as npfrom ma_gym.envs.combat.combat import Combat
class EnvCore(object):"""# 环境中的智能体"""def __init__(self):self.agent_num = 4 # 设置智能体(小飞机)的个数,这里设置为两个 # set the number of agents(aircrafts), here set to twoteam_size = self.agent_numgrid_size = (15, 15)self.env = Combat(grid_shape=grid_size, n_agents=team_size, n_opponents=team_size)self.obs_dim = 150 # 设置智能体的观测维度 # set the observation dimension of agentsself.action_dim = self.env.action_space[0].n # 设置智能体的动作维度,这里假定为一个五个维度的 # set the action dimension of agents, here set to a five-dimensionaldef reset(self):s = self.env.reset()sub_agent_obs = []for i in range(self.agent_num):sub_obs = np.array(s[i])#np.random.random(size=(14,))sub_agent_obs.append(sub_obs)return sub_agent_obsdef step(self, actions):self.env.render("human")time.sleep(0.4)sub_agent_obs = []sub_agent_reward = []sub_agent_done = []sub_agent_info = []action_index = [int(np.where(act==1)[0][0]) for act in actions]next_s, r, done, info = self.env.step(action_index)for i in range(self.agent_num):# r[agent_i] + 100 if info['win'] else r[agent_i] - 0.1sub_agent_obs.append(np.array(next_s[i]))sub_agent_reward.append([r[i] + 100 if info['win'] else r[i] - 0.1])sub_agent_done.append(done[i])sub_agent_info.append(info)return [sub_agent_obs, sub_agent_reward, sub_agent_done, sub_agent_info]
3.实验设置
保持其他参数一致,分别设置四个智能体工艺同一套网络参数和4套网络参数进行实验。 旨在观察同一套参数控制同构智能体和不同参数控制同构智能体有什么不同。
4.实验结果
不同网络参数下智能体收敛曲线:
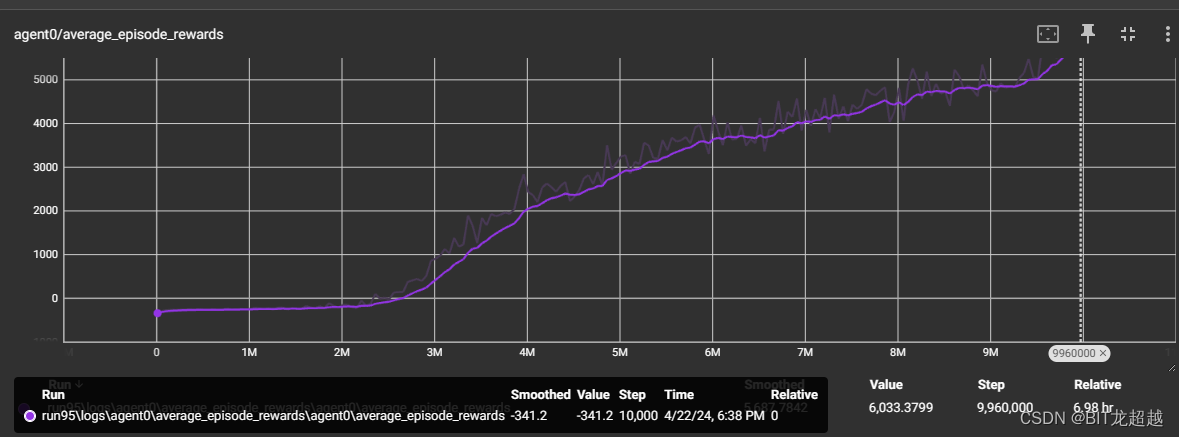
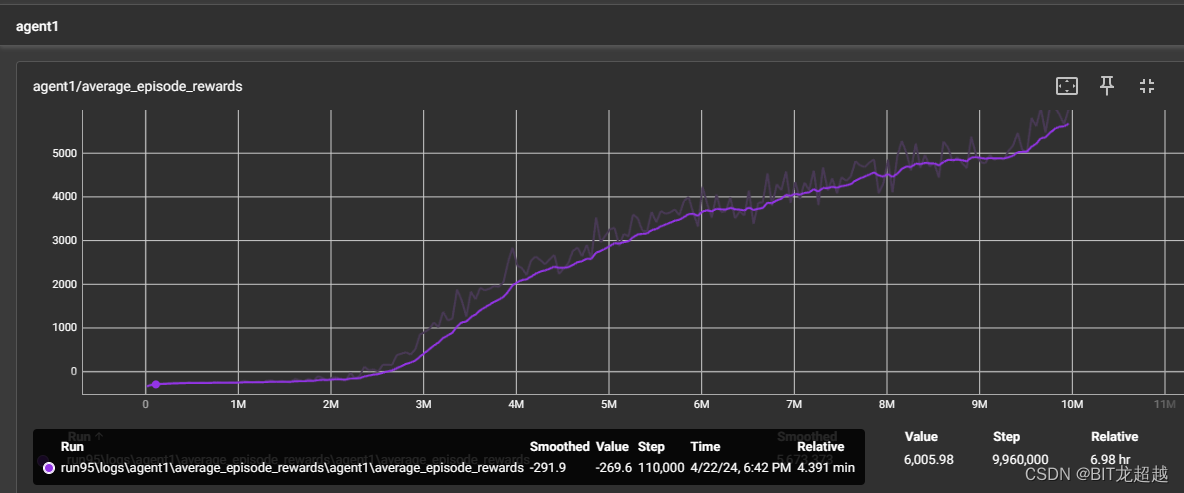
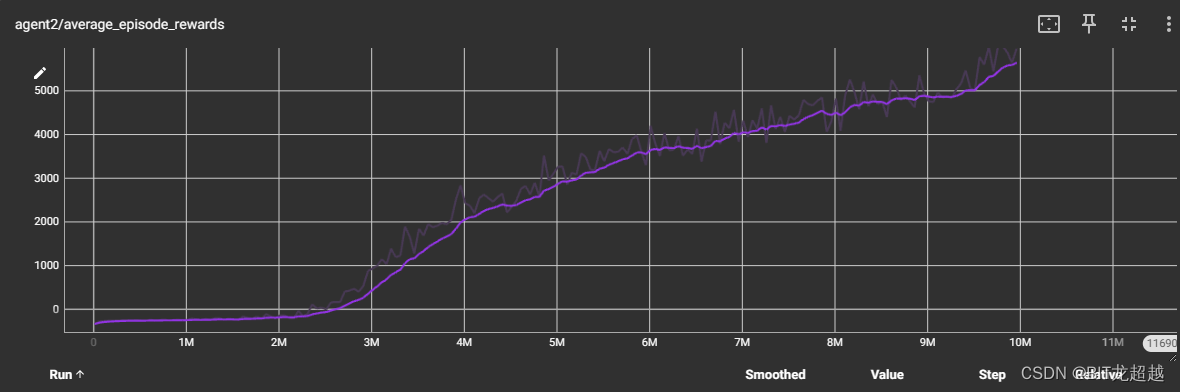
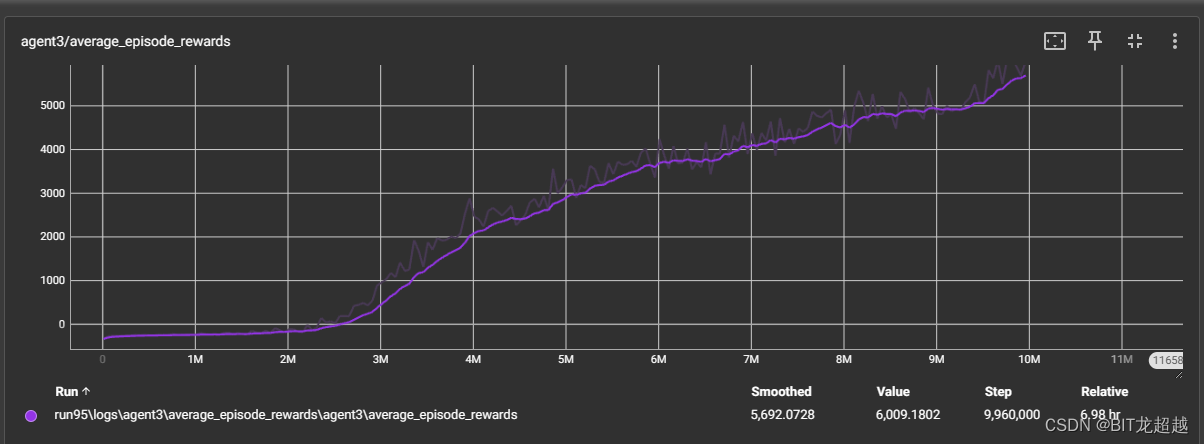
采用相同 网络参属下智能体收敛情况
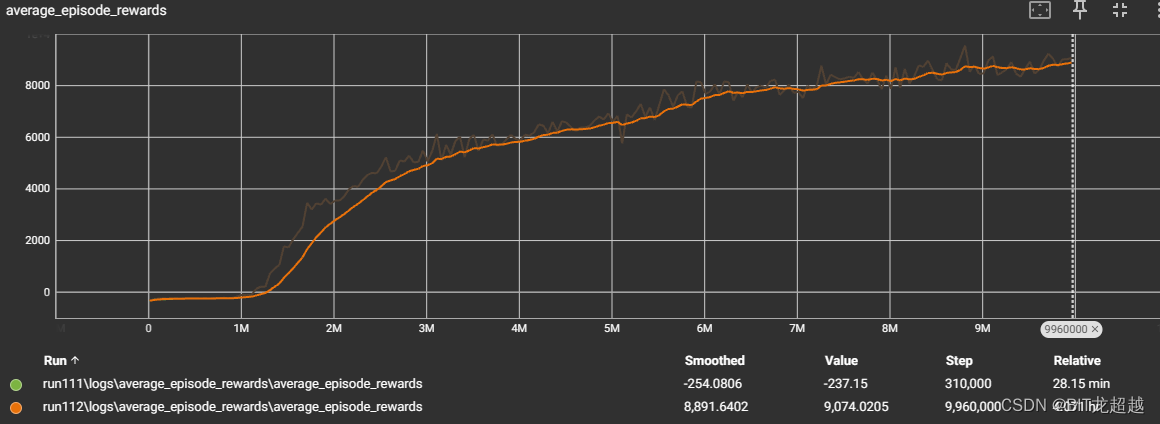
由上图比较得,其他条件相同下,采用同一模型的多智能体和采用不同模型的多智能体都能正常收敛, 采用同一模型的多智能体收敛速度和程度略高于采用不同模型的智能体
5.效果demo
MAPPO 算法训练多智能体联合对抗
这篇关于强化学习-MAPPO算法解析与实践-Multi Agent Proximal Policy Optimization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



