proximal专题
强化学习-MAPPO算法解析与实践-Multi Agent Proximal Policy Optimization
一 算法简介 mappo 是一种将ppo算法扩展到多智能体情况的算法,在讨论过这种算法的论文中,比较有名和权威的是Nips2021上发表的《The Surprising Effectiveness of PPO in Cooperative》。比较遗憾的是,可能作者出于自己不是最早提出mappo算法的人的原因,论文中并没有将mappo算法的具体实现作详细介绍(而最早提出mappo
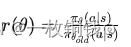
Proximal Policy Optimization (PPO)
Proximal Policy Optimization (PPO) 是一种先进的策略梯度方法,由 OpenAI 在 2017 年提出,目的是提高样本效率和训练过程的稳定性,特别适用于处理动态变化的环境,如网络环境中的自适应控制问题。PPO 成功地解决了早期策略梯度方法中的一些关键问题,尤其是在执行策略更新时保持稳定性的问题。 1. 核心思想 PPO 旨在通过限制策略更新的大小来平衡探索和利用
13、近端策略优化Proximal Policy Optimization (PPO) 算法:从原理到实践
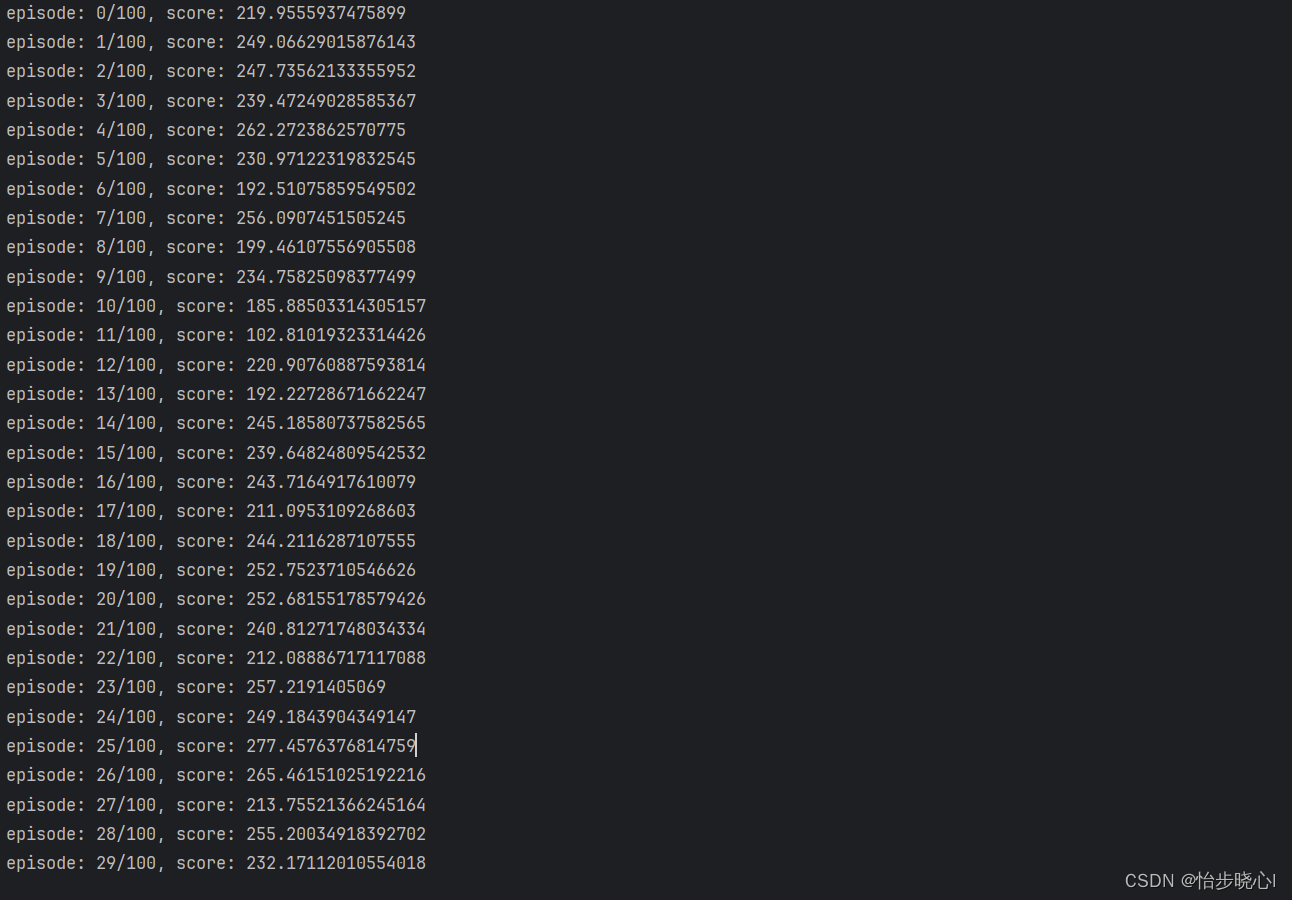
基于LunarLander登陆器的PPO强化学习(含PYTHON工程) PPO对标的是TRPO算法,改进了其性能。也有学者认为其理论性不强,但实践效果往往不错。 TRPO的缺点: 无法处理大参数矩阵:尽管使用了共轭梯度法,TRPO仍然难以处理大的 Fisher矩阵,即使它们不需要求逆近似值可能会违反KL约束,从而导致分析得出的步长过大,超出限制要求我们不能利用一阶随机梯度优化器,例如ADAM

First Order Methods in Optimization Ch6. The Proximal Operator
第六章: 临近算子 文章目录 第六章: 临近算子1. 定义、存在性和唯一性2. 临近映射的例子2.1 常值函数2.2 仿射函数2.3 凸二次函数2.4 一维的例子 3. 临近运算法则3.1 临近计算小结 4. 指示函数的prox--正交投影4.1 第一投影定理4.2 R n \mathbb{R}^n Rn中的例子4.3 到超平面与盒型区域之交上的投影4.4 到水平集上的正交投影4.5 到

【论文阅读】强化学习—近端策略优化算法(Proximal Policy Optimization Algorithms, PPO)
(一)Title 写在前面: 本文介绍PPO优化方法及其一些公式的推导。原文中作者给出了三种优化方法,其中第三种是第一种的拓展,这两种使用广泛,且效果好,第二种方法在实验中验证效果不好,但也算一个trick,作者也在文中进行了分析。 (二)Abstract 深度强化学习在训练过程中难以避免效果容易发生退化并且很难恢复这类问题,导致训练不稳定。自然策略梯度[1](NPG,Natural