mappo专题
强化学习-MAPPO算法解析与实践-Multi Agent Proximal Policy Optimization
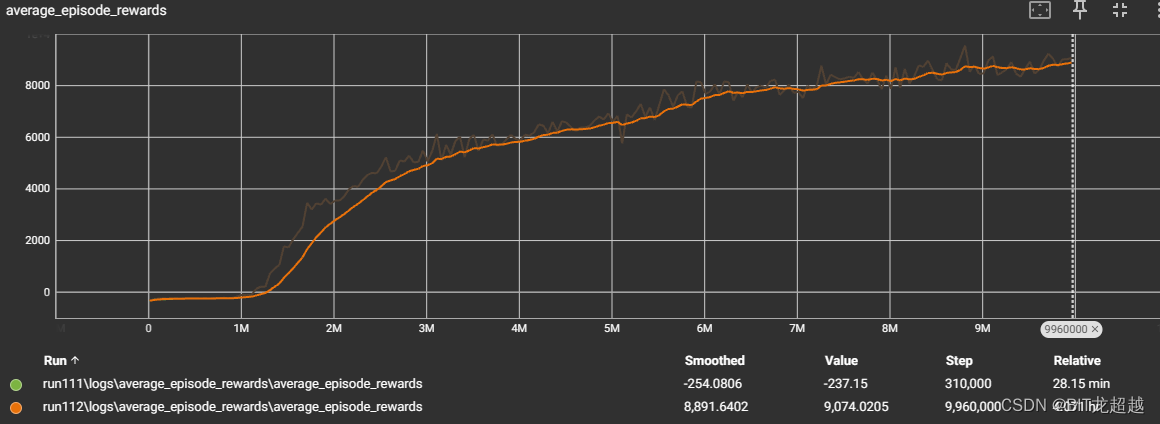
一 算法简介 mappo 是一种将ppo算法扩展到多智能体情况的算法,在讨论过这种算法的论文中,比较有名和权威的是Nips2021上发表的《The Surprising Effectiveness of PPO in Cooperative》。比较遗憾的是,可能作者出于自己不是最早提出mappo算法的人的原因,论文中并没有将mappo算法的具体实现作详细介绍(而最早提出mappo

多智能体强化学习--MAPPO(pytorch代码详解)
标题 代码详解Actor和Critic网络的设置 代码详解 代码链接(点击跳转) Actor和Critic网络的设置 基本设置:3个智能体、每个智能体观测空间18维。Actor网络:实例化一个actor对象,input-size是18Critic网络:实例化一个Critic对象,input-size是18x3=54在choose_action调用actor网络的时候,传入