本文主要是介绍hdfs balancer -policy,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
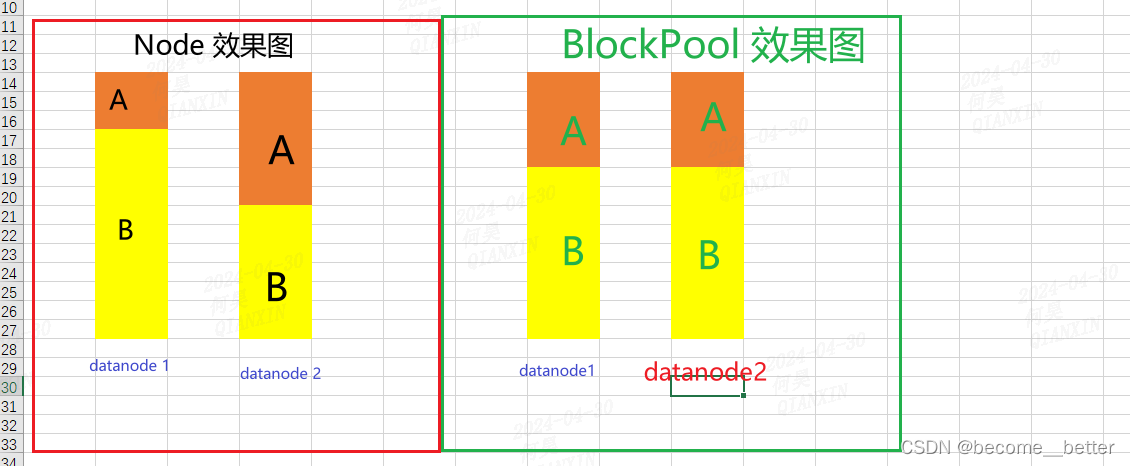
hdfs balancer -policy当前有两种,datanode(默认):如果每个数据节点是平衡的,则集群是平衡的。blockpool:如果每个datanode中的每个块池都是平衡的,则集群是平衡的。
代码区别:计算方式不同,一个使用datanode 的使用量,一个使用自己blockpool的使用量。

理想效果
这篇关于hdfs balancer -policy的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









